
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 1차 미분 마스크
- referring expression segmentation
- gsoc 2025
- TransFuser
- grefcoco dataset
- 딥러닝 목적함수
- clip
- 논문 리뷰
- grefcoco
- 엔트로피란
- E2E 자율주행
- 객체 검출
- blip-2
- res paper
- 이미지 필터링
- google summer of code
- res
- Object detection article
- 원격 학습 안끊기게
- gsoc 후기
- object detection
- 에지 검출
- 딥러닝 엔트로피
- gsoc
- mobilenetv1
- gres
- vlm
- clip adapter
- transfuser++
- 논문 요약
- Today
- Total
My Vision, Computer Vision
[논문 리뷰/요약]Fast R-CNN 본문
Fast R-CNN
This paper proposes a Fast Region-based Convolutional Network method (Fast R-CNN) for object detection. Fast R-CNN builds on previous work to efficiently classify object proposals using deep convolutional networks. Compared to previous work, Fast R-CNN emp
arxiv.org
Abstract
Fast R-CNN(Region-based)은 R-CNN에 비해 VGG16을 9배 빠르게 훈련시키고, test time은 213배 더 빠르다. PASCAL VOC 2012에서 높은 mAP 성능을 달성했다. SPPnet과 비교했을 때 VGG16을 3배 빠르게 훈련시키고 test time은 10배 빠르다.
- PASCAL VOC(Visual Object Classes) 2012 : 2012년에 구축된 PASCAL VOC dataset을 사용하는 challenge
1. Introduction
image classification에 비해 object detection은 더 복잡하기 때문에 현대의 모델들은 multi-stage pipelines를 사용하는데, 이 방법은 느리고 inelegant 하다. 이러한 복잡도는 물체의 위치(localization, proposals)까지 계산해야 하기 때문에 생긴다. 이때 두 가지 방법이 사용되는데,
- 물체 위치에 대한 여러개의 후보를 생성해야 한다.
- rough localization 수준의 후보들을 정밀한 위치로 가공해야 한다.
위 방법들은 대게 속도, 정확도, 간결성 사이에서 타협한다.
이 논문에서는 convNet-based object detectors를 간소화하여 single-satge training algorithm으로 만들고, 물체의 proposals을 구별하는 것과 proposals의 공간적 위치를 재구성하는 것을 함께 학습하는 방법을 제시한다.
1.1. R-CNN and SPPnet
R-CNN은 deep ConvNet을 사용하여 높은 정확도를 달성했지만 몇 가지 단점이 있다.
- Training is a multi-stage pipeline
- First stage : image와 RoI를 convNet로 훈련
- Second satge : feature vector로 calssfication을 위한 SVM 훈련
- Third stage : feature vector로 B-box regressor 훈련
R-CNN은 위와 같이 세 단계로 학습이 진행된다.
- Training is expensive in space and time
- SVM과 bounding box regressor 학습에서 각 이미지마다, 각 객체마다 추출된 특징이 disk에 저장된다.
- VGG-16 같은 깊은 네트워크를 VOC07(5k)에 적용시켰을 때 2.5 GPU-days와 수 백 기가바이트의 용량이 사용된다.
- Object detection is slow
- test-time의 경우, 각 test image의 object proposal에서 특징이 추출되고 VGG16을 이용한 Detection 과정에서 이미지당 약 47초가 소모된다.
* R-CNN
R-CNN은 First stage에서 추출된 약 2000개의 RoI를 모두 convolution layer에 입력하기 때문에 느리고, 모두 다른 크기를 가진 RoI들을 Crop&Wrap 하여 같은 크기로 맞춰주기 때문에 객체의 비율 늘어지거나 줄어들게 되며 이 과정에서 문제가 발생한다.
