
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- grefcoco dataset
- grefcoco
- res paper
- google summer of code
- 에지 검출
- clip adapter
- 기계학습
- 엔트로피란
- 객체 검출
- 1차 미분 마스크
- blip-2
- 논문 요약
- mobilenetv1
- 딥러닝 목적함수
- gres
- gsoc
- gsoc 지원
- 원격 학습 안끊기게
- clip
- Object detection article
- gsoc가 뭔가요
- res
- vlm
- referring expression segmentation
- gsoc 2025
- object detection
- 딥러닝 엔트로피
- 논문 리뷰
- 이미지 필터링
- gsoc 후기
Archives
- Today
- Total
My Vision, Computer Vision
[논문 요약/리뷰] DINOv2: Learning Robust Visual Features without Supervision 본문
Paper
[논문 요약/리뷰] DINOv2: Learning Robust Visual Features without Supervision
gyuilLim 2025. 3. 31. 14:39DINOv2: Learning Robust Visual Features without Supervision
The recent breakthroughs in natural language processing for model pretraining on large quantities of data have opened the way for similar foundation models in computer vision. These models could greatly simplify the use of images in any system by producing
arxiv.org
Author : MLAOquab, Maxime, et al.
Journal : Arxiv
Keyword : dinov2
Published Date : 2023년 4월 14일
Introduction
- NLP에서 많은 양의 데이터로 Pre-training한 모델은 Fine-tuning 없이도 다른 Task에 잘 작동한다는 것이 입증되었다.
- 이 논문에서는 Computer vision 에서도 충분히 많은, 잘 선별된 데이터로부터 Self-supervised 방식으로 Pre-training 하는 방법 또한 좋은 특징을 만들어낼 수 있다는 것이다.
Problem
- CLIP 등 기존의 Text-guided Pre-training 에서 캡션은 이미지의 풍부한 정보를 단순히 근사하는 것이기 때문에 정보를 많이 유지하기 어렵다.
- Image-Text pair로 학습하는 Text-guided Pre-training의 대안은 이미지 만으로 학습하는 Self-supervised Pre-trianing이다.
- 하지만 기존 Self-supervised 학습은 ImageNet-1K등 작은 데이터셋에서만 진행되었고, 스케일을 확장시키려는 연구가 있긴했지만, 이는 비선별 데이터에 초점이 맞춰져있었기 때문에 추출되는 특징의 퀄리티를 오히려 감소시켰다.
- 본 연구에서는 많은 양의 선별된 데이터로부터 Self-supervised 방식으로 사전 학습하는 방법이 범용적인(General-purpose) 시각적 특징을 학습한다는 것에 대해 탐구한다.
- 논문에서 지적한 기존 방법들의 한계
- Intra-image self supervised training : 이 방법으로 학습된 피쳐는 다른 Task에 적용하기 위한 Supervised fine-tuning이 필요하다.
- Discriminative self-supervised learning : 모델 크기를 더 확장시키기 어렵다.
Data Processing
- Data sources : ImageNet-22k, ImageNet-1K, Google Landmarks, Fine-grained 등 다양한 선별된(Curated) 데이터셋과 웹으로부터 수집한 비선별 데이터셋(Uncurated)에서 Post-processing 과정을 거친다.
- Deduplication : 기존의 중복 검출 파이프라인을 사용하여 비선별 데이터로부터 중복 데이터를 제거한다.
- Self-supervised image retrieval : 마지막으로 비선별 데이터로부터 선별 데이터들과 유사한 이미지들만 추출해온다. 유사도 계산에는 ViT-H/16의 이미지 임베딩과 코사인 유사도가 사용된다.
- LVD-142M : 이렇게 만들어진 데이터셋은 총 1억 4천 2백만개이며 V100(32GB) GPU가 8개로 약 2일정도 걸린다고 한다.
Discriminative Self-supervised Pre-training
- 본 연구에서 사용하는 방법론(DINO, iBOT)은 선행 연구 DINO(Emerging Properties in Self-Supervised Vision Transformers), iBOT(iBOT: Image BERT Pre-Training with Online Tokenizer)로부터 고안되었다.
Image-level objective
- 이 Objective는 학생 모델과 교사 모델로부터 추출된 각각의 피쳐에 Cross-entropy를 적용하여 분포를 일치시킨다.
