
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 이미지 필터링
- gsoc 후기
- 딥러닝 엔트로피
- gres
- clip
- 원격 학습 안끊기게
- grefcoco
- reparameterization
- object detection
- 엔트로피란
- 논문 리뷰
- 에지 검출
- 딥러닝 목적함수
- Object detection article
- 객체 검출
- blip-2
- 기계학습
- 논문 요약
- 1차 미분 마스크
- referring expression segmentation
- grefcoco dataset
- Segmentation
- mobilenetv1
- gsoc
- res
- gsoc 2025
- res paper
- vlm
- google summer of code
- clip adapter
- Today
- Total
My Vision, Computer Vision
[논문 리뷰/요약]SSD: Single Shot MultiBox Detector 본문
SSD: Single Shot MultiBox Detector
We present a method for detecting objects in images using a single deep neural network. Our approach, named SSD, discretizes the output space of bounding boxes into a set of default boxes over different aspect ratios and scales per feature map location. At
arxiv.org
GitHub - sgrvinod/a-PyTorch-Tutorial-to-Object-Detection: SSD: Single Shot MultiBox Detector | a PyTorch Tutorial to Object Dete
SSD: Single Shot MultiBox Detector | a PyTorch Tutorial to Object Detection - sgrvinod/a-PyTorch-Tutorial-to-Object-Detection
github.com
SSD는 single-stage 중 처음으로 two-stage 모델의 정확도를 넘어선 detector이다. Single-stage이기 때문에 빠른 속도를 가지면서 높은 정확도를 달성한 것에 의의가 있다. 혁신적인 기술이 도입된 건 아니지만 기존의 아이디어들을 적절히 병합하여 좋은 성능의 모델을 만들어냈다. 이 논문은 모델의 전체적인 구조와 학습 방법에 대해 구체적으로 소개한다. 더 자세한 내용은 위 github을 참고하여 작성했다.
Abstract
SSD는 single deep neural network로 구성된 object detection 모델이다. Object proposal이 필요했던 기존 detection method와는 다르게, proposal generation, subsequent pixel, feature resampling stage를 완전히 제거한 구조이다. 따라서 학습이 쉽고, detection이 요구되는 시스템에 곧바로 적용할 수 있는 활용적인 측면이 있다. SSD는 300 * 300 크기의 input으로 VOC2007 test에서 74.3%의 mAP와 59 FPS를 달성했고, 512 * 512 input으로 76.9%의 mAP를 달성했다. 당시 SOTA를 달성했던 Fsater R-CNN을 능가하는 수치이다.
1. Introduction
기존의 object detection system들은 bounding box의 후보를 만들어내는 region proposal method와 feature map의 크기를 조절하는 단계가 있었다. 이런 방식은 기존 detector들이 대부분 사용할 만큼 만연한 방법이었다.
하지만 selective search등의 region proposal method는 정확한 만큼 계산량이 많고 시간이 오래 걸리는 문제가 있었다.
기존의 method로는 high-end 장비를 사용하더라도 여전히 real-time(실시간)의 속도는 달성하지 못했다.
정확도로 SOTA를 달성했던 Faster R-CNN 조차 7 FPS의 속도밖에 내지 못한 것이다.
결국 속도와 정확도 중 하나를 선택하거나 적절한 수준에서 타협해야 했다.
이 논문에서는 기존의 방식을 사용하지 않고도 기존만큼 정확한 method를 제시한다.
PASCAL VOC 2007 testset을 기준으로 SSD는 mAP 74.3%, 59 FPS를 달성했고 Faster R-CNN, YOLO는 각각 mAP 73.2%, 63.4%와 7 FPS, 45 FPS를 달성했다. 기존 방식에서 bounding box proposal, subsequent pixel, feature resampling 단계를 제거했기 때문에 속도를 향상할 수 있었다.
단순화된 구조를 제시한 논문은 이전에도 몇 가지 있었지만(YOLO 등) 앞서 말했듯 속도와 정확도는 trade-off 관계에 있기 때문에 구조를 단순화하면서 높은 정확도를 유지해야 하는 문제는 해결하지 못했다.
Faster R-CNN과 YOLO는 기존의 SOTA 모델이다. Faster R-CNN은 two-stage detector로, region proposal moethod를 사용하여 상대적으로 느리지만 정확하다는 특징이 있다. 반면 YOLO는 region proposal method를 사용하지 않아 single-stage 구조로 구현할 수 있었기에 빠르지만 정확도가 상대적으로 낮다.
이 논문에서 저자들이 말하는 SSD의 contribution은 5가지가 있는데, 다음과 같다.
- SSD는 single-shot detector로, YOLO보다 빠르고 Faster R-CNN보다 정확하다.
- 고정된 개수의 default box로부터 category score와 box offset을 예측한다.
- Detection의 정확도를 향상하기 위해 다양한 scale의 feature map을 prediction에 사용한다.
- 간단한 end-to-end 학습 구조로 구현했고 작은 해상도의 input image에서도 높은 정확도를 보여준다.
- PASCAL VOC, COCO, ILSVRC dataset에서 SOTA에 대적할만한 결과를 달성했다.
2. The Single Shot Detector(SSD)
2장은 SSD 모델의 전체적인 framework를 먼저 소개하고 손실 함수를 포함한 학습 방법에 대해 구체적으로 다룬다.
2.1 Model
SSD는 default box라고 하는 고정된 개수의 bounding box와 각 box에 대해 객체 존재 여부를 나타내는 점수(confidence score)를 출력한다. 이 점수를 기준으로 bounding box에 NMS(Non-Maximum Suppression)을 적용하여 최종 출력을 만들어낸다. SSD는 모두 convolution layer로 이루어져 있다. 우선 feature extraction을 담당하는 base network 뒤에 auxiliary structure라고 불리는 extra feature layer를 연결하여 추가적으로 feature map을 추출하는 구조이다.