* SPPnet(Spatial Pyramid Pooling)
SPPnet은 RoI의 사이즈를 모두 같게 만들어주는 과정에서 발생한 문제를 해결하고자 Spatial Pyramid Pooling network를 도입하였다. 이 네트워크 덕분에 다양한 size의 feature map이 입력으로 들어오더라도 고정된 size의 출력을 얻을 수 있게 된다. 하지만 SPPnet도 R-CNN의 multi-stage pipeline을 그대로 따르기 때문에 space, time 비용이 크다. 또한 fine tunning algorithm을 사용하기 때문에 모든 네트워크를 학습시키지 않게 되어 성능에 제한이 생긴다.
1.2 Contributions
이 논문에서는 위에서 언급한 R-CNN과 SPPnet의 단점을 보완한 새로운 학습 알고리즘을 제안한다. 이 method를 Fast R-CNN이라고 한다. Fast R-CNN의 이점은 다음과 같다.
- Higher detection quality (mAP) than R-CNN, SPPnet : R-CNN, SPPnet과 비교했을 때 높은 mAP를 달성했다.
- Training is single-stage, using a multi-task loss : multi-stage가 아닌 single-stage를 사용했다.
- Training can update all network layers : fine tunning network를 사용하지만 convNet을 학습시킬 수 있었다.
- No disk storage is required for feature caching : feature를 저장하는데 memory가 많이 사용되지 않는다.
2. Fast R-CNN architecture and training
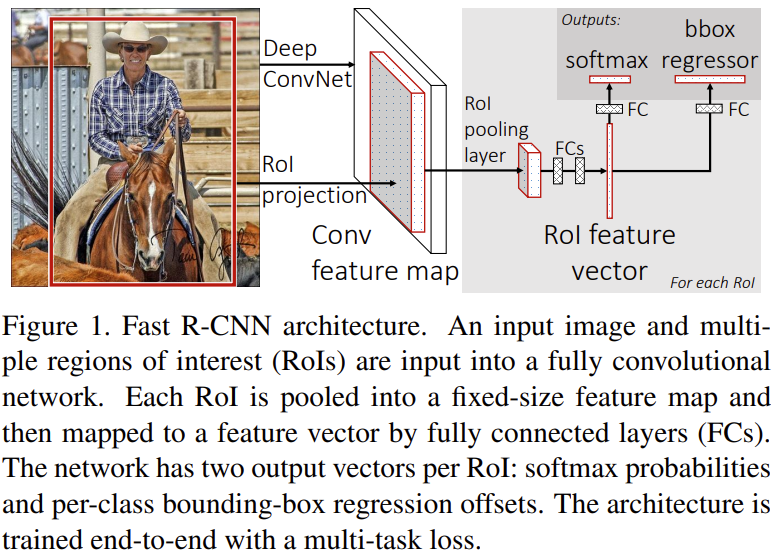
Fast R-CNN의 구조와 학습 과정은 다음과 같다.
- selective search를 통해 물체가 있을만한 영역(RoI, proposal)을 찾는다.
- Fast R-CNN은 이미지와 set of object proposal을 입력으로 받는다.
- 먼저 이미지에 대하여 Convolution과 Pooling을 수행한 후 feature map을 구한다. 이때 2에서 구한 proposal과 feature map의 scale이 달라지기 때문에, RoI projection을 통해 RoI의 비율을 feature map에 맞춰준다.
- 그 후 projection 된 각각의 RoI에 대하여 RoI pooling을 적용하여 고정된 길이의 feature vector를 얻는다.
- 각각의 feature vector들은 fc layer를 거쳐 두 개의 출력 레이어(sibling layer)로 분기되어 입력된다.
- 첫 번째 출력 레이어는 softmax를 거쳐 K+1개의 확률값으로 표현된다.
