
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 원격 학습 안끊기게
- Object detection article
- transfuser++
- grefcoco dataset
- gsoc
- referring expression segmentation
- 1차 미분 마스크
- 딥러닝 목적함수
- res
- 딥러닝 엔트로피
- object detection
- blip-2
- TransFuser
- mobilenetv1
- gsoc 2025
- vlm
- 이미지 필터링
- E2E 자율주행
- grefcoco
- gres
- 엔트로피란
- 논문 리뷰
- gsoc 후기
- res paper
- 논문 요약
- clip
- clip adapter
- google summer of code
- 객체 검출
- 에지 검출
- Today
- Total
My Vision, Computer Vision
[논문 리뷰/요약]ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness 본문
[논문 리뷰/요약]ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness
gyuilLim 2024. 3. 25. 15:50ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness
Convolutional Neural Networks (CNNs) are commonly thought to recognise objects by learning increasingly complex representations of object shapes. Some recent studies suggest a more important role of image textures. We here put these conflicting hypotheses
arxiv.org

이 논문은 기존의 CNN 모델이 질감, 형태 중 무엇에 치우쳐져 판단하는지 연구하고 실험한다. 위 사진에서 (a)와 (b)는 각각 코끼리, 고양이라고 판단하지만 고양이 형태에 코끼리 질감을 씌운 이미지인 (c)는 코끼리라고 판단한다. 신기하기도 하고 재밌는 주제이기 때문에 읽어볼 만한 논문이다.
사람은 물체를 판단할 때 질감보다 형태에 집중한다. 위 (c)를 고양이라고 판단하는 것이다. 하지만 기존 모델들은 (c)를 코끼리라고 판단하는데, 이 논문의 저자들은 새로운 데이터셋으로 CNN을 학습시켜, 사람과 유사한 메커니즘으로 물체를 판단하게끔 만든다.
Abstract
- CNN은 주로 물체 모양의 복잡한 표현을 학습함으로써 물체를 인식한다고 여겨졌다.
- 이 논문의 저자들은 ImageNet으로 훈련된 CNN이 물체의 형태(shape)보다 질감(texture)을 인식하는데 강한 편향을 가진다는 것을 보여주었다.
- StylizedImageNet에서 훈련된 CNN은 Shape bias를 높게 만들 수 있었다.
1. Introduction

- CNN 레이어는 익숙한 물체의 일부를 인식하고 그 후 레이어에서는 일부분들의 조합으로 물체를 감지한다는 형태 가설이 있다.
- 예를 들면, 먼저 엣지와 같은 저수준 특징을 점차적으로 조합하여 바퀴, 창문 같은 형태를 만든 후 자동차로 분류할 수 있게 만드는 것이다.
- 지금까지 알려진 바로는 CNN 모델이 인간이 물체를 인식하는 방법처럼 형태에 초점을 맞추어 인식한다는 가설이 지지되었다. 즉 물체의 형태가 색깔, 질감보다 중요하다는 것이다.
- 반면에 일부 연구는 CNN의 물체 인식에 질감이 더 중요한 역할을 본다고한다. 예를 들어 형태의 구조가 파괴되어도 질감으로 물체를 인식할 수 있다는 것이다.
- 첫 번째 가정과 대조적으로 CNN에서 물체의 질감이 형태보다 더 중요하다는 가설도 고려해 볼 수 있는 것이다.
- 이를 실험하기 위해 스타일 전이를 이용하여 코끼리 질감의 고양이 형태같은 이미지를 만들어 낸 후 실험을 진행했다. 이를 통해 질감, 형태 편향을 정량화할 수 있었다.
2. Methods
2.1 PSYCHOPHYSICAL EXPERIMENTS
- 인간과 CNN을 대상으로 이미지 분류(Image classification) 실험을 진행했다.
- 고양이, 자동차, 의자 등 총 16개로 분류하는 실험을 진행했다.
2.2 DATA SETS(PSYCHOPHYSICS)
- 2.1절 실험에 사용된 데이터에 대한 설명이다.
- 이미지는 형태, 질감을 기준으로 6개로 분류된다.
- Original : 흰색 배경에 원본 물체가 있는 사진
- Gray scale : skimage를 이용하여 original을 gray scale로 변경
- Silhouette : original 이미지에서 물체만 검은색으로 변경
- Edges : matlab의 Canny 엣지에지 추출기를 이용해 에지로 표현
- Texture : 동물의 피부 훅은 털로 이루어져 있거나 물체를 반복하여 이미지를 채운 것
- Cue conflict : Texture 이미지와 Original 이미지를 합성한 이미지
Cue conflict(신호 충돌)란?

