
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 딥러닝 엔트로피
- clip
- Object detection article
- res
- 논문 리뷰
- vlm
- 원격 학습 안끊기게
- blip-2
- 1차 미분 마스크
- google summer of code
- referring expression segmentation
- 객체 검출
- clip adapter
- TransFuser
- res paper
- object detection
- grefcoco
- gsoc 후기
- transfuser++
- 딥러닝 목적함수
- gsoc 2025
- 에지 검출
- E2E 자율주행
- mobilenetv1
- gsoc
- grefcoco dataset
- 이미지 필터링
- gres
- 논문 요약
- 엔트로피란
- Today
- Total
My Vision, Computer Vision
[논문 리뷰/요약]YOLO v1 본문
You Only Look Once: Unified, Real-Time Object Detection
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabili
arxiv.org
Abstract
분류기를 검출기로 사용했던 기존 방법들과 다르게 YOLO는 객체 검출을 회귀 문제로 보았다. 즉 기존 작업들은 Bounding box regressor와 classifier를 나누어 생각했지만 YOLO는 classifier와 regressor과정을 합쳐서 구현한 것이다. End-to-end로 학습되는 하나의(single) 신경망으로 구성된 YOLO는 전체 이미지를 입력으로 받고 Bounding box와 Class probabilities를 한꺼번에 예측한다.
1. Introduction
기존 객체 검출 모델들은 복잡한 Pipeline 때문에 각 단계마다 개별로 학습해야 하는 등의 이유로 느리고 최적화에 어려움이 있었지만 YOLO는 이러한 작업을 regressor와 classifier를 합쳐 single regression problem으로 취급했다(You Only Look Once).

YOLO의 구조는 매우 간단한다. 위 그림을 보면 총 3가지 단계로 이루어져 있다. Input image를 448*448 사이즈로 resize 한 다음 single convolutional network를 통과시켜 Bounding box와 class probability를 예측한다. class probability와 미리 설정한 임계값을 비교하여 최종 Bounding box만 남긴다. 이런 간단한 구조를 사용했을 때 이점은 다음과 같다.
- YOLO is extremely fast.
- base model은 45fps, fast model은 150 fps의 속도를 보인다. 기존 real-time method의 fps는 약 100 정도이다. 또한 mAP는 YOLO가 약 2배 높다.
- YOLO reasons globally about the image when making predictions.
- YOLO는 하나의 이미지를 single network에서 End-to-end로 학습하기 때문에 모델이 전체 이미지에 대한 context를 모두 사용한다고 할 수 있다. 이런 이유로 Fast R-CNN과 비교했을 때 background error는 약 두 배 정도 감소했다.
- YOLO learns generalizable representations of objects.
- 새로운 domain을 가진 data(ex. artwork)로 실험했을 때 YOLO는 DPM, R-CNN을 크게 능가한다. 이는 YOLO가 이미지내 객체의 일반화된 특징(texture보다 shape, edge에)을 학습한다고 할 수 있다.
하지만 SOTA detection 모델에 비해 성능은 뒤떨어진다. Accuracy-Speed의 trade-off를 제시한 것이다.
2. Unified Detection
먼저 Input image를 S*S개의 grid(grid cell이라고도 함.)로 나눈다. 이 grid안에 object가 있으면 해당 그리드는 그 object를 나타낸다.

위 그림은 Input image를 7*7개의 grid cell로 나눈 것이다.
Confidence score. 1개의 grid cell은 B개의 bounding box를 가진다. 하나의 bounding box는 5개의 값(x, y, w, h, confidence score)으로 표현된다. Confidence score란 bounding box안에 객체가 있을 확률과 bounding box가 얼마나 정확한지를 나타내는 수치인데,
$Pr(object) * IOU^{truth}_{pred}$로 계산한다. $Pr(object)$는 객체가 있을 확률이고 $IOU^{truth}_{pred}$는 bounding box와 ground-truth box의 IOU값이다. 즉 bounding box안에 객체가 있으면서 box가 얼마나 정확한지를 나타내는 수치이다.
만약 grid안에 객체가 존재하지 않을 경우 $Pr(object)=0$이 되어 confidence score는 0이 된다.
5 predictions. 하나의 bounding box는 5개의 값 x, y, w, h, confidence(score)로 표현한다고 했다. (x, y)는 grid cell 경계에서 box의 중심까지의 거리를 나타내는 값들이고 (w, h)는 전체 이미지 크기에 대한 상대적인 width, height값이다.
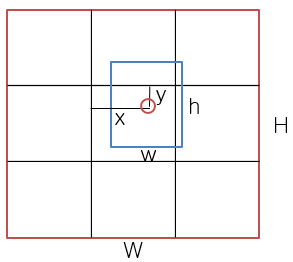
위 그림에서처럼 x와 y는 bounding box의 중심점이 속한 grid의 경계에서 중심점까지의 거리이다. w와 h는 bounding box의 너비와 높이이다. 이때 x, y, w, h 모두 원본 이미지의 W, H로 나누어 0~1 값으로 나타낸다. 마지막으로 confidence는 위에서 말했듯이 객체가 있을 확률에 ground-truth와의 IoU값을 곱한 것이다.