- 두 번째 출력 레이어는 B-box의 실수 좌표로 출력된다.(r, c, h, w → r : top, c : left, h : height, w: width)
2.1. The RoI pooling layer
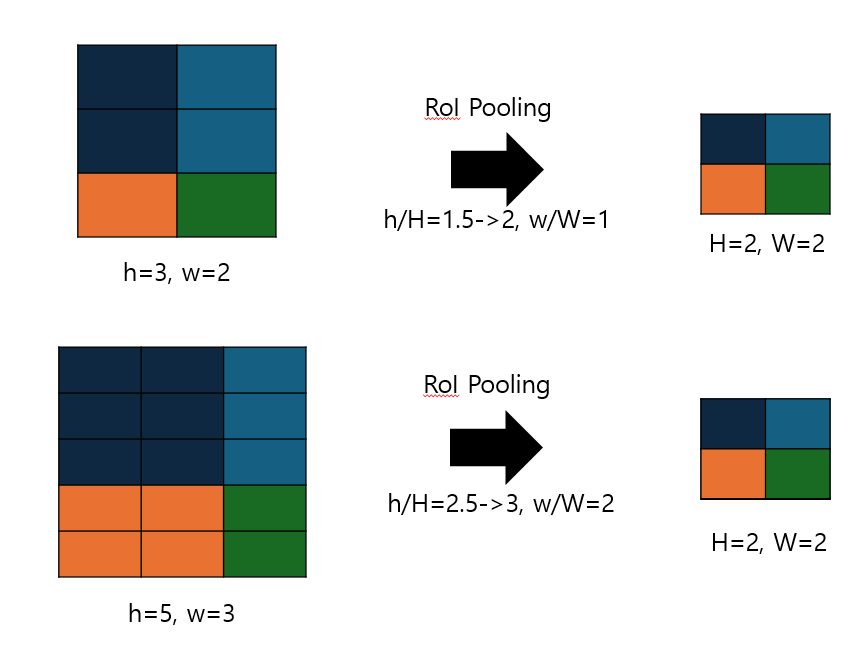
RoI pooling layer는 다양한 size의 RoI들을 같은 size로 맞추어주는 역할을 해주는 pooling layer이다. 이때 맞춰 줄 size는 하이퍼 파라미터이다. 예를 들어 3개의 RoI를 2_2로 맞춰준다고 하자. RoI각각의 크기는 3_2, 5_3, 5_7 이다. 이 때 pooling에 사용되는 커널의 사이즈는 (h/H, w/W)이다. h와 w는 RoI의 size이고, H, W는 하이퍼 파라미터이다. 따라서 RoI pooling의 kernel은 각각 (2,1), (3,2), (3, 4)가 되는 것이고 RoI pooling의 kernel 연산은 중복되는 픽셀없이 수행되기 때문에 모두 2*2 크기로 변환된다.
2.2. Initializing from pre-trained networks
이 논문에서는 ImageNet으로 사전학습된 세 개의 네트워크를 사용하여 실험을 진행했다. 각각 5개의 max pooling layer와 5~13개의 convolution layer로 구성되어 있다. 사전학습된 네트워크를 Fast R-CNN에 맞춰줄 때 3가지의 변형을 거친다.
- 마지막 max pooling layer가 RoI pooling layer로 대체된다. 이 때 VGG16을 사전학습 모델로 사용했을 경우 네트워크의 첫 번째 fc layer의 입력 크기와 연결하기 위해 H와 W를 7로 설정한다.
- 네트워크의 마지막 fc layer와 softmax는 두 개의 sibling layer로 대체된다.
- 네트워크가 두 가지의 입력(image와 RoI)을 받을 수 있게 수정한다.
2.3. Fine-tuning for detection
네트워크의 모든 weight를 학습할 수 있다는 것은 Fast R-CNN의 중요한 장점인데, 먼저 SPPNet이 weight update가 불가능한 이유를 살펴보자.
- 다른 이미지로부터 나온 RoI로 네트워크를 훈련시키는 것은 매우 비효율적이다.
- RoI의 size는 종종 입력 이미지와 비슷한데, 이는 RoI로 입력 이미지 전체를 사용한 꼴과 같다.
Fast R-CNN을 학습하는 효율적인 방법은 다음과 같다.
- SGD를 사용한다.
