
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- clip adapter
- 원격 학습 안끊기게
- gsoc 2025
- 논문 리뷰
- res paper
- gsoc 후기
- blip-2
- 객체 검출
- 딥러닝 목적함수
- 1차 미분 마스크
- transfuser++
- vlm
- google summer of code
- 에지 검출
- Object detection article
- 이미지 필터링
- res
- object detection
- gsoc
- gres
- 논문 요약
- clip
- referring expression segmentation
- mobilenetv1
- grefcoco dataset
- E2E 자율주행
- TransFuser
- grefcoco
- 엔트로피란
- 딥러닝 엔트로피
- Today
- Total
My Vision, Computer Vision
[논문 요약/리뷰] FuseMix: Data-Efficient Multimodal Fusion on a Single GPU 본문
[논문 요약/리뷰] FuseMix: Data-Efficient Multimodal Fusion on a Single GPU
gyuilLim 2025. 3. 7. 16:41
Data-Efficient Multimodal Fusion on a Single GPU
The goal of multimodal alignment is to learn a single latent space that is shared between multimodal inputs. The most powerful models in this space have been trained using massive datasets of paired inputs and large-scale computational resources, making th
arxiv.org
Journal: CVPR 20204
Published Date: 2023년 12월 15일
Keyword: Single GPU, Vision Language Model
Introduction
- 멀티모달의 목표는 여러 모달리티들을 하나의 Latent space로 융합하는 것이다.
- 대부분 성능이 좋은 멀티모달 모델은 데이터셋, 연산 자원 등 훈련에 엄청나게 많은 비용이 들어간다.
- 하지만 논문의 저자들은 사전학습된 Unimodal 모델도 이미 충분한 정보를 가지고 있기 때문에, 대량의 데이터로 From scratch 학습을 하지 않아도 된다고 말한다.
Contributions
- CLIP에 비해 600배 적은 연산, 80배 적은 데이터셋으로 모델을 학습시켜 CLIP을 능가하는 성능을 보여준다.
- Latent space에서 수행되는 Plug-and-Play 방식 Mixup기반 Multimodal Augmentation “FuseMix”를 제안한다.
Mixup이란?
- Mixup은 두 개의 이미지를 합치는 증강이다.

- 이런식으로 래서판다, 코알라 이미지가 있으면 두 이미지를 일정 비율로 합쳐버리는 것이 Mixup이다.
- 이 두 개의 이미지-라벨 쌍을 $(x,l)$, $(\hat x, \hat l)$ 라고 할 때, Mixup 후 결과는 아래와 같이 나타낼 수 있다.
$$ \tilde x \triangleq \lambda x + (1-\lambda) \hat x \\ \tilde l \triangleq \lambda l + (1-\lambda) \hat l $$
- 이미지와 마찬가지로 라벨도 $\lambda$ 의 비율로 합쳐진다.
Methods
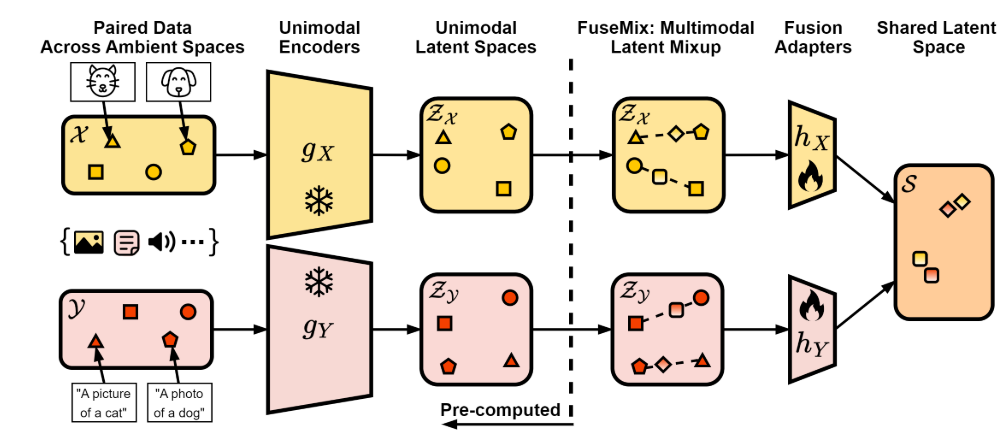
- 위 이미지는 논문에서 제안하는 모델의 아키텍쳐이다.