Base network SSD는 VGG-16을 backbone network로 사용한다. VGG-16은 13개의 conv layer와 3개의 fc layer로 구성되어 있는데, 이 논문의 저자는 VGG-16에서 3개의 fc layer를 떼어내고 conv layer로 대체한 modified VGG-16을 base network라고 말한 것이다.
Multi-scale feature maps for detection SSD의 extra feature layer는 base network에서 추출된 low-level feature map의 scale을 감소시키고 고차원(high-level) 특징을 추출함으로써 multiple scale detection에 도움을 준다.
VGG-16
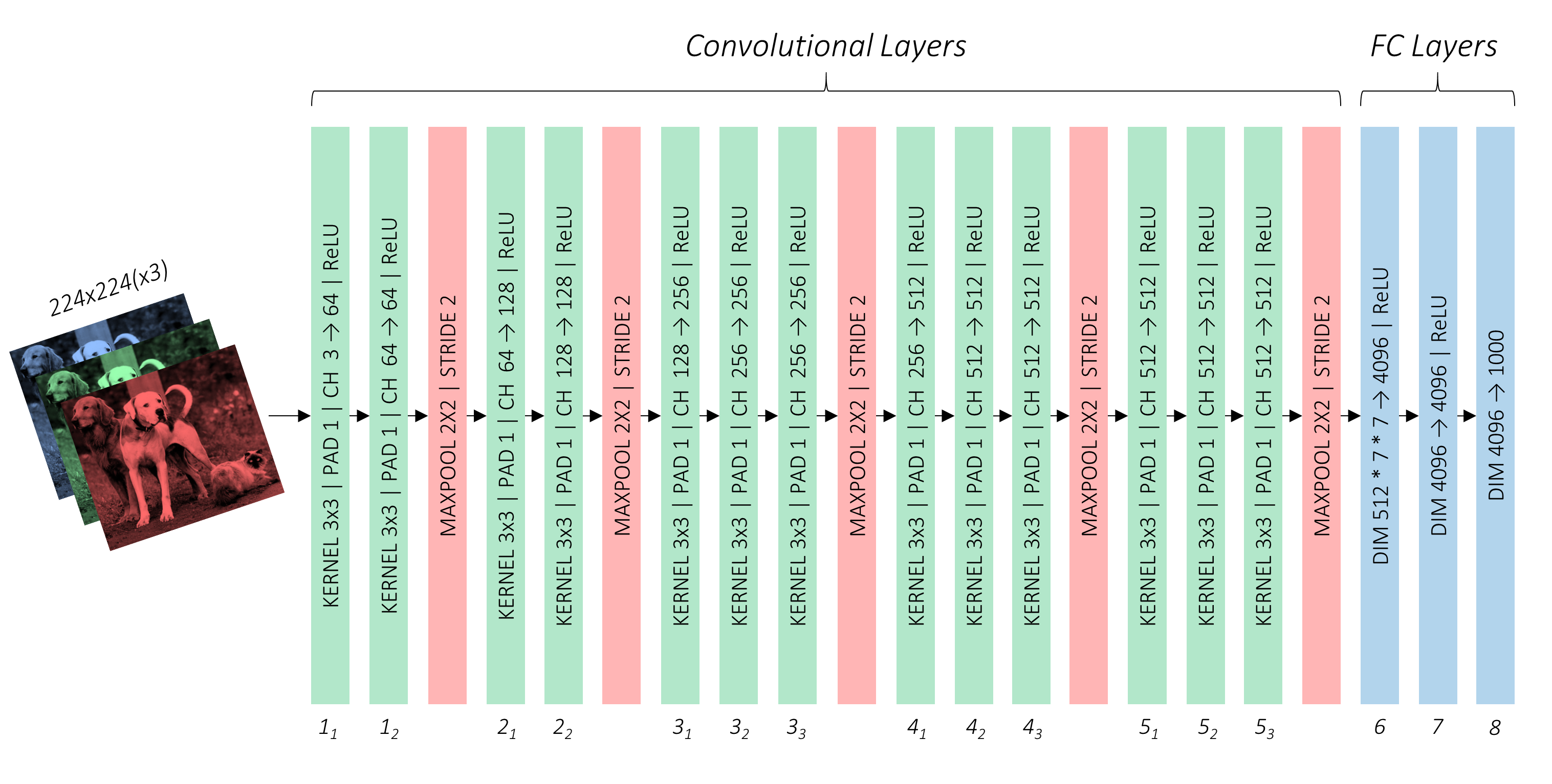
위 이미지는 VGG-16 네트워크를 나타낸 것이다. 초록, 빨강, 파랑은 각각 conv layer, pooling layer, fc layer를 의미한다.