- N개의 이미지를 샘플링한 후 R/N개의 RoI를 샘플링한다. (N=2이고 R=128일 때 하나의 이미지 당 64개의 RoI가 샘플링된다. (128개의 이미지에서 1개의 RoI를 샘플링하는 것보다 64배 빠르다.)
이 논문에서 Fast R-CNN이 SPPnet, R-CNN의 전략에 비해 rough 하게 64배 더 빠르다고 했는데, 이 의미를 알아보자. RoI를 128개로 제한하여 학습한다고 가정했을 때, SPPnet과 R-CNN은 128개 이미지에서 각각 1개의 RoI를 추출하여 학습에 사용한다. 즉 1개의 이미지를 학습하는데 1개의 RoI를 사용하는 것이다. 반면 Fast R-CNN의 경우 2개의 이미지에서 각각 64개의 RoI를 추출하여 학습에 사용한다. Fast R-CNN은 1개의 이미지를 학습하는데 64개의 RoI가 사용되기 때문에 R-CNN, SPPnet보다 학습이 64배 더 빠르다고 한 것이다.
Multi-task loss
loss를 계산하기 위해 두 개의 output layer를 거친 후 출력값에 대해 정리하면 다음과 같다.
- 첫 번째 출력(classification)
- K+1개의 클래스를 나타내는 확률(0, background) : $p = (p_0,\dots, p_K)$
- 두 번째 출력(B-box regressor)
- k번째 class의 B-box offset 정보 : $t^k = (t^k_x, t^k_y, t^k_w, t^k_h)$
이때, gruond-truth class와 B-box를 각각 $u, v$로 표현한다. 이 두 가지의 target값과 두 output layer의 출력값들을 합쳐서 Loss를 계산하면 다음과 같이 나타낼 수 있다.
$$
L(p, u, t^u, v) = L_{cls}(p, u) + \lambda [u \ge1]L_{loc}(t^u,v)
$$
$L_{cls}(p,u)=-\log p_u$이고, 실제 class u에 대한 확률값의 log로 계산된다. $L_{loc}(t^u,v)$는 타겟 클래스 $u$에 대한 GT B-box $v = (v_x, v_y, v_w, v_h)$와 예측 결괏값 $t^u = (t^u_x,t^u_xy,t^u_w,t^u_h)$사이의 로스이다. 이때 $[u \ge 1]$은 Iverson bracket이라고 하고, u가 1 이상이면 1, 작으면 0을 출력한다. u가 0일 때는 background를 의미한다. 즉, 예측된 B-box의 class가 background인 경우는 0이 곱해져서 무시하게 된다. 다음으로 $L_{loc}(t^u,v)$의 계산식은 다음과 같다.
$$
L_{loc}(t^u,v)= \sum_{i \in {x,y,w,h}} smooth_{L1}(t^u_i - v_i) \
smooth_{L1}(x)= \begin{cases}0.5x^2 & if \left\vert x \right\vert <1\ \left\vert x \right\vert-0.5 &otherwise,
\end{cases}
$$
L2가 아닌 L1을 사용하는 이유는 이상치에 덜 민감하게 반응하기 때문이다. L2 loss는 제곱합이기 때문에, 만약 B-box의 offset값이 엄청 커지게 되면 그래디언트 폭주로 이어질 수 있다(미분을 해도 입력값이 살아있음). $\lambda$는 classifer와 regressor의 균형을 조절하는 역할인데, GT B=box $v$에 대해 정규화를 수행하기 때문에 $L_{cls}, L_{loc}$ 두 부분의 scale은 같아져서 $\lambda$는 보통 1로 설정한다.
