
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- 1차 미분 마스크
- object detection
- google summer of code
- gsoc 2025
- gsoc
- TransFuser
- res paper
- 논문 요약
- gres
- grefcoco dataset
- 딥러닝 엔트로피
- 논문 리뷰
- transfuser++
- 에지 검출
- 이미지 필터링
- 원격 학습 안끊기게
- gsoc 후기
- 엔트로피란
- mobilenetv1
- referring expression segmentation
- Object detection article
- clip adapter
- 객체 검출
- grefcoco
- res
- clip
- 딥러닝 목적함수
- E2E 자율주행
- blip-2
- vlm
Archives
- Today
- Total
My Vision, Computer Vision
[논문 리뷰/요약] Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs 본문
Paper
[논문 리뷰/요약] Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
gyuilLim 2024. 4. 26. 20:04
Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
We revisit large kernel design in modern convolutional neural networks (CNNs). Inspired by recent advances in vision transformers (ViTs), in this paper, we demonstrate that using a few large convolutional kernels instead of a stack of small kernels could b
arxiv.org
- 이 논문은 2022년 3월 CVPR에서 발표되었다.
Abstract
- 이 논문은 ViT(Vision Transformer)에서 영감을 받았다.
- CNN 모델에서 작은 커널을 깊게 쌓는 구조 대신 큰 커널을 사용하는 구조가 더 좋은 패러다임이 될 수 있다고 보았다.
- 넓고 깊은 커널에 depth-wise, re-pramaterized 기법을 적용하여 효율적이고 high-performence의 large kernel을 구현했다.
- 커널의 크기가 크기때문에, RepLKNet(Reparam Large Kernel Net, 본 논문 제시 모델)은 큰 ERF(Effective Receptive Filed)를 가진다.
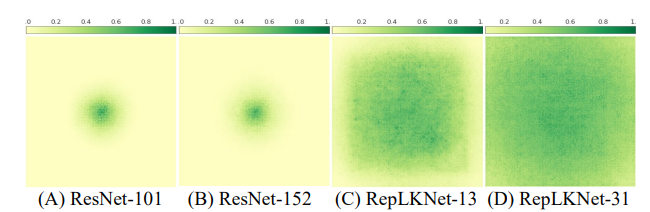
배경 지식
1. Re-parameterization 기법
- Re-parameterization이란 학습할 때 여러 branch로 나누어져있던 kernel을 infrence time에 합쳐서 계산하는 방법이다.

- Train의 경우 일반적은 Convolution 연산처럼 $l+1$의 출력은 $ f_{l+1} = f_l * w_{3*3} + f_l * w_{1*1} $로 계산된다.
- Inference의 경우 $l+1$의 출력은 $f_{l+1} = f_l * (w_{3*3} + w_{1*1})$로 대체된다.

- 위 그림과 같이 학습 동안은 3*3, 1*1 kernel을 따로 적용하지만 Inference의 경우 두 개의 커널을 더해준다.
- Inference동안 파라미터의 개수를 줄여줌으로써 크기와 시간을 줄여주는 것이 Re-parametrization 기법이다.
2. Texture bias vs Shape bias
- Texture bias(질감 편향) : 이미지 내에서 질감이나 패턴에 초점을 맞추는 경향. 전역적인 모양 정보를 파악하는데 어려움
- Shape bias(형태 편향) : 이미지 내에서 전역적인 형태나 윤곽에 초점을 맞추는 경향. 오브젝트의 크기, 모양 변화에 더 잘 대응할 수 있음
- 일반적으로 사람은 물체를 구분할 때 형태에 편향되어있는데, ViT도 마찬가지다. 반면 CNN은 질감 편향이 더 크다.
- 이 논문은 Large Kernel을 사용하여 CNN이 질감보다 형태에 편향되어 물체를 판단할 수 있도록 한 것이다.
1. Introduction
- CNN은 여러 분야에 널리 쓰였지만 더 강력한 ViT가 등장했다.
- 여러 연구진들은 downstream tesk에 ViT가 좋은 이유를 MHSA에서 꼽지만, 실제로 그럴까? 라는 의문을 제기
- MHSA(Multi Head Self Attention) - 하나의 이미지 내에서 여러개의 헤드로 피쳐간의 관계를 알아내는 것
- Large Kernel 혹은 큰 Receptive filed를 구축하는 것이 CNN과 ViT의 격차를 줄일 수 있을까? 에서 시작했다.
- RepLKNet(본 논문의 제시 모델)은 Swin transformer에서 MHSA를 Large Kernel로 대체한 모델이다.
2. Related Work
- 전, 현재 연구 모두, 커널의 크기가 커봤자 11*11이고, 더 큰 크기의 커널에 대해서는 다루지 않았다.
- 또한 CNN 모델의 지표(깊이, 너비, 입력 해상도, 보틀넥 비율…)에서 커널의 크기에 대한 건 간과되어있다.
- Re-parameterization 기법을 사용함으로써 매우 큰 커널이 small-scale patterns를 캡쳐할 수 있도록 하여 모델의 성능을 높인다.
3. Guidelines of Applying Large Convolutions
Guideline 1 : Large depth-wise convolutions can be efficient in practice
- Large kernel을 적용하게 되면 파라미터의 개수, 연산량이 증가할텐데, depth-wise convolution을 적용함으로써 증가량을 최대한 감소시켰다.