Base network (modified VGG-16)
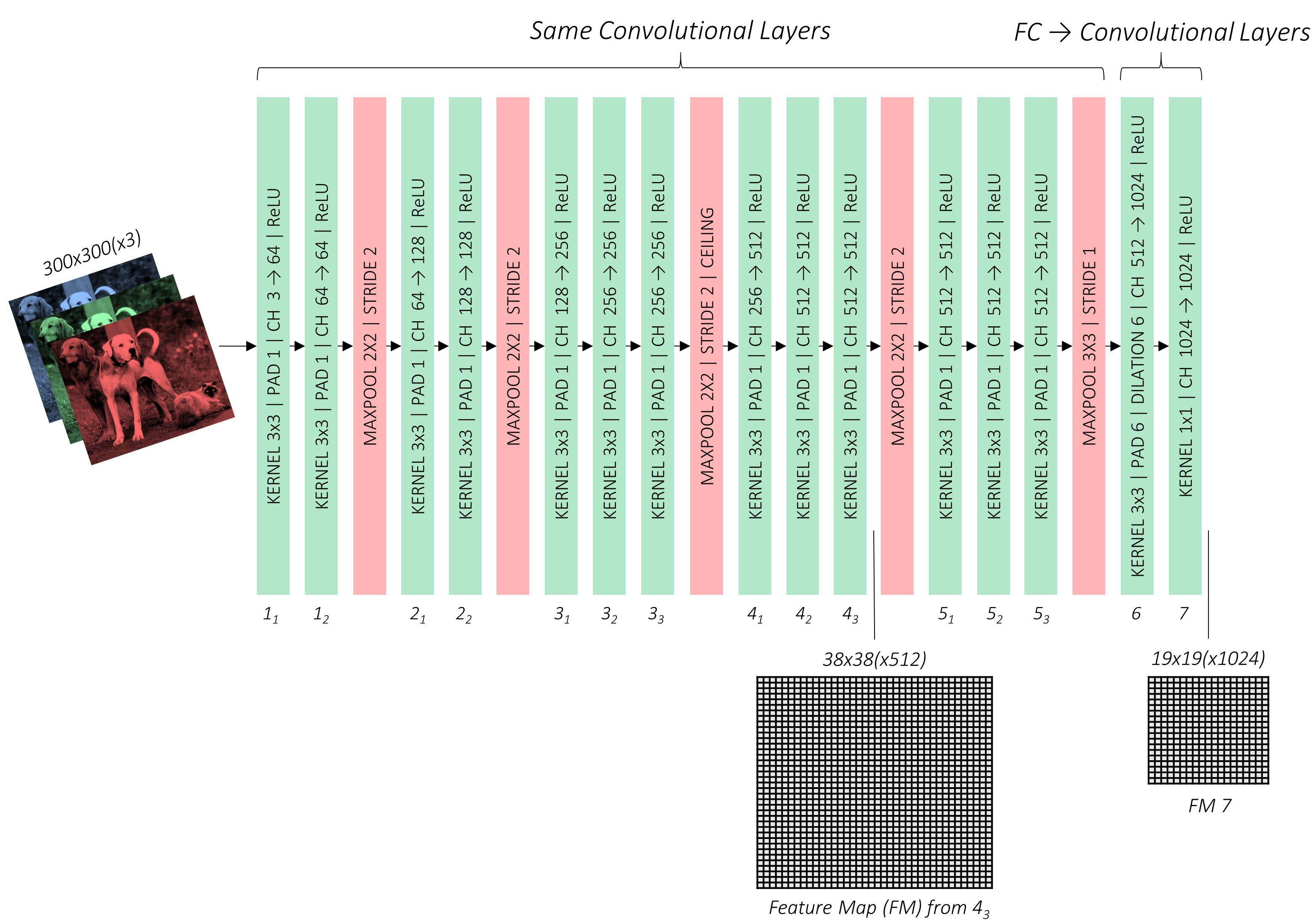
앞에서 설명한 것처럼, fc layer(파란색)를 떼어내고 conv layer로 교체한 base network(modified VGG-16)이다.
Extra Feature Layer (Auxiliary convolutional layers)
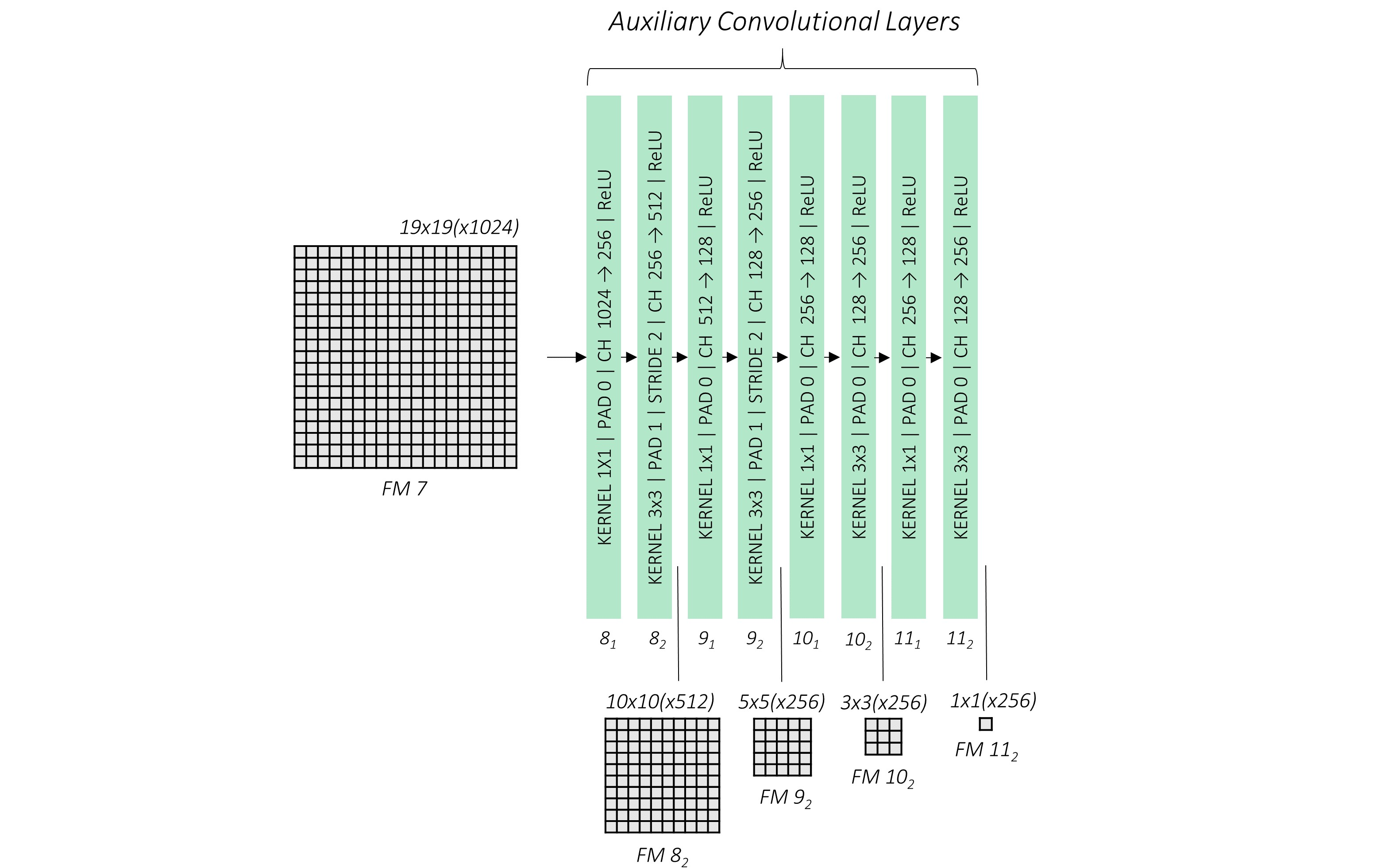
Base network 뒤에 연결되어 추가적으로 feature map을 추출하는 layer이다. 최종 prediction에 사용하는 feature map은 base network에서 2개(4_3, 7), extra feature layer에서 4개(8_2, 9_2, 10_2, 11_2) 추출되어 총 6개의 feature map이 사용된다. 네트워크 아래 그려진 사각형들이 각 단계에서 추출되는 feature map이다.
