
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- mobilenetv1
- 원격 학습 안끊기게
- referring expression segmentation
- clip
- grefcoco
- res
- 객체 검출
- clip adapter
- 이미지 필터링
- gsoc
- 딥러닝 엔트로피
- google summer of code
- res paper
- gsoc 후기
- E2E 자율주행
- 에지 검출
- vlm
- gsoc 2025
- grefcoco dataset
- 딥러닝 목적함수
- Object detection article
- transfuser++
- 1차 미분 마스크
- TransFuser
- 논문 요약
- gres
- 엔트로피란
- 논문 리뷰
- object detection
- blip-2
- Today
- Total
My Vision, Computer Vision
[논문 요약/리뷰] DoRA: Weight-Decomposed Low-Rank Adaptation 본문
DoRA: Weight-Decomposed Low-Rank Adaptation
Among the widely used parameter-efficient fine-tuning (PEFT) methods, LoRA and its variants have gained considerable popularity because of avoiding additional inference costs. However, there still often exists an accuracy gap between these methods and full
arxiv.org
Author : Liu, Shih-Yang, et al.
Journal : ICML 2024
Keyword : DoRA
Published Date : 2024년 2월 14일
Problem & Introduction

- Parameter-Efficient Fine-Tuning 방법에서 LoRA 계열의 인기가 많아지고 있는데, 여전히 Full Fine-tuning(FT)와의 성능 차이는 여전히 존재한다.
- 이 차이는 일반적으로 제한된 학습 파라미터 수 때문이라고 여겨지지만, 원인에 대한 근본적인 탐색은 충분히 이루어지지 않았다.
- 본 연구에서는 LoRA와 FT 간 본질적인 차이를 분석하고, FT의 학습 능력을 모방하기 위한 새로운 방법론 DoRA(Weight-Decomposed Low-Rank Adaptation)을 제안한다.
- DoRA를 적용하면 LoRA의 학습 능력과 안정성을 향상시키면서도 추가적인 추론 비용을 발생시키지 않는다.
Recent Methods’ Problem
- Adapter, Prompt 기반 방법들은 원래 모델에 추가적인 네트워크가 붙기때문에 추론 단계에서 속도가 감소하는 단점이 있다.
- LoRA 계열 방법들은 추론 단계에서의 속도가 감소되지 않는다는 장점이 있고, 최근 활발하게 연구되고있다.
- 본 연구에서는 LoRA와 다르게 가중치를 크기와 방향 요소로 분해하여, FT와 유사한 형태로 학습되는 것을 입증한다.
Contributions
- 가중치 분해(Weight-Decomposition)를 활용한 새로운 PEFT 방법 DoRA를 제안한다.
- FT와 다른 PEFT 방법 간 학습 패턴에서의 차이를 분석하기 위해 새로운 가중치 분해를 도입한다.
- DoRA는 NLP부터 Vision-Language 벤치마크까지 다양한 태스크에서 LoRA를 능가하는 성능을 보였다.
Methods
Analysis Method
- 가중치를 크기와 방향에 따라 어떻게 업데이트되는지를 조사하여 LoRA와 FT 가중치 간 학습 양상의 근본적인 차이를 조사한다.
- 가중치 $W \in \mathbb R^{d\times k}$ 는 아래와 같이 크기(Magnitude, $m$)와 방향(Direction, $\frac{V}{||V||_c}$)으로 분해할 수 있다.
$$ W = m \frac{V}{||V||_C} = ||W||_c \frac{W}{||W||_c} $$
- 가중치 분해(Weight Decomposition) 분석을 위해 네 가지 Image-Text Task로 파인튜닝된 VL-BERT 모델을 활용한다.
- 이 때, 사전학습된 가중치()와 Full Fine-tuning된 가중치(), LoRA 파인튜닝 가중치를 아래와 같이 나타낼 수 있다.
$$ \Delta M_t = \sum^k_{n=1}|m^{FT}{n, t} - m{n,0}| $$
$$ \Delta D_t = \sum^K_{n=1}(1-\cos(V^{FT}{n,t}, W{n,0})) $$
- $\Delta M^{FT}t$와 $\Delta D^{FT}_t$ 각각 $W_0$와 $W{FT}$ 간의 크기 차이와 방향 차이를 나타낸다.
- 방향 차이는 $1-cos(V^{FT}{n,t}, W{n,0})$ 두 벡터가 유사할수록 0, 다를수록 1에 가까워진다.
- $W_{LoRA}$도 위와 유사하게 나타낼 수 있다.