- 위 이미지들 처럼 주 객체의 형태는 유지하면서 다른 물체 혹은 동물의 질감을 덮어 씌운 이미지를 말한다.
- 형태와 질감이 일치하지 않고 충돌하기 때문에 Cue conflict라고 한다.
- 2번째, 3번째 이미지처럼 동물이 아닌 물체(시계, 유리병 등)는 여러 개 반복해 겹쳐놓은 식으로 질감을 표현했다.
2.3 STYLIZED-IMAGENET(SIN)
- ImageNet을 기반으로 구축된 Cue confilct 이미지 데이터셋
- 자세한 코드는 https://github.com/rgeirhos/texture-vs-shape 참고
3. RESULTS
3.1 TEXTURE VS SHAPE BIAS IN HUMANS AND IMAGENET-TRAINED CNNS
- Original, Gray scale : 형태와 질감을 온전히 가지고 있기 때문에 인간, CNN 모두 올바르게 분류
- Silhouette, Edges : 실루엣, 엣지 모두 CNN의 정확도가 낮았고 에지에서는 특히 더 낮았다.
- Texture : CNN모델이 인간보다 높은 성능을 보여주었다.
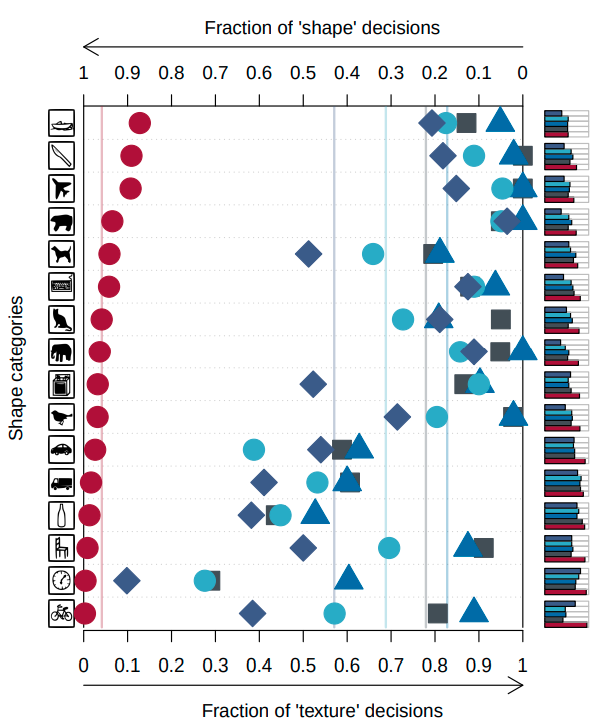
- 사람은 질감보다 형태에 편향되어 물체를 판단하는데 반해 CNN 대부분은 질감에 편향하여 물체를 판단한다.
3.2 OVERCOMING THE TEXTURE BIAS OF CNNS

- SIN으로 학습된 ResNet(주확생 사각형)은 사람과 유사하게 질감보다 형태에 편향되어 물체를 판단한다.
5. CONCLUSION
- CNN의 형태, 질감 편향에 대한 시각 제시
- 인간 시각의 객체 인식 모델로 나아가는 한 걸음
- 미래의 Domain knowledge에서 형태 기반 표현이 질감 기반 표현보다 유익할 것이라는 시작점 제공
'Paper' 카테고리의 다른 글
| [논문 리뷰/요약]MobileNetV2: Inverted Residuals and Linear Bottlenecks (1) | 2024.04.25 |
|---|---|
| [논문 리뷰/요약]MobileNetv1, MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications (0) | 2024.03.29 |
| [논문 리뷰/요약]Tiny Object Detection in Aerial Images (3) | 2024.03.25 |
| [논문 리뷰/요약]SSD: Single Shot MultiBox Detector (0) | 2024.02.22 |
| [논문 리뷰/요약]How to Read a Paper (0) | 2024.02.21 |



