
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- object detection
- gres
- 논문 요약
- vlm
- 에지 검출
- E2E 자율주행
- res paper
- 1차 미분 마스크
- 딥러닝 엔트로피
- Object detection article
- gsoc 후기
- clip
- gsoc
- transfuser++
- referring expression segmentation
- 논문 리뷰
- 객체 검출
- 딥러닝 목적함수
- google summer of code
- 엔트로피란
- clip adapter
- gsoc 2025
- grefcoco
- grefcoco dataset
- mobilenetv1
- 원격 학습 안끊기게
- TransFuser
- 이미지 필터링
- res
- blip-2
- Today
- Total
My Vision, Computer Vision
[논문 리뷰/요약]A Survey of Modern Deep Learning based Object Detection Models(1) 본문
[논문 리뷰/요약]A Survey of Modern Deep Learning based Object Detection Models(1)
gyuilLim 2024. 2. 15. 16:49A Survey of Modern Deep Learning based Object Detection Models
Object Detection is the task of classification and localization of objects in an image or video. It has gained prominence in recent years due to its widespread applications. This article surveys recent developments in deep learning based object detectors.
arxiv.org
이 논문은 2021년 쓰였다. 2012년 AlexNet의 등장으로 CNN이 본격적으로 재조명된 후부터 Object detection(객체 검출) 분야의 발전 과정을 여러가지 모델들의 등장 시기에 맞춰 설명한다. 각 모델들의 구조, 특징, 한계 등을 간략하게 기술해 놓아서 대략적인 흐름을 파악하는데 도움을 주는 논문이다.
Abstract
이 논문은 Object Detection 분야 딥러닝 기반의 현대 모델들의 발전 과정을 다룬다. 또한 Object detecion 분야의 표준이 되는(benchmark) Dataset과 평가 지표(Evaluation metrics), 주로 사용되는 backbone architecture와 edge device에서 사용되는 가벼운(Lightweight) 분류 모델에 대해 간단히 비교 분석한 결과를 보여준다.
1. INTRODUCTION
Object detection. 객체 검출은 몇 개월 된 아기도 할 수 있을 정도로 인간에게는 사소한 작업이지만, 컴퓨터에게 학습시키는 것은 쉽지 않은 일이다. 객체를 검출해 내는 작업은 객체의 종류가 무엇인지, 어디에 있는지를 동시에 알아내야 하기 때문이다. Object detection은 segmentation, classification, motion estimation과 더불어 computer vision 분야의 기본적인 문제(Fundementatl problem)이다.
CNN 모델이 사용되기 전, HOG(Histogram of Oriented Gradients) 등 수작업(hand-crafted) 특징 추출 방법을 사용하면 친숙하지 않은 데이터(Unfamiliar, Unseen)에 대해 정확하지 않다는 문제가 있었다. 하지만 AlexNet의 등장으로 Object detection 분야에서 CNN이 재조명받게 되었다. 오늘날 Object detecion은 자율주행, 신원 확인, 의학 분야에 활용되고 있다.
이 논문의 목차는 다음과 같다.

Introduction → Background → Datasets, and Evaluation Metrics → Backbone Architectures → Object Detectiors → Lightweight Detectors → Comparison → Future Trends → Conclusion
- single, two stage 모델들에 대한 깊이있는 분석과 발전 과정에 대해 다룬다.
- backbone architecture와 light weight 모델에 대해 세부적으로 다룬다.
2. BACKGROUND
Problem Statement. Object detection은 Object classification에서 자연스럽게 확장된 작업이다. Object detection은 이미지 내 모든 객체들의 부류와 위치를 알아내고 그 위치에 맞게 사각형(Bounding box)을 그려내는 것을 목표로 한다.
Key challenge in Object Detection. 컴퓨터 비전은 지난 10년간 많이 발전했지만, 여전히 극복해야 할 문제들이 남아있다.
- Intra class variation(클래스 내 변형)
- 같은 부류에 속한 객체더라도 항상 일정하게 나타나지 않고 그림자, 빛, 시점 등 여러 가지에 의해 변형될 수 있다. 이러한 제약 없는 변형들은 물체를 검출하기 더욱 어렵게 만든다.
- Number of categories
- 훈련하는 객체의 부류가 많아질수록 난이도는 올라가고 High-quality의 주석이 달린(annotated) 데이터들이 필요하다. 또한 작은 양의 데이터셋으로 훈련시키는 것 또한 연구가 진행되고 있다.
- Efficiency
- 현대의 모델들은 정확한 성능을 내기 위해 많은 컴퓨팅 자원을 요구한다. Mobile, edge device에서 사용할 모델은 더욱 발전해야 한다.
3. DATASETS AND EVALUDATION METRICS
Datasets. Object detection 분야에서 사용하는 대표적인 데이터셋에 대해 알아본다.
a. PASCAL VOC 07/12(2005)
- The Pascal Visual Object Classes(VOC) challenge
- VOC07
- 5K training images
- 12K labelled objects
- VOC12
- 11K training images
- 27K labelled objects
- Evaluation metric - mAP
- Pascal VOC의 class 분포도