하나의 grid cell은 B개의 bounding box와 confidence socre를 가진다고 했는데, C개의 conditional class probabilities도 추가로 가진다. C는 class의 개수이다. 즉 해당 grid cell이 어떤 class를 나타내는지에 대한 값이며 조건부 확률 $Pr(Class_i|Object)$로 나타낸다. Grid안에 객체가 존재할 때 어떤 객체인지를 나타내는 확률이다.
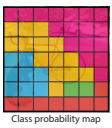
위 그림처럼 각각의 grid 안에 있는 object의 class를 대표(represent)하게 된다.
정리하면,
Bounding Box : x, y, w, h, confidence
Grid Cell : B of Boundig Box(x,y,w,h,cf) + C of conditional class prob($Pr(Class_i|object)$)이다.
Test time에서는 conditional class prob과 box의 confidence를 곱하는데,
$$
Pr(Class_i|Object) * Pr(Object) IOU^{truth}_{pred} = Pr(Class_i) * IOU^{truth}_{pred}
$$
위 수식으로 표현된다. 즉 해당 grid cell이 i번째 class일 확률과 ground-truth와의 IOU값을 곱해주어, 제일 높은 값을 가진 class와 Bounding box가 선택되는 것이다.
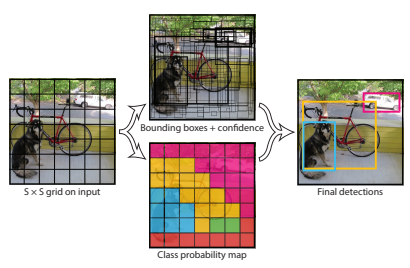
전체 과정을 그림으로 나타내면 위와 같다.
S(grid size) = 7
B(Num of Bounding box) = 2
C(Num of classs) = 20이라고 할 때,
YOLO의 최종 Output tensor의 크기는 7 * 7 * 30(30 = B*5+C)이다.
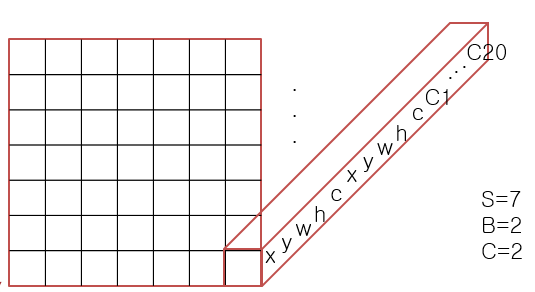
위 그림에서처럼 grid는 총 49(7*7) 개가 만들어진다. 하나의 bounding box는 5개의 값으로 표현되니까 bounding box가 2개면 총 10개가 된다. 거기에 class 개수만큼의 확률까지 합하면 하나의 grid는 총 30개(10+20)의 값을 가지게 된다.
2.1. Network Design
YOLO는 24개의 convolution layer와 2개의 fully connected layer로 구성된다. GoogLeNet에서 영감을 받아 1 * 1, 3 * 3 convolutional layer를 반복적으로 적용한다. YOLO의 경량화 모델인 Fast YOLO는 9개의 conv layer로 구성된다.
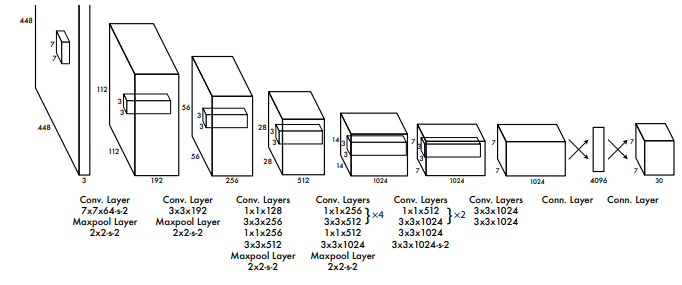
YOLO의 전체적인 구조는 위와 같다(s-2는 stride=2를 의미). Conv layer의 마지막 출력은 7 * 7 * 1024이고 FC layer를 지나면서 4096 → 1470(7 * 7 * 30)으로 출력된다. 1470차원의 특징을 7 * 7 * 30으로 reshape 하여 최종 출력 tensor의 크기는 7 * 7 * 30이 되는 것이다.
2.2. Training
Pretraining. 먼저 ImageNet으로 앞에 있는 20개의 Conv layer를 학습시킨다. 이때 20개의 Conv layer 뒤에는 Avg pooling layer와 FC layer가 있다.
Training. 그 후 Detection dataset으로 학습시킬 때는, pre-trained 된 20개의 Conv layer만 불러오고 뒤에 새로운 4개의 Conv layer와 2개의 FC layer를 추가하여 학습시킨다.