- 우선 두 개의 Frozen Unimodal Encdoer $g_X, g_Y$ 가 있다. 각각 Image encoder, Text encoder이다.
- 이 인코더들은 이미지 $\mathcal X$, 텍스트 $\mathcal Y$ 를 각각 Latent space $\mathcal Z_{\mathcal X}, \mathcal Z_{\mathcal Y}$ 로 매핑한다.
- 그리고 FuseMix를 적용한 후 Fusion Adapter $h_X, h_Y$를 거쳐 Shared Latent Space $S$ 에 매핑한다.
Computational Improvements
- 학습 과정에서, 인코더들은 이미 사전학습이 되어 Frozen 상태이기 때문에, 역전파에 관여하지 않는다.
- 따라서 $\mathcal Z_{\mathcal X}, \mathcal Z_{\mathcal Y}$ 까지(위 이미지에서 점선)는 사전에 계산해놓는 것이 가능하다.
- 즉 학습 중에는 Unimodal 인코더를 완전히 제거할 수 있는 것이고, 메모리 절약이 가능하다.
- 실제로 이 논문의 저자들은 이 모델을 하나의 GPU로만 학습한다.
Paired Data Efficiency
- Unimodal Encoder들은 학습에 관여하지 않기때문에, 학습되는 네트워크는 Fusion Adapter 부분만 남는다.
- 즉 학습되는 네트워크의 크기가 훨씬 감소되었기 때문에, 기존 Large-scale Multimodal 모델만큼 학습 데이터가 많이 필요하지 않게된다.
- 이 논문에서는 학습에 5M(5백만)개의 데이터셋을 사용한다(CLIP은 400M개).
Plug-and-Play Framework
- 이 방식은 인코더 뿐만 아니라 모달리티에도 독립적인(agnostic) 방식으로 설계되었다.
- 이미지 인코더를 오디오 인코더로 변경하면 오디오-텍스트 모달리티에도 적용이 가능한 것이다.
FuseMix: Multimodal Latent Mixup
- FuseMix는 모달리티, 인코더의 종류에 관계없이 적용할 수 있는 간단한 데이터 증강 기법이다.
- 하지만 Contrastive objective로 학습되기 때문에, Postive와 Negative 샘플이 있다.
- 따라서 두 개의 배치를 가져와서 융합한다.
$$ (z_x, z_y) \triangleq (g_X(x), g_Y(y)) \\ (\hat z_x, \hat z_y) \triangleq (g_X(\hat x), g_Y(\hat y)) \\ (\hat z_x, \hat z_y) \triangleq \lambda (z_x, z_y) + (1-\lambda)(\hat z_x, \hat z_y) $$
- 첫번째 배치$(x,y)$와 두번째 배치$(\hat x, \hat y)$를 Latent space로 매핑한 후, Mixup을 수행한다.
- 이 때 $\lambda$는 베타 분포에서 샘플링된다.
- FuseMix를 알고리즘으로 나타내면 아래와 같다.