Convolutional predictors for detection. 위 단계에서 추출된 6개의 feature map은 모두 채널도 다르고 scale도 다르다. 이 절에서는 feature map들을 어떻게 모두 prediction에 사용하는지 소개한다.
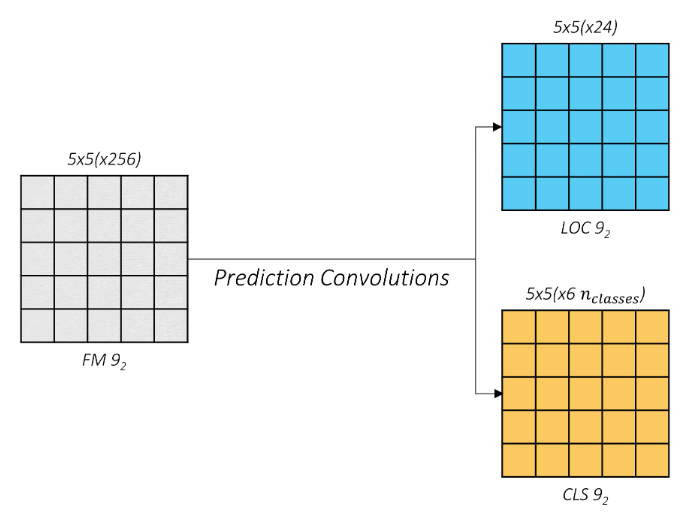
예를 들어 9_2번째 conv layer에서 추출된 feature map(위 그림에서 회색 사각형)이 있다고 해보자. 크기는 5 * 5이고 256개의 채널로 이루어진 256 * 5 * 5 feature map이다. 이때 24 * 256 * 3 * 3의 kernel과 (6 * N) * 256 * 5 * 5의 kernel을 각각 적용하여 24 * 5 * 5, (6 * N) * 5 * 5 크기로 변환한다. N은 class 개수를 의미하는데, 여기에서는 3개(cat, dog, background)로 예를 들어 설명한다.
위 부분에서 짚고 넘어가야 할 포인트는 ‘왜 파란색 사각형과 주황색 사각형의 채널을 각각 24, 6 * N으로 설정했는지’이다.