- 네 가지 태스크에서 파인튜닝되는 VL-BART에서, $\Delta M$과 $\Delta D$의 변화 양상을 관찰한다.
Analysis Results

- (a)와 (b)는 FT와 LoRA의 쿼리 가중치 행렬의 변화 차이를 보여준다.
- 가로 축은 $\Delta D$, 세로축은 $\Delta M$ 이다. 기울기가 양수이면, 두 변화량은 양의 상관관계를 가지며, 비례 관계로 해석할 수 있다.
- 기울기가 음수이면, 음의 상관관계로, 한쪽의 변화가 커지면 한쪽이 작아지는 반비례 관계로 해석할 수 있다.
- LoRA의 그래프를 보면, 전체적으로 일관되게 양의 기울기로 측정된다.
- 반면에 FT 그래프는, 다양한 패턴을 보여주면서 음의 기울기로 측정된다.
- 이는 LoRA가 Fine-tuning 능력이 부족하다는 것으로 해석할 수 있다.
Weight-Decomposed Low-Rank Adaptation
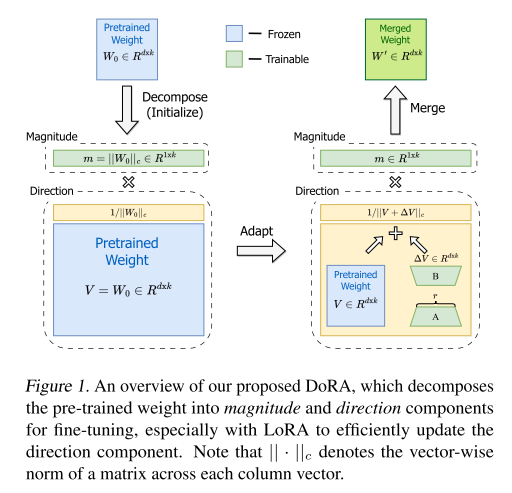
- 위에서 언급했던 것 처럼, DoRA를 사용하기위해 사전학습 가중치($W_0$)로 초기화하고 크기 성분과 방향 성분으로 분해한 후, 두 성분 다 학습은 하되 방향 성분에만 LoRA를 적용한다.
$$ W' = \underline m \frac{V + \Delta V}{||V+\Delta V||_c} = \underline m \frac{W_0+\underline {BA}}{||W_0 + \underline {BA}||_c} $$
- 밑줄 친 파라미터는 학습 가능한 파라미터를 나타낸다.
$$ W = m \frac{V}{||V||_C} = ||W||_c \frac{W}{||W||_c} $$
- 위 식을 다시 가지고와서 보면, 가중치 벡터 $W$의 크기 성분은 $||W||_c$로, 방향 성분은 가중치를 크기로 나누어 단위벡터인 $\frac{W}{||W||_c}$로 나타낸다.
- 방향 성분은 $W$ 에 $\frac{1}{||W||_c}$ 가 곱해져있는 형태로 볼 수 있다.
- Figure 2.의 (c)에서 DoRA는 FT와 유사하게 음의 기울기를 보인다.
- 저자는 이 양상을 두고, 사전 학습된 가중치가 이미 Downstream task에 적합한 지식을 갖추고 있기때문에 크기나 방향의 변화만으로도 적응이 충분히 가능할 것이라고 설명한다.
Reduction of Training Overhead
- 훈련 시 메모리 사용량을 줄이기 위해 $||V+\Delta V||_c$ 를 상수$C$ 로 취급한다.
- $V' = ||V+\Delta V||_c$라고 하면 아래와 같다.
$$ \triangledown_{V' \mathcal L} = \frac{m}{C} \triangledown_{W' \mathcal L}, ; \mathrm{where} ; C=||V'||_c $$
- 따라서 DoRA를 수식으로 다시 나타내면 아래와 같다.
$$ W' = m\frac{W_0 + BA}{C} $$
- 이 방법은 추가적인 역전파 수행 시 그래디언트 그래프 메모리 사용량을 감소시키지만, 정확도는 크게 차이가 없다.