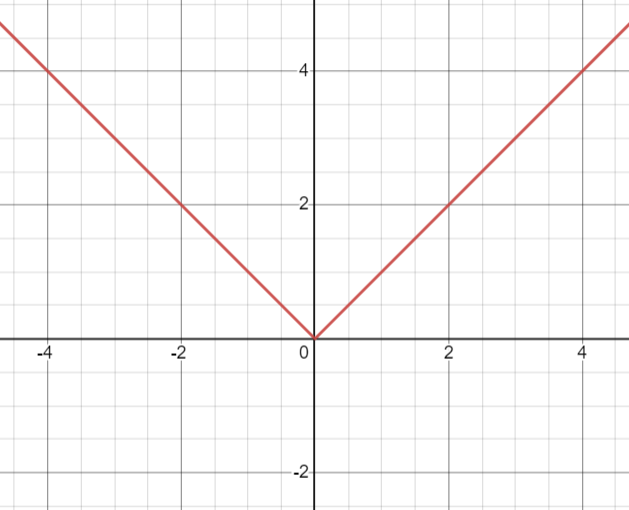
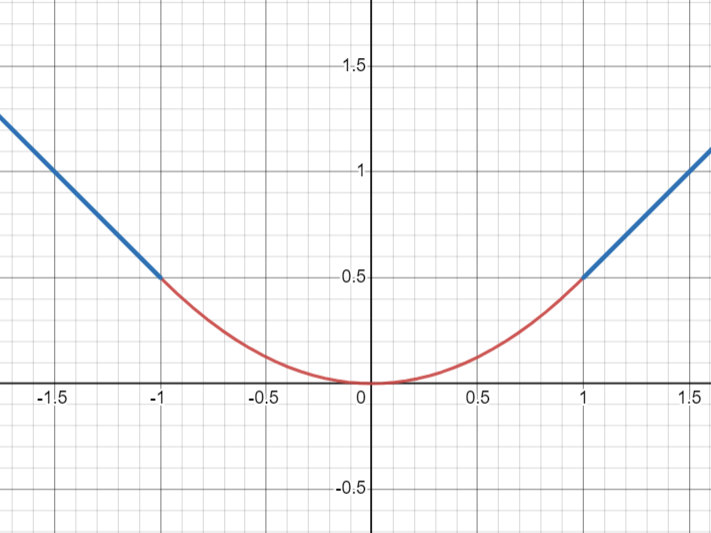
왼쪽 그래프는 L1 그래프이고, 오른쪽 그래프는 smooth L1이다. L1은 0에서 꺾이기 때문에 미분가능하지 않았지만, smooth L1은 x의 절댓값이 1 이하인 부분에서 $0.5x^2$을 취했기 때문에 부드러워져서 미분이 가능해진다. 따라서 smooth L1인 것이다.
multi-task loss가 잘 작동할 수 있었던 이유는 두 가지가 있는데, 먼저 수식을 보면 하나의 로스에 규제항이 더해진 것으로 볼 수 있다. 즉 loss항 2개가 서로 규제 역할을 해주고 있는 것이다. 다른 하나의 이유는 B-box를 찾아내는 task와 object를 classificaion 하는 task 두 개가 (긍정적인) 연관성이 있다는 것이다. 올바른 B-box는 객체에 딱 맞는 B-box일 것이기 때문이다.
Mini-batch sampling
위에서 말했듯이, N=2, R=128로 설정하여 하나의 이미지당 64개의 RoI를 sampling 한다. sampling 된 RoI 중 GT B-box와의 IoU가 0.5 이상인 약 25%의 RoI만 취한다. IoU의 범위가 [0.1, 0.5)인 RoI는 background로 간주한다. 0.1의 하한을 둔 이유는 hard exmaple mining을 위해서이다.
- hard exmaple mining : 어려운 예제에 가중치를 더 주고 학습하는 것
Back-propagation through RoI pooling layers
우선 오류 역전파 수식을 계산하기 위해 N=1로 가정한다. N>1인 경우는 N=1인 경우를 독립적으로 여러 개 적용하는 것이기 때문에 쉽게 확장할 수 있다.