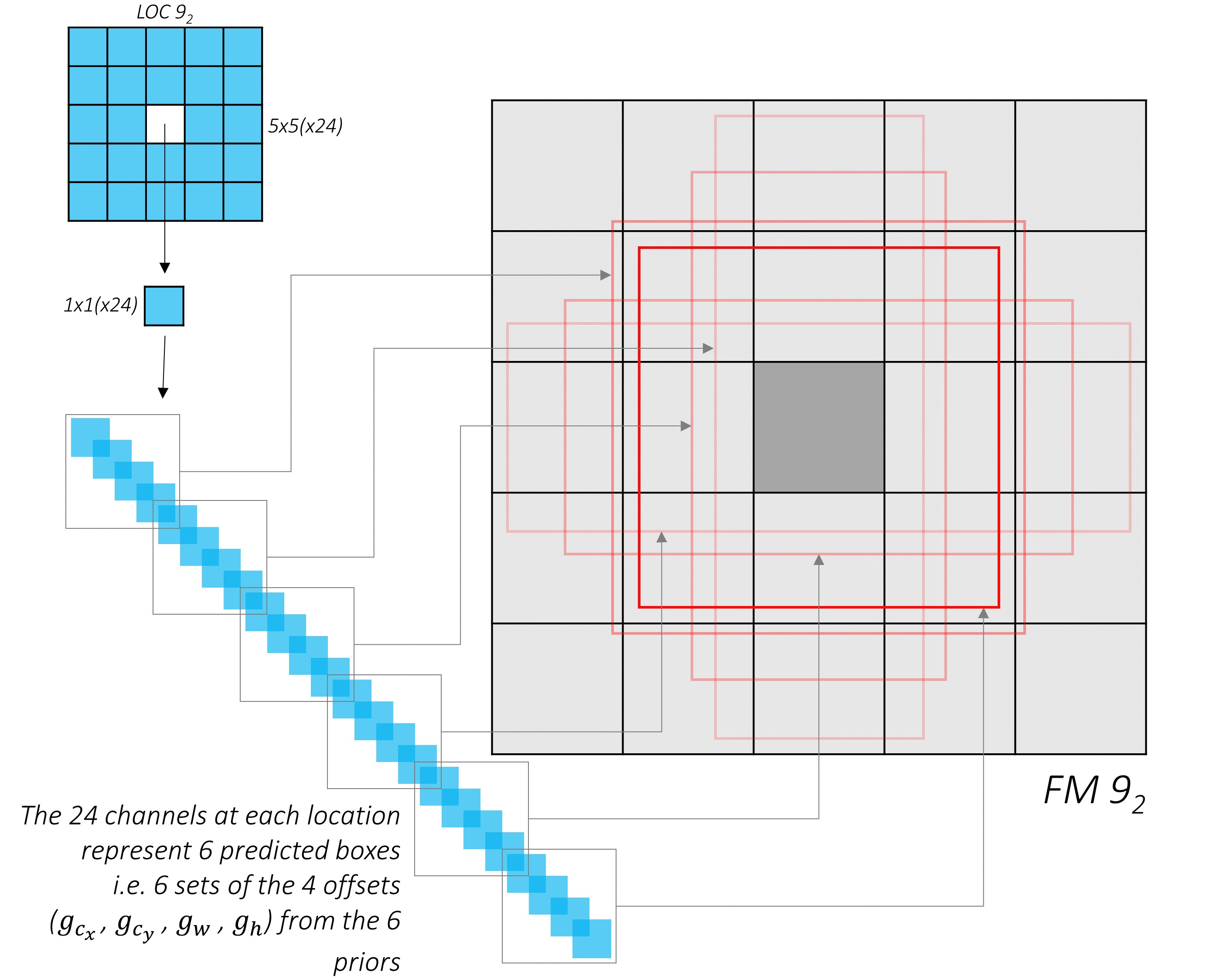
먼저 파란색 사각형을 살펴보자. 파란색 사각형의 크기는 24 * 5 * 5인데 가운데 한 칸을 떼와서 나타낸 것이 위 그림에서 길게 늘어뜨려진 부분이다. 총 25개의 칸이 있고 한 칸 당 6개의 default box가 만들어진다. default box는 중심점(x, y)과 너비(w), 높이(h)로 표현된다. 즉 위 그림은 25개의 칸 중 가운데 칸에서 만들어지는 default box(6개) 각각의 좌표(4개)를 나타내는 것이다. Output 채널 수를 24(6 * 4)로 한 이유가 이것이다.
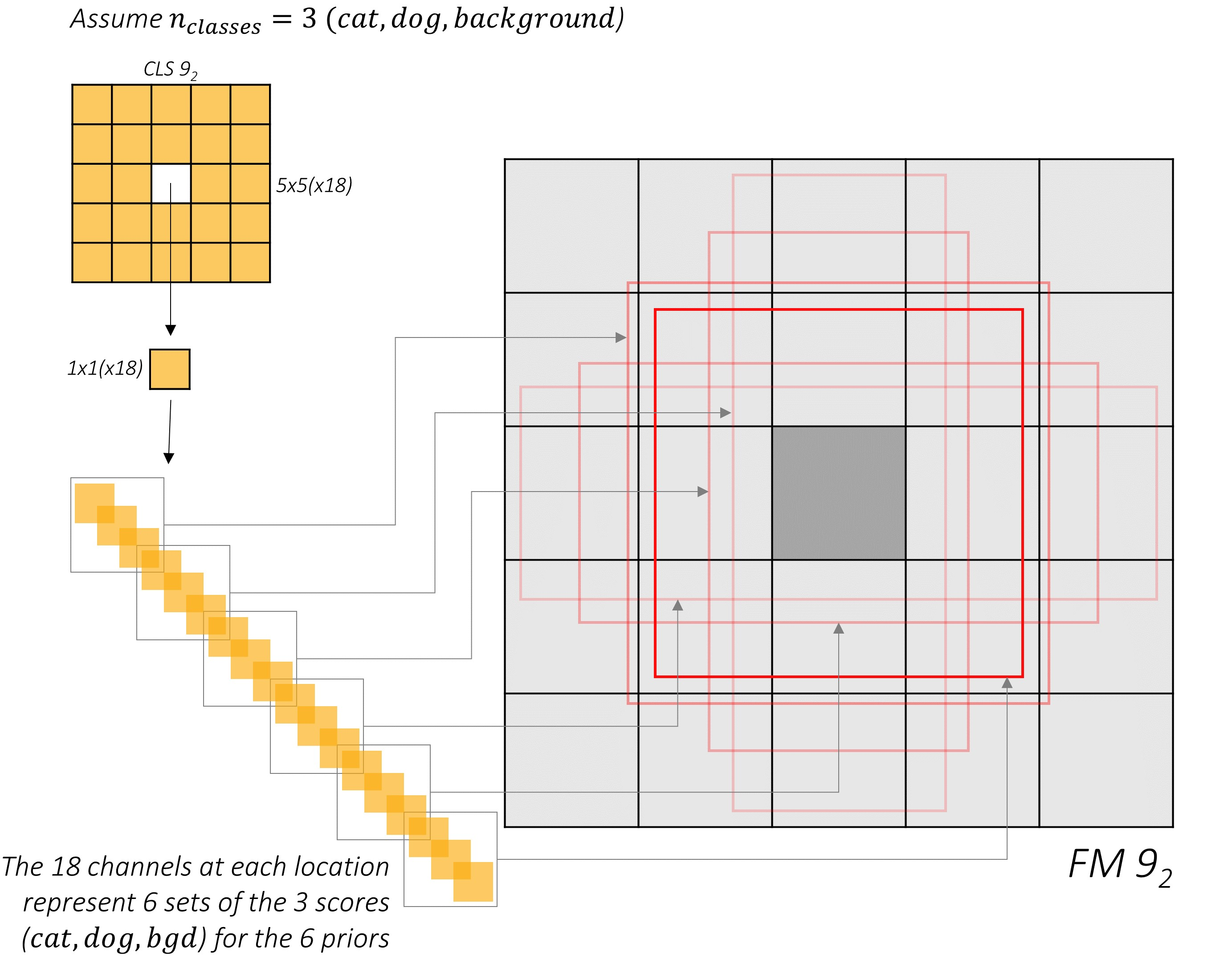