Experiment
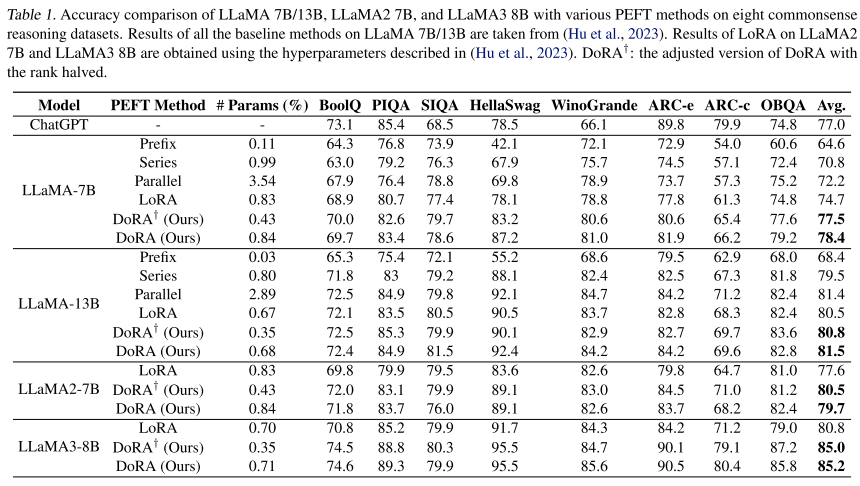
- 위 테이블은 Commonsense Reasoning에 대한 8개의 벤치마크이다.
- DoRA는 다양한 PEFT 방법들과 비교했을 때 좋은 성능을 보여준다.
- LLaMA-7B 모델에서는 LoRA보다 3.7% 증가했고, ChatGPT(3.5 Turbo API)보다 높다.
- LLaMA-13B에서는 Parallel Adapter가 LoRA보다 높게 측정됐고, DoRA와 비슷하지만, Trainable Parameter는 훨씬 적다.
- LLaMA2-7B, LLaMA3-8B 모델에서는 DoRA가 LoRA보다 각각 2.1%, 4.4% 높다.
- DoRA에 십자가가 붙은 모델은 랭크를 절반으로 설정했을 때이다.
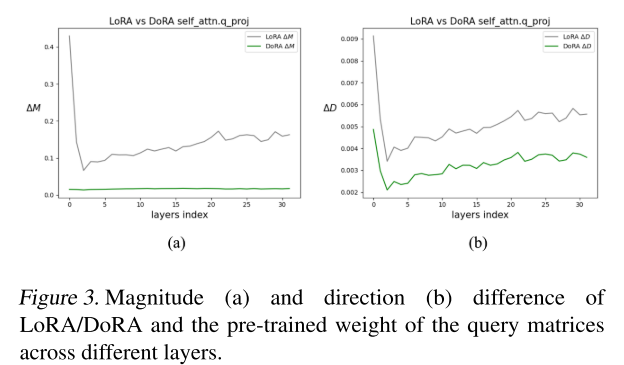
- 위 그래프는 $\Delta M, \Delta D$ 의 상관관계에 대한 가설을 입증한다.
- LLaMA2-7B 모델을 각각 LoRA, DoRA로 파인튜닝한 후 사전학습 가중치와 비교하여 $\Delta M, \Delta D$ 의 차이를 측정한 것이다.
- DoRA의 차이가 더 작은 것을 확인할 수 있다.
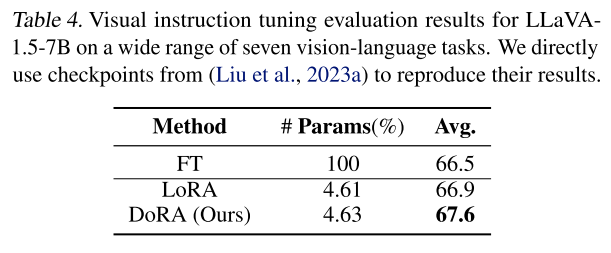
- Visual instruction tuning에서 LLaVA-1.5-7B 모델을 7개 Task에서 평균 성능을 측정한 것이다.
- DoRA, LoRA 모두 FT에 비해 약 4.6%의 파라미터로 학습이된다.
- DoRA가 LoRA에 비해 0.02% 정도 더 많은 파라미터가 있는데, 이는 크기 성분($m \in \mathbb R^{1*k}$)이다.

- Rank r에 대한 Albation Sutdy이다.
- r이 작을 때(4, 8)는 DoRA가 LoRA에 비해 성능 향상 폭이 크고, r이 커질수록 성능 향상 폭이 작아진다.
- r이 커질수록 FT이 가까워지게 되어 차이가 줄어드는 것으로 생각된다.
Conclusion
- 이 연구에서는 LoRA와 FT의 학습 양상 차이를 분석하고 새로운 파인튜닝 방법 DoRA를 제안한다.
- 또한 DoRA는 추론 단계에서 추가적인 지연(Latency) 없이 사전학습된 가중치에 크기와 방향 성분을 통합할 수 있다.