- Kernel size가 3-3-3-3인 경우와 31-29-27-13인 경우, FLOP이 ImageNet과 ADE20K에서 각각 18.6%, 10.4% 증가했다.
- 커널의 크기가 커진데에 비해 FLOP의 증가량은 합리적인 수준이다.
Depth-wise convolution에 대한 자세한 내용은 https://mvcv.tistory.com/22 참고
Guideline 2: identity shortcut is vital especially for networks with very large kernels.
- MobileNetV2에서 Shortcut의 유무, Kernel size에 대한 실험을 진행했는데, 결과는 아래와 같다.
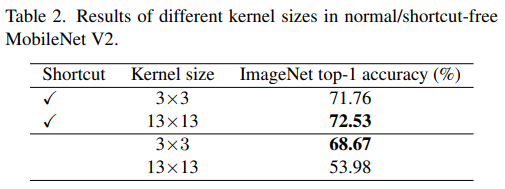
- 13*13 커널의 성능이 약 0.77% 향상되었고, Shortcut이 있을 때가 없을 때 보다 더 좋은 성능을 보여주었다.
- Shortcut은 다양한 receptive filed를 가진 여러 모델의 암묵적인 앙상블 효과를 냈다고 봤다.
Guidline 3 : re-parameterizing with small kernels helps to make up the optimization issue

- 위 그림은 Re-parameterizing을 표현한 그림이다.
- 7*7, 3*3, BN(Batch Norm)으로 이루어진 커널을 최종적으로 7*7 하나로 re-parameterizing한다.

- 위 테이블을 보면 3x3 커널을 9x9와 13x13으로 대체한 후 성능이 증가했고, re-param을 활용했을 때 더 증가하는 것을 확인할 수 있다.
Guideline 4 : Large convolutions boost downstream tasks much more than ImageNet classification
- Large convolutions은 downstream task에 유리하다.(segmentation → sementic segmentation)
- Imagenet(1,400만장, 224)보다 ADE20K(2만장, 512), Cityscapes(5천장, 1024x2048)과 같은 데이터셋에서 성능 향상폭이 더 크다.
- 첫번째 이유 : ERF를 증가시켰기 때문에, Input size가 더 큰 이미지에 유리한 것
- 두번째 이유 : Large Kernel 구조가 shape bias를 증가시켜주기 때문
- imagenet으로 훈련된 CNN모델은 texture에 편향되는데, 커널 크기를 키움으로써 shape bias를 증가시킨 것
4. RepLKNet: a Large-Kernel Architecture
- 현재까지는 작은 모델에서 CNN이, 복잡성이 더 높은 상황에서는 ViT가 좋은 성능을 보인다고 여겨졌다.
- 복잡성이 ResNet-152, 또는 Swin-B와 동등하거나 더 큰 모델에서 Large 커널 디자인이 CNN과 ViT간의 성능 격차를 줄일 수 있는지 확인하고자 한다.

- Stem : 시작 레이어
- Transition : 1*1을 통해 채널 수 증가, DW 3*3으로 다운 샘플링 진행
- Stages : RepLK Block과 ConvFFN으로 이루어짐
- 각 Stage는 세 개의 하이퍼 파라미터 B(RepLK 블록 개수), C(채널 크기), K(커널 크기)를 가진다.
- RepLK Block : shortcut 안에 BN layer, K size의 커널 위아래로 1*1 kernel이 있음
- ConvFFN : BN, GELU 사용(LN과 비교했을 때 BN의 장점은 Conv에 fuse 될 수 있다는 것)
4.1. Architecture Specification
- Hyper parameter = [Stage1, Stage2, Stage3, Stage4] 형식
- RepLKNet의 Base 모델인 RepLKNet-31B의 하이퍼 파라미터는 다음과 같다.
- B = [2, 2, 18, 2]
- K = [31, 29, 27, 13]
- C = [128, 256, 512, 1024]
- 대부분의 데이터셋에 대해 성능이 증가하고 Parameter의 개수와 FLOP은 감소했다.
5. Discussion
- ERF는 O(K√L)에 비례하기 때문에(K : kernel size, L : Layer) Receptive filed를 효율적으로 키우기 위해서는 Layer보다 Kernel size를 키워야한다.
- Layer 크기를 키우면 최적화 문제가 발생할 수 있다.
- 결론 : Lager Kernel은 큰 ERF를 얻기 위해 Layer를 많이 요구하지 않기 때문에 효율적으로 Receptive filed를 키울 수 있다.

- 위 그림은 사람과 모델의 Shape, Texture bias를 비교한 것이다.
- RepLKNet-31모델의 Shape bias가 가장 높고 RepLKNet-3모델과 ResNet152가 bias가 비슷하다.
Conclusion
- ERF를 늘리기 위해 층을 늘리기보다 Large Kernel을 사용하여 효율적으로 늘릴 수 있다.
- 특히 Downstream task에서 높은 성능 향상을 보여준다.
- ViT에서 MHSA의 동작 방식이 Large Convolution과 유사하기 때문에 이해하는데 도움이 될 수 있다.
728x90
'Paper' 카테고리의 다른 글
'Paper' Related Articles
more