주황색 사각형도 비슷한 메커니즘이지만 default box의 좌표가 아닌 객체가 존재할 확률(점수)을 나타낸다. 마찬가지로 (예를 들어) 가운데 칸에서 만들어지는 default box(6개)에 클래스 존재 확률(3개)을 나타내는 것이고, 6 * 3이 되어 output 채널 수는 18이 된다.
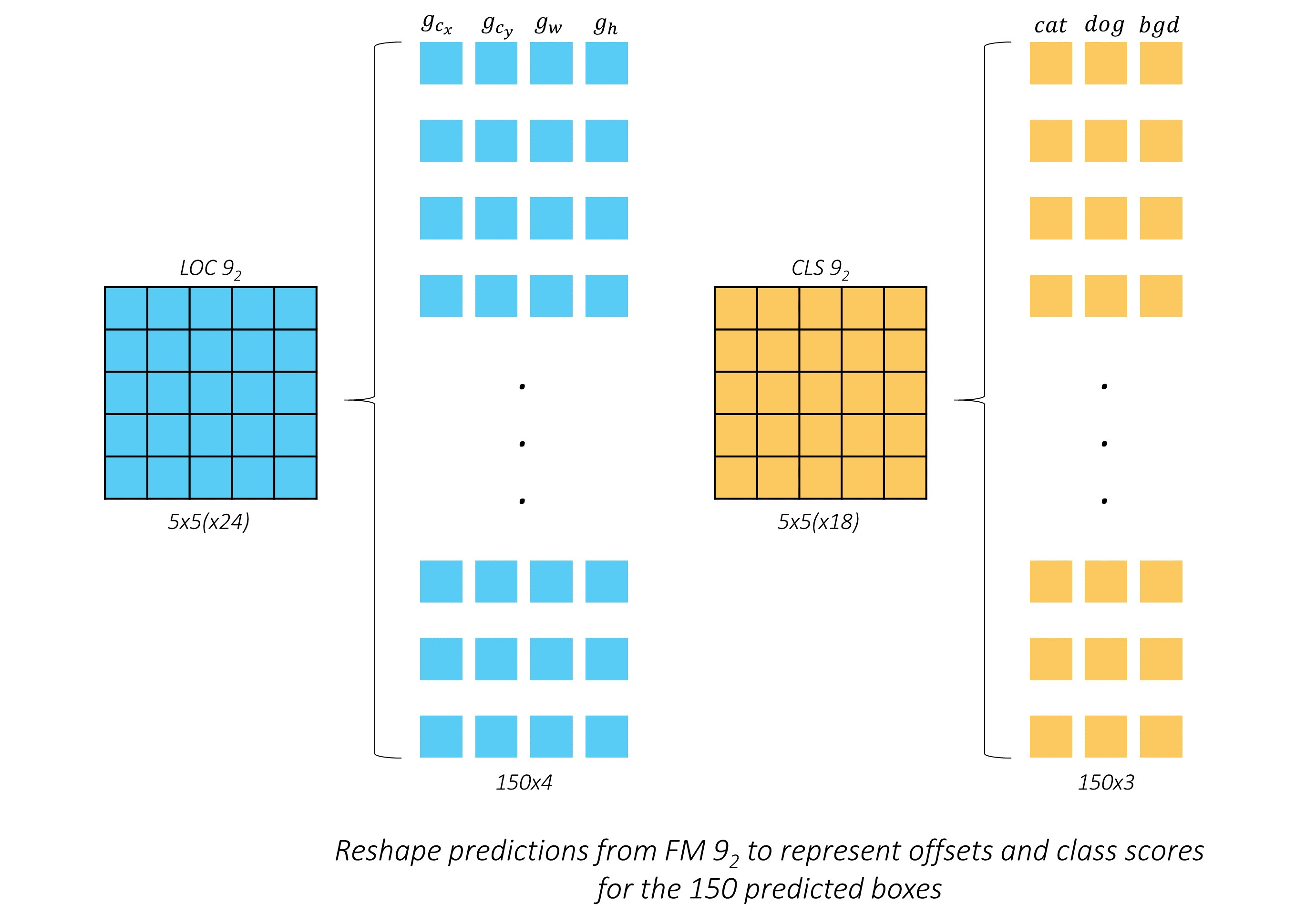
모양을 변형해서 나타내면 위 그림과 같다. 칸 하나당 default box 6개가 만들어지므로 총 150개(5 * 5 * 6)의 default box가 만들어지는데, 파란색 사각형은 좌표를 나타내므로 150 * 4개, 주황색 사각형은 객체의 존재 확률을 나타내므로 150 * 3개의 값을 출력하게 된다.