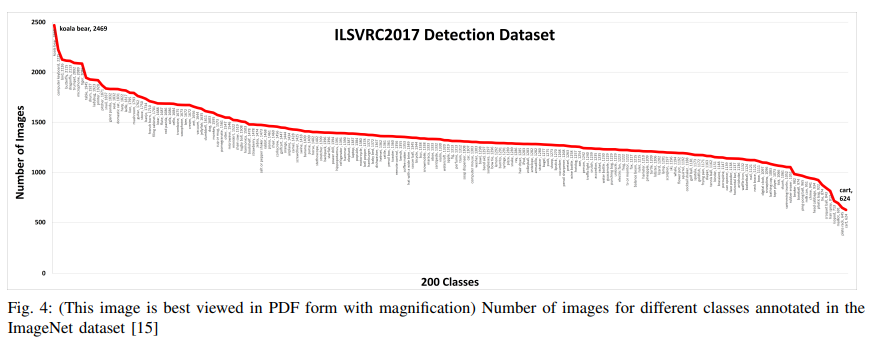
b. ILSVRC(2010)
- The ImageNet Large Scale Visual Recognition Challenge
- 1M training images
- 1K classes
- ImageNet의 class 분포
c. MS-COCO(2015)
- The Microsoft Common Objects in Context
- 91 common objects
- 2M instances
- 3.5 categories per image
- 7.7 instances per image
- 0.5 ~ 0.95 IoU
- MS-COCO의 class 분포

d. Open Image(2017)
- Google’s Open Images dataset
- 16M bounding boxes
- 600 categories
- 1.9M images
- 8.3 object categories per image
- Open Image의 class 분포

e. Issues of Data Skew/Bias
위에서 소개한 4개의 데이터셋 중 ImageNet을 제외한 Pascal VOC, MS-COCO, Open Image 3가지 데이터셋은 약 상위 5개의 클래스에서 분포가 현저히 감소하는 양상을 확인할 수 있다. Pascal VOC에서 ‘person’이 13775개로 가장 많이 등장했고, ‘sheep’이 552개로 제일 적게 등장했다. 다른 데이터셋에서도 마찬가지로 Skew(기울어짐)/Bias(편향)을 확인할 수 있다. Skewed dataset으로 학습된 모델은 당연하게도 이미지 수가 적은 부류보다 많은 부류에 대해 더 높은 정확도를 보일 것이다. 그나마 ImageNet은 Skew/Bias의 정도가 크지 않지만, 상위에 분포한 클래스들이 ‘koala’, ‘computer keyboard’ 등 실생활 object detecion(person, cars, traffic sign 등)에 관련성이 크지 않다는 문제가 있다.
Metrics
Object detection에서 주로 사용하는 평가 지표에는 FPS(frames per second), precision and recall, mAP 등이 있는데 이 중 mAP가 주로 사용된다.
mAP(mean Average Precision). precision은 IoU를 기준으로 구해진다. IoU는 두 개의 영역이 겹치는 비율을 의미한다. 만약 예측한 영역과 실제 영역의 IoU가 사전에 정의한 임계값보다 크면 True Positive로 분류되고 그렇지 않으면 False Positive로 분류된다. 또한 모델이 객체가 존재하는데 찾아내지 못하면 False Negative로 분류된다.
TP(True Positive) : 객체를 객체로 예측한 경우
FP(False Positive) : 배경을 객체로 예측한 경우
TN(True Negative) : 배경을 배경으로 예측한 경우
FN(False Negative) : 객체를 배경으로 예측한 경우

Precision과 Recall은 구해진 TP, FP, TN, FN으로 계산된다. 이 때 Average Precision은 class마다 각각 계산되는데, 이 값들의 평균을 mAP(mean Average Precision)라고 정의한 것이다.
4. BACKBONE ARCHITECTURES
AlexNet(2012)