# h X, h Y: learnable fusion adapters
# B: batch size
# D x, D y: latent dimension of unimodal encoders
# D s: latent dimension of shared space
# alpha: mixup Beta distribution hyperparameter
# t: learnable temperature parameter
# load latent pairs of batch size 2B
for z x,z y in loader: # (2B x D x, 2B x D y)
# FuseMix
z x1, z x2 = torch.chunk(z x, 2) # B x D x
z y1, z y2 = torch.chunk(z y, 2) # B x D y
lam = random.beta(alpha, alpha)
z x = lam * z x1 + (1 - lam) * z x2
z y = lam * z y1 + (1 - lam) * z y2
# joint space and normalize
s x = l2 normalize(h X(z x), dim=1) # B x D s
s y = l2 normalize(h Y(z y), dim=1) # B x D s
# pairwise cosine similarity w/ temperature
logits xy = (s x @ s y.T) * t.exp() # B x B
logits yx = (s y @ s x.T) * t.exp() # B x B
# symmetric alignment loss
labels = torch.arange(B)
loss xy = cross entropy loss(logits xy, labels)
loss yx = cross entropy loss(logits yx, labels)
loss = (loss xy + loss yx) / 2
# optimize
optimizer.zero grad()
loss.backward()
optimizer.step()Implementation Details
- 단일 32GB NVIDIA V100 GPU 사용한다.
- Fusion Adapter는 경량화된 MLP를 사용한다.
- 배치 사이즈 B = 20K.
- 데이터셋은 COCO, Visual Genome, SBU, CC3M을 합쳐 총 5M개의 데이터 사용.
Experiments

- 위 테이블은 Retrieval 벤치마크이다.
- 두 부분으로 나눴는데, Internet-scale은 인터넷에서 수집된 대용량 데이터로 학습된 모델, low-data regime은 상대적으로 소규모 데이터로 학습된 모델이다.
- FuseMix에 붙어있는 첨자는 이미지 인코더와 텍스트 인코더를 의미한다.
- D : DINOv2
- U : UNICOM
- B : BGE
- E : E5
- DINOv2와 BGE를 사용한 조합의 성능이 가장 좋다.
- low-data regime에 있는 CLIP은 CC3M으로만 학습된 모델이다.
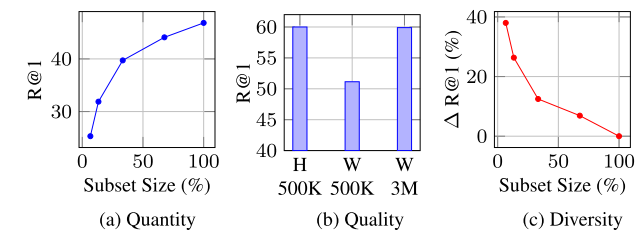
- (a)는 데이터의 크기가 커질수록, 성능 향상 폭이 작아진다는 것을 보여준다. 즉 데이터의 크기를 키우는 것은 어느 시점 이후로 비효율적이라는 것이다.
- (b)에서 H는 Human, W는 Web로, 각각 인간이 작성한 어노테이션과 웹에서 수집한 어노테이션을 말한다. 즉 웹 어노테이션이 인간 어노테이션과 비슷하기 위해 데이터가 약 6배정도 더 필요하다는 것이다.
- (c)는 데이터의 크기가 제한적일 때, 이미지-텍스트 쌍을 균일하게 샘플링(100%)하는 것보다 다양하게 샘플링하는 것이 더 향상된다는 것을 보여준다.

- (a)는 모델 사이즈에 따른 성능을 나타낸다. 모델이 커질수록(Small→Base→Large) 성능이 증가한다.
- (b)는 배치 사이즈에 따른 성능을 나타낸다. 배치 사이즈가 커질수록 성능이 증가한다.
- (c)는 데이터 증강 기법의 효과인데, GN은 Gaussian noise, RQ는 Random quantization이다.
Conclusion
- 이 연구는 계산, 데이터 면에서 효율적인 멀티모달 융합 프레임워크 FuseMix를 제안한다.
- 향후 단일 모달 인코더에 대한 파인튜닝을 적용할 수 있으며, API를 통해 접근 가능한 인코더로도 융합을 수행할 수 있다.
Review
- 사전학습된 인코더에 데이터를 미리 계산해놓고 실제 학습에서 사용하지 않는 부분이 참신했다.
- 하지만 저자들도 말했듯이 파인튜닝에 대한 한계가 존재한다.
- 또한 네트워크 뒷부분에 LLM을 붙이는 등의 확장성이 제한되어있다.