- 먼저 학생 모델로부터 추출된 Class token은 학생 DINO head에 입력되고 “Prototype scores”라고 부르는 Score vector $p_s$로 만들어진다. 마찬가지로 교사 모델로부터 또 다른 “Prototype scores” $p_t$도 만들어진다.
- 최종적으로 DINO loss는 아래와 같이 계산된다.
$$ \mathcal L_{DINO} = - \sum p_t \mathrm \log p_s $$
Patch-level objective
- 이 Objective는 패치 단위로 계산된다. 기존 연구의 방법론인 iBOT head를 사용한다.
- 학생 모델의 입력 패치 중 랜덤으로 특정 부분을 마스킹하고, 마스크에 해당하는 토큰을 iBOT head의 입력으로 넣는다.
- 교사 모델의 경우, 학생 모델에서 마스킹 된 부분을 보이게(마스킹하지 않고) 한 채로 계산된 패치 토큰을 iBOT head의 입력으로 넣는다.
- 최종적으로 iBOT loss는 아래와 같이 계산된다.
$$ \mathcal L_{iBOT} = -p_{ti}\log p_{si} $$
- $i$는 마스킹된 토큰의 패치 인덱스이다.
Untying head weights between both objectives
- DINO와 iBOT은 각가 다른 Head를 사용하고 있는데, 원래 선행 연구에서는 동일한 Head를 사용하는 것이 성능이 더 높다고 보여졌다.
- 하지만 스케일을 확장하고 다시 적용해보니 반대의 결과가 나타나서, 결국 DINO와 iBOT은 각각 다른 Head를 사용한다.
Sinkhorn-Knopp centerting
- 교사 네트워크에 Softmax 대신 적용되는 방법론이다.
- 특성 벡터의 분포를 조정하고, 출력을 정규화할 때 사용하는 방법이다.
- 자세한 사항은 논문 참고(Unsupervised learning of visual features by contrasting cluster assignments)
KoLeo regularizer
- 이 방법은 Kozachenko-Leonenko 엔트로피 추정기를 기반으로 하는, 배치 내 데이터 포인트들이 고르게 분포하도록 도와주는 방법이다.
- 주어진 $n$개의 벡터 집합($x_1, \dots , x_n)$에서 유도되며 수식은 아래와 같다.
$$ \mathcal L_{koleo} = -\frac{1}{N}\sum^n_{i=1} \log (d_{n,i}) $$
- $d_{n,i}=\min_{j \ne i} ||x_i - x_j||$로, $x_i$로부터 가장 가까운 샘플$x_j$ 와의 거리이다.
- 이 값을 최소화하면, 데이터 포인트들이 너무 가깝지 않게, 고르게 분포되도록 조정한다.
Adapting the resolution
- Image resolution을 증가시키는 것은 저해상도에서 작은 객체가 사라지게 되는 Segmentation, object detection에서 중요하다.
- 하지만 High resolution은 높은 시간과 메모리를 요구하기 때문에, 여기서는 Pre-training의 마지막 짧은 주기 동안 이미지의 해상도를 518*518로 증가시켜 훈련한다.
Efficient implementation
- 그 외에도 훈련 효율을 위해 여러가지 방법을 도입한다.
- Fast and memory-efficient attention.
- Sequence packing.
- Efficient stochastic depth.
- Fully-Sharded Data Parallel.