Default boxes and aspect ratios. 위에서 설명한 것처럼 최종적으로 네트워크는 box의 offset과 객체가 존재하는 점수(score)를 출력한다. 하나의 cell에서 만들어지는 default box의 개수를 k, class의 개수를 c라 하면, 하나의 셀 당 (4 + c) * k 개의 값이 출력된다. 이때 feature map의 크기가 m * n이라면 하나의 feature map당 만들어지는 값의 개수는 총 (4 + c) * k * m * n이 되는 것이다.
2.2 Training
Region proposal method를 사용하는 기존의 전형적인 검출기와 SSD에는 학습 방법의 차이가 있다. 최종적으로 loss를 계산할 때, 모델이 예측한 bounding box와 ground-truth box 사이의 차이를 구해야 한다. 이때 예측한 bounding box 중 어느 box를 사용할지 결정하는 기준이 다르다. 이렇게 SSD의 training은 default box와 스케일을 선택하고, hard negative mining과 data augmentation(데이터 증강)을 수행한다.
Matching strategy. 앞서 말했듯이 학습 중에 어느 default box를 ground-truth box와 비교할지를 선택해야 하는데, 다양한 크기의 feature map에서 여러 가지 scale과 aspect ratio로 구성된 default box 중 ground-truth box와의 IoU가 0.5 이상인 default box들을 선택한다. best IoU를 사용했던 기존 네트워크와 다르게(ex YOLO, MultiBox) SSD는 기준을 완화시킴으로써 겹쳐져 있는 box에 대해 높은 저모를 예측할 수 있게 만들었다.
YOLOv1의 경우, 최댓값의 IoU를 가지는 bounding box만 ground-truth box와 비교했기 때문에 객체가 겹쳐있거나 군집으로 이루어진 경우에 대해 취약한 결과를 보였다.
Matching의 의미는, IoU 값을 기준으로 예측된 default box 안에 객체가 있는지, 없는지를 판단한다. 이때 SSD 기준 IoU가 0.5 이상이면 객체가 있다고 판단하여 ground truth에 매칭시킨다.
Training objective. SSD의 목적함수(objective function)는 MultiBox의 목적함수에서 유래했지만 다중 객체도 다룰 수 있게끔 확장시켰다. $x^p_{ij} = {1,0}$를 class $p$ $p$$i$번째 default box와 $j$번째 ground truth box가 매칭되었음을 의미한다고 하면,
$$
L(x, c, l, g)=\frac {1}{N}(L_{conf}(x, c) + \alpha L_{loc}(x,l,g))
$$
위 식이 바로 SDD의 목적함수(= 손실함수)다. Confidence score와 localization의 weighted sum(가중합) 형태이다. 위 식에서 변수들이 가리키는 것은 다음과 같다.
$N$ : 매칭된 default box의 개수
$l$ : 예측된 box의 좌표
$g$ : ground truth box의 좌표
$N$이 0이면 매칭된 default box가 없다는 것이므로, loss를 0으로 설정한다.
Localization loss($L_{loc}$)부터 살펴보자. $L_{loc}$는 예측된 box와 ground truth box의 smooth L1 loss이다. Fatser R-CNN과 유사하게 box의 offset은 중심(cs, cy)과 너비, 높이(w, h)로 표현한다.
$$L_{loc}(x,l,g) = \sum^N_{i \in pos} \sum_{m \in {cs,cy,w,h}} x^k_{ij}smooth_{L1}(l^m_i - \hat g^m_j)$$
위 식은 SSD의 localization loss를 나타낸다. $x^p_{ij}$는 매칭된 box에 대해 1을 출력하고 그렇지 않으면 0을 출력한다. 즉 위 식은 매칭된 default box에 대해 예측한 box의 offset($l^m_i$)을 ground truth($g^m_j$)와 비교하여 loss를 계산한다. 이 때 m은 class(부류)를 의미한다.
$$
\hat g^{cx}j = (g^{cx}_j - d^{cx}_i) / d^w_i \qquad \hat g^{cy}j = (g^{cy}_j - d^{cy}_i) / d^h_i \
\hat g^w_j = log(\frac{g^w_j}{d^w_i}) \qquad \hat g^h_j = log(\frac{g^h_j}{d^h_i})
$$
Localization은 bounding box의 직접적인 좌표가 아닌 default box와 ground truth box 사이의 차이에 해당하는 offset을 추정하기 때문에 $\hat g$를 계산해주어야 한다. 이때 $\hat g$ 는 ground truth box와 default box의 차이로 계산된다. 또한 정규화를 위해 중심 좌표(cx, cy)는 각각 $d^w_i, d^h_i$로 나눠주고, 너비와 높이(w, h)는 $d^w_i, d^h_i$로 나눠준 후 log를 취한다.