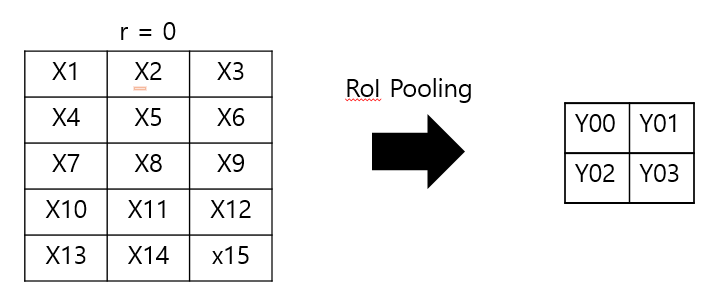
위 그림에서 왼쪽은 RoI이고, 오른쪽은 RoI pooling을 거친 출력이다. 이때 y와 x의 관계를 다음과 같이 나타낼 수 있다.
$$
y_{rj}=x_{i_(r,j)} \
where\ \ i_(r,j) = argmax_{i' \in R(r,j)}x_{i'}
$$
위 식에서 $R(r,j)$는 subwindow의 집합을 의미한다. 즉 RoI pooling은 max pooling을 이용했기 때문에 $y_{rj}$는 RoI의 subwindow 중에서 가장 큰 $x_{i}$가 되는 것이다. 위 정의를 바탕으로 RoI pooling layer의 backpropagation은 다음과 같이 유도된다.
$$
\frac{\partial L}{\partial x_i} = \sum_r \sum_j [i=i*(r,j)] \frac{\partial L}{\partial y_{rj}}
$$
먼저 위 수식은 max pooling의 back propagation 수식을 응용하여 유도된 것이다. CNN에서 오차 역전파가 진행될 때 뒷단의 오차를 앞단으로 넘겨줘야 하기 때문에 convolution layer 뿐만 아니라 pooling layer에서도 back propagation이 필요하다. 이어서 위 수식에 대해 설명해 보겠다.
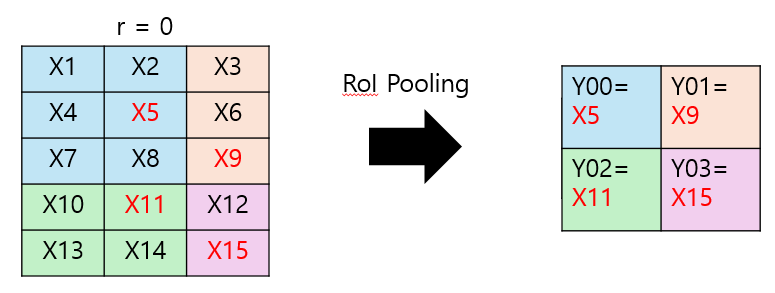
다시 이 그림에서 왼쪽은 하나의 입력 이미지에서 구해진 0번째 RoI를 의미한다. 하지만 실제 학습에서는 하나의 입력 이미지에 대해 여러 개의 RoI가 구해질 것이고 겹쳐진 RoI 중 X1, X2, … X15에 해당하는 픽셀들 위에 몇 개의 RoI가 더 겹쳐있을 수 있다. 예를 들어 $x_1$에 겹쳐진 RoI가 3개일 때, $x_1$주변에서 3개의 subwindow가 적용될 것이다. $[i=i*(r,j)]$는 $x_i$가 최댓값으로 선택되었을때 1의 값을, 그 외에는 0을 출력한다. 이때 $x_i$가 최대값으로 선택된 $y_{rj}$에 대해서 그래디언트를 더해주어 계산한다. $y_{rj}$는 역전파 과정에서 미리 계산해놓았기 때문에 더 요구되는 계산은 없다.