Structure : 5 conv + 3 fc + softmax
Other method : dropout, ReLU
Note
- ILSVRC 2012 우승
- 다른 모델보다 약 26% 이상의 정확도
- AlexNet의 등장으로 Image processing에서 CNN이 주목받게 되었다.
VGG16(2014)

Structure : 13 conv + 3 fc + softmax
Note
- Small convolution filters(3 * 3), varying depths
- 크기가 작은 필터를 사용하지만 깊이를 늘림으로써 receptive field를 증가
- ILSVRC 2014 우승한 GoogLeNet을 능가
GoogLeNet(2014)

모델의 정확도가 점점 향상됨에 따라 요구되는 컴퓨팅 자원의 양도 증가했다. 모델이 깊어질수록 paramter 또한 증가하는데, 이는 과적합의 이유가 될 수 있었다. 이러한 이유로 GoogLeNet에서는 Fully connected layer 대신 locally sparse connected architecture를 사용한다.
Structure : 22 conv(inception) + softmax
Note
- 컴퓨팅 자원을 효율적으로 사용
- ImageNet에서 93.3%의 top-5 acc 달성
ResNets(2015)

Layer 사이 skip connection을 추가하여 residual learning을 도입하였다. 이 덕분에 층을 깊이 늘릴 수 있었고, batch normalization, ReLU 등을 사용한 ResNetv2도 제시하였다.
ResNeXt(2016)

기존 모델에 비해 간단하고 효율적인 모델이다. ResNet block을 inception과 비슷한 ResNeXt module로 교체하였다. ResNet과 비슷한 깊이를 가지지만 hyper parameter의 개수는 더 적고 정확도는 증가시켰다.
CSPNet(2019)

CSPNet의 저자는 Inference에서 대부분의 연산이 중복된 gradient에 의해 발생한다고 보았고, 네트워크 내 중복된 gradient를 제거하면 연산을 줄일 수 있다고 생각했다. Input feature map의 전체를 사용한 Dense Block과 다르게 Partial Dense Block은 절반만 사용함으로써 중복되는 gradient를 줄였다. 이 method를 적용하면 연산이 10-20% 정도 감소하고, 메모리와 연산 bottleneck또한 감소한다.
EfficientNet(2019)

EfficientNet은 depth, width, resolution의 scale을 조절한다. 모델의 depth를 증가시키면 더욱 복잡한 특징을 추출할 수 있지만 가중치 소멸 문제가 발생할 수 있다. 반면 모델의 width(channel)를 증가시키면 find-grained 특징을 추출할 수 있지만 고수준 특징은 추출하기 어렵다. Depth, with와 마찬가지로 resolution을 증가시키는 것은 모델이 포화될 수 있다. EfficientNet은 이 3가지의 적당한 타협점을 찾아내도록 한다.
5. OBJECT DETECTORS
Object detectors는 two stage, single stage를 기준으로 나누어 설명한다. Region proposal module을 따로 가지고 있는 모델을 two stage라고 한다. 즉 classification과 localization이 분리되었기 때문에 two stage인 것이다. 반면 classification과 localization을 한 번에 학습하는 모델을 single stage라고 한다.
Pioneer Work(딥러닝 이전)
- Viola-Jones(2001)
- Input image에 대해 sliding window 방식으로 Haar-like features 추출
- Adaboost를 classifier로 사용
- 아직까지도 small device에서 사용된다.
- HOG Detector(2005)
- Edge의 방향에 대한 gradient를 추출하고 feature table을 만든다.
- 이미지를 grid로 나눈 후 feature table로 각 셀에 대한 histogram을 만든다.
- HOG를 이용하여 RoI를 추출한 후 SVM을 classifier로 사용한다.
- DPM(2009)
- Pascal VOC 2009 우승
- Divide and rule 개념
- 이미지를 여러개로 나누고 분류한 후 다시 합친다.
- DPM을 활용한 모델들은 딥러닝 이전 가장 강력했다.
'Paper' 카테고리의 다른 글
| [논문 리뷰/요약]How to Read a Paper (0) | 2024.02.21 |
|---|---|
| [논문 리뷰/요약]A Survey of Modern Deep Learning based Object Detection Models(2) (0) | 2024.02.15 |
| [논문 리뷰/요약]YOLO v1 (1) | 2024.02.09 |
| [논문 리뷰/요약]Faster R-CNN (1) | 2024.02.09 |
| [논문 리뷰/요약]Fast R-CNN (2) | 2024.02.09 |