다음으로 confidence loss($L_{conf}$)를 살펴보자.
$$
L_{conf}(x,c)=-\sum^N_{i\in Pos}x^p_{ij}log(\hat c^p_i) - \sum_{i \in Neg}log(\hat c^0_i) \quad \hat c^p_i = \frac{exp(c^p_i)}{\sum_p exp(c^p_i)}
$$
$c^p_i$는 $i$번째 default box에 class $p$의 객체가 존재할 확률을 나타낸다. 이때 p = 0은 background를 의미한다. $\hat c^p_i$는 모든 클래스에 대해 softmax를 취한 값이다. $L_{conf}$는 positive와 negative일 경우로 나뉘는데, 만약 매칭된 default box라면 $\sum_{i \in Neg}log(\hat c^0_i)$ 의 값이, 매칭되지 않은 default box라면 $\sum_{i \in Neg}log(\hat c^0_i)$의 값이 계산된다.
Choosing scales and aspect ratios for default boxes. 그동안 object detection애서 한 이미지 내 크기가 서로 다른 객체를 모두 검출하기 위해 여러 가지 방법을 사용했다. 하나의 이미지를 다양한 크기(확대, 축소)로 처리하는 등의 방법이 있는데, SSD는 single network 안에서 다양한 크기의 feature map을 사용함으로써 비슷한 효과를 낸다.
Network의 layer가 깊어질수록 low-level feature에서 high-level feature를 추출하게 되는데, 기존의 연구에서 low-level feature는 semantic segmentation의 질을 향상한다는 것을 보여주었다. lower layer일수록 객체의 fine details 한 특징을 잡아내기 때문이다.
보통 low-level feature는 물체의 윤곽이나 에지등을 추출하는 경향이 있고 high-level 일 수록 고차원적인 특징(컴퓨터에 특화된), 예를 들어 물체의 texture 등을 추출한다.
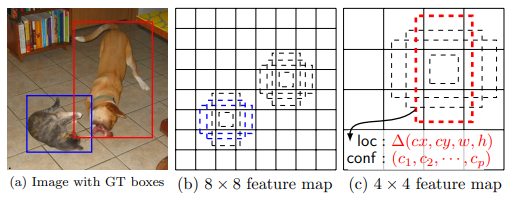
(a)는 input image인데, 작은 고양이와 큰 강아지가 있는 사진이다. 위에서 말한 것과 같이 하나의 이미지 내에서 크기가 다른 객체가 존재하기 때문에 이들을 모두 검출해야 하고, 이를 정확하게 수행하기 위해 SSD는 default box를 도입한 것이다. (b)와 (c)는 각각 8 * 8, 4 * 4 크기의 feature map인데, 만들어지는 default box의 크기가 다른 것을 확인할 수 있다. 따라서 고양이는 8 * 8 feature map의 default box에서 검출되고 강아지는 4 * 4 feature map의 default box에서 검출되는 것이다.
Scale. Default box는 다양한 scale과 aspect ratio를 가진다고 했는데, m개의 feature map을 사용한다고 할 때 scale $s_k$는 다음과 같이 결정한다. SSD에서 사용하는 feature map의 개수 m은 5이다.(conv4_3에서 나온 feature map의 scale은 0.1로, 여기에 포함되지 않는다. 즉, 총 6개의 feature map을 prediction에 사용하는 것)
$$
s_k = s_{min} + \frac{s_{max} - s_{min}}{m-1}(k-1), \qquad k \in [1,m]
$$
$s_{max}, s_{min}$은 하이퍼 파라미터이고 각각 0.9, 0.2로 설정하면 5개 feature map의 scale은 각각 0.2, 0.375, 0.55, 0.725, 0.9이 된다.
Aspect ratio. default box의 aspect ratio는 $a_r \in {1,2,3,\frac{1}{2}, \frac{1}{3}}$로 구성된다. 이때 k번째 feature map에서의 default box의 width와 height는 scale과 aspect ratio를 곱하여 각각 $w^a_k=s_k \sqrt a_r, \ h^a_k = s_k/ \sqrt a_r$로 계산된다. Aspect ratio가 1일 때 scale 값 $s'_k = \sqrt{s_k s_{k+1}}$ 를 추가로 사용하여 하나의 scale당 default box의 틀은 총 6개가 만들어진다. 여러 가지 dataset에 대해 scale과 aspect ratio를 어떻게 설정하여 적용할 것인지는 open question이다.
다양한 feature map으로부터 여러가지 scale과 aspect ratio을 가진 default box를 결합하여 예측에 사용하면 input object의 다양한 size, shape을 커버할 수 있게 된다. 개와 고양이 사진을 다시 보면 8 * 8 feature map에서 개에 맞는 default box는 존재하지 않는데, 이는 default box가 개와 다른 scale을 가지기 때문이고, 따라서 학습 중에는 negative로 취급된다.
Hard Negative mining. 매칭 단계 후, 대부분의 deafult box는 negative일 것이다.(보통 배경이 차지하는 부분이 객체보다
많기 때문에) positive와 negative training example에서 불균형이 발생한 것이다. 이때 negative sample을 모두 사용하지 않고 가장 높은 confidence loss를 가지는 default box만 사용하여 positive와 negative의 비율을 1:3으로 맞춘다.
Data augmentation. 모델을 object의 크기와 모양에 상관없이 강건해지게 하기 위해 다음 중 하나를 랜덤으로 적용한다.
- 원본 이미지 전체를 사용
- 객체와의 최소 IoU가 0.1, 0.3, 0.5, 0.7, 0.9가 되게 샘플링
- 무작위 크기의 patch(random crop) 사용
샘플링된 패치의 크기는 원본 이미지의 [0.1, 1]이고 종횡비는 1/2에서 2 사이다. 또한 ground truth box의 중심이 crop 된 패치 안에 위치할 경우에만 box와 겹치는 부분을 유지한다. 그 후 샘플링된 패치를 고정된 크기로 조정하고 horizontal flip을 0.5의 확률로 적용한다. 마지막으로 photo-metric distortions를 적용한다.