SGD hyper-parameters
먼저 sibling layer인 두 개의 출력 레이어(fc layer, bbox regressor)는 평균이 0이고 표준편차가 각각 0.01, 0.001인 정규분포로 초기화한다. 이 때 Bias는 0으로 초기화한다. layer의 weight의 learning rate는 1, bias들은 2로 설정하여 bias에는 weight 두 배의 학습률을 적용한다. global learning rate은 0.001로 사용한다. VOC07과 VOC12에서는 30k만큼의 mini-bathc iterations을 학습한 후 0.0001로 낮춰주고 10k 더 학습한다. 더 큰 데이터셋에서는 더 많은 iterations를 사용하고 모멘텀과 weight decay를 각각 0.9, 0.0005로 설정한다.
Scale invariance
scale에 대한 불변성을 가지기 위해, 즉 scale에 robust 한 모델을 만들기 위해 두 가지 방법을 사용 후 비교해 본다. 첫 번째 방법은 brute force, 두 번째 방법은 image pyramids를 사용하는 것이다. 두 방법에 대한 설명은 다음과 같다.
- brute force : 모든 입력 이미지의 size를 같게 맞춰준다.
- image pyramids : 다양한 크기의 이미지를 image pyramid에 적용하여 학습시킨다.
Fast R-CNN detection
Fast R-CNN이 파인 튜닝되면 forward pass에 대해서는 거의 완료되었다. 네트워크는 두 개의 데이터를 입력으로 받는다. 하나는 입력 이미지이고, 하나는 R개의 proposal이다. test-time에서 R은 약 2000이다. 각각의 RoI에 대하여 forawrd pass의 output은 2개인데, 해당 RoI가 어떤 class에 속하는지를 나타내는 확률 $p$와 각각의 RoI에 대하여 예측된 bounding-box offset이다. 이 결과를 다음과 같이 정의한다.
$$
Pr(class=k|r)\triangleq p_k
$$
RoI $r$이 $k$번째 class에 속할 확률을 $p_k$로 정의하는 것이다.
Truncated SVD for fatser detection
이 방법은 PCA와 유사한 방법으로, 특이값 분해를 이용하여 네트워크의 fc layer를 압축한 것이다. $u*v$ 크기의 가중치 행렬을 $W$라고 할 때, $W$는 다음과 같이 분해하여 근사할 수 있다.
$$
W \approx U\Sigma_tV^T
$$
$U, \Sigma_t, V^T$는 각각 $u_t, t_t, v*t$의 크기를 가진다. 이 세 개의 행렬에서 $U$와 $V^T$는 직교행렬이고 $\Sigma_t$는 직사각대각행렬이다.
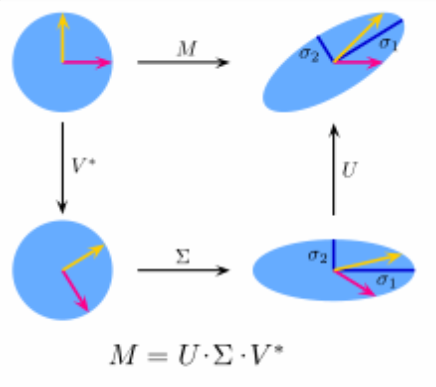
가중치 행렬 $W$를 $U, \Sigma_t, V^T$ 세 개 행렬의 곱으로 근사하여 나타낸 다는 것은 rotate, scaleing 하여 매개변수의 개수를 줄이고 실수값을 가진 가중치의 scale을 줄여 압축하는 것이다. 파라미터의 개수는 $u*v$에서 $t(u+v)$로 줄어든다. 따라서 정보의 손실이 조금 있더라도 높은 속도를 얻을 수 있게 된 것이다.
'Paper' 카테고리의 다른 글
| [논문 리뷰/요약]How to Read a Paper (0) | 2024.02.21 |
|---|---|
| [논문 리뷰/요약]A Survey of Modern Deep Learning based Object Detection Models(2) (0) | 2024.02.15 |
| [논문 리뷰/요약]A Survey of Modern Deep Learning based Object Detection Models(1) (3) | 2024.02.15 |
| [논문 리뷰/요약]YOLO v1 (1) | 2024.02.09 |
| [논문 리뷰/요약]Faster R-CNN (1) | 2024.02.09 |