- Model distillation
Experiment
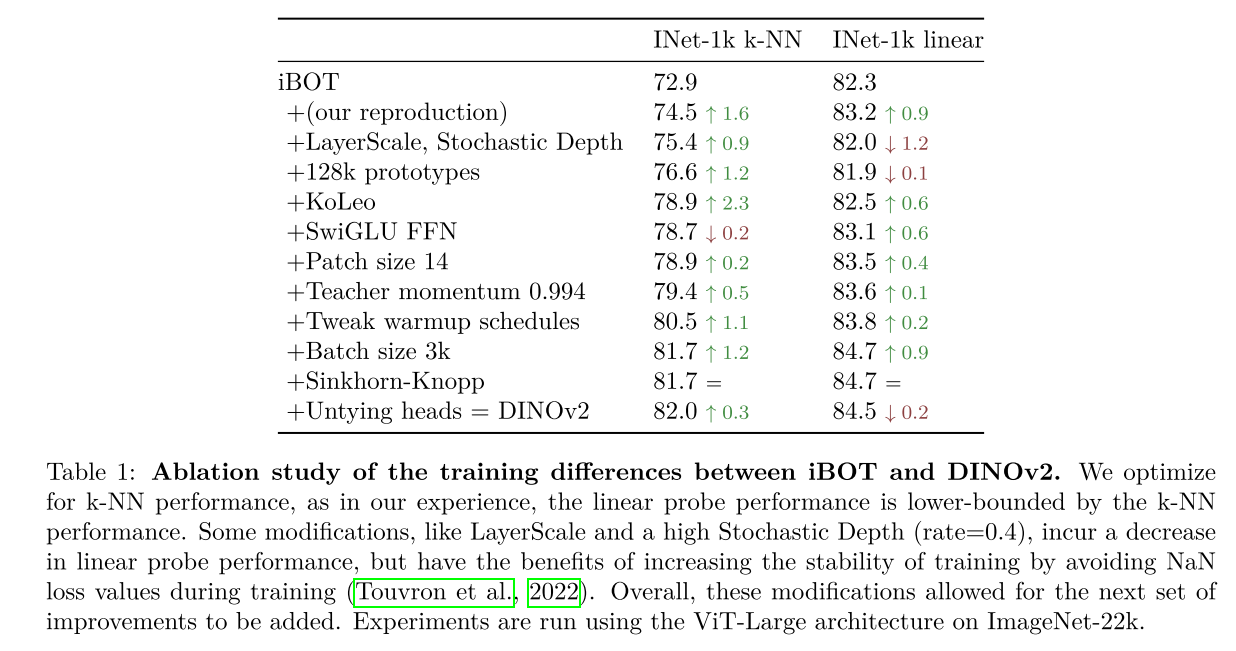
- Training recipe에 대한 Ablation study이다.
- KoLeo에서 가장 큰 성능 향상이 있었고, Reproduction, Prototypes, Tweak warmup schedules, Batch size 에서도 1% 가량 성능 향상이 있었다.
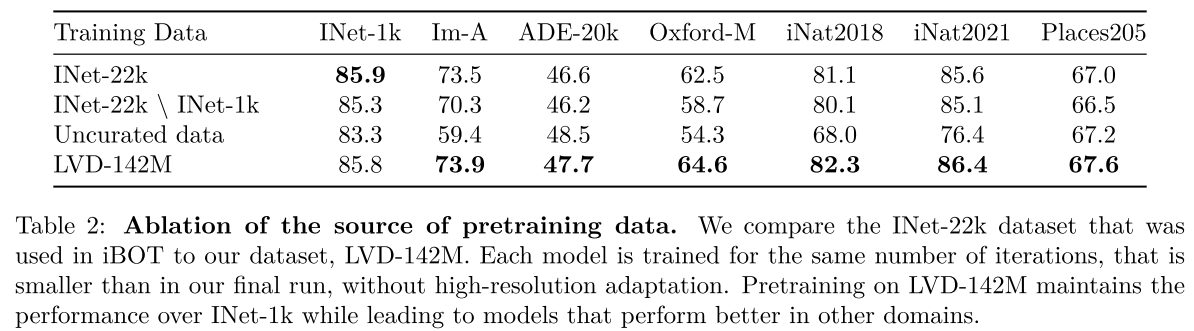
- Pre-training dataset에 대한 Ablation study이다.
- 모든 데이터셋에 대해 같은 Iteration을 학습한 결과, LVD-142M에서 성능이 가장 좋았다.

- ImageNet-22k, LVD-142M 데이터셋에 대해 ViT-L, H, g의 결과를 나타낸 그래프이다.
- 전반적으로 모델의 크기가 클 수록 성능이 증가하고, LVD-142M에서 학습된 모델이 ImageNet-22k에서 학습된 모델을 능가한다.

- ImageNet-1k에 대한 Zero-shot 벤치마크이다.
- LVD-142M에서 학습된 ViT-g/14 모델인 DINOv2가 가장 성능이 높다.
Conclusion
- Large curated dataset에서 Self-supervision으로 학습된 이미지 인코더를 사용하는 DINOv2를 제안한다.
- DINOv2는 Fine-tuning 없이도 기존의 Weakly supervised 모델과의 성능 격차를 좁힌 최초의 SSL 모델이다.
728x90
'Paper' 카테고리의 다른 글
'Paper' Related Articles
more