Activation. 마지막 layer에서는 선형 활성함수를 사용하고 나머지 모든 layer에서는 Leaky ReLU를 사용한다.
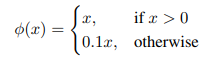
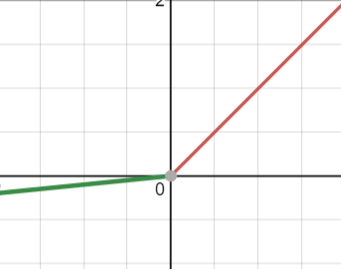
Leaky ReLU 활성함수는 위와 같다. 입력값이 0보다 작을 때 모두 0으로 변환해 주는 ReLU와 달리 입력값에 0.1을 곱한 다음 출력해 준다. 입력값이 0 이상인 경우는 그대로 반환한다.
Optimize(Loss) function. 목적함수로는 sum-squared error를 사용하는데, 이는 최적화하기 간단하지만 mAP를 높여야 하는 object detection task에 완전히 적합하지 않기 때문에 task와 맞춰주기 위해 몇 가지 조건을 추가해야 한다. 기존 sum-squared error를 사용했을 때 생기는 문제점은 다음과 같다.
- 일반적인 Object detection에서 생기는 문제로, 이미지 내에서 배경이 객체보다 차지하는 부분이 더 크기 때문에, Network가 background에 편향되게 학습될 수 있다.
- 또 다른 문제는 크고 작은 bbox를 모두 같은 비중으로 취급하게 된다는 것이다. 이것이 문제가 되는 이유는 큰 박스에서의 차이는 상대적으로 둔감하지만 작은 박스에서의 차이는 상대적으로 민감하기 때문이다.
아래 수식은 YOLO에서 사용하는 Loss function이다. 이를 살펴보면서 위 2가지 문제에 어떻게 접근했는지 살펴보자.
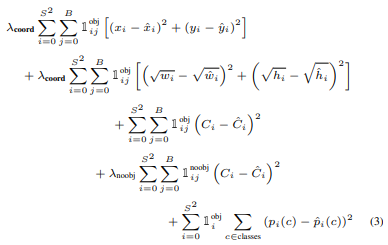
우선 각각의 값들을 설명하면
$\lambda_{coord}$ : Loss의 각 항에 대한 scale을 조절해 주는 상수이며 5이다.
$\lambda_{noobj}$ : 마찬가지로 scale을 조절해 주기 위한 상수이고 0.5이다.
$\sum_{i=0}^{s^2}$ : i는 grid cell의 인덱스이다. 총 $s^2$개의 grid cell이 만들어진다.
$\sum_{j=0}^{B}$ : j는 bounding box의 인덱스이다. 1개의 grid cell당 B개의 bounding box가 만들어진다.
$1^{obj}_{ij}$ : i번째 grid cell의 j번째 box안에 object가 있으면 1, 없으면 0을 반환한다.
$1^{noobj}_{ij}$ : 위와 반대로 object가 있으면 0, 없으면 1을 반환한다.
$x_i, y_i, w_i, h_i$ : 예측한 offset
$\hat {x_i}, \hat {y_i}, \hat{w_i}, \hat{h_i}$ : Ground-Truth offset
$C_i, \hat C_i$ : 각각 예측 confidence score, 타깃 confidence score를 의미한다. $C_i$는 0과 1 사이의 값을 가지고 $\hat C_i$는 object가 있거나 없거나 두 경우 중 하나이기 때문에 0과 1중 하나의 값을 갖는다.
$p_i(c), \hat p_i(c)$ : c 부류에 속할 확률과 타깃값이다. $p_i(c)$는 class 개수만큼 0과 1사이의 값을, $\hat p_i(c)$는 타겟 클래스에 대한 one-hot vector이다.
복잡해 보이는 Loss function이지만 주의해서 볼 부분은 다음과 같다.
- Grid cell 안에 object가 있는 경우와 없는 경우
a. object가 있는 경우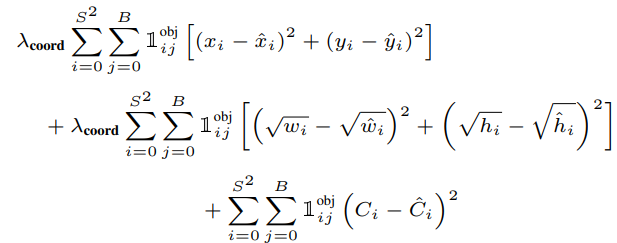
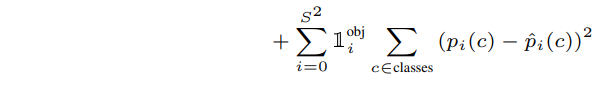
$1^{noobj}_{ij}$가 0이 되면서 4번째 항이 사라지게 된다. object가 있는 grid cell은 offset과 confidence, probability 모두 loss 계산에 이용된다.
b. object가 없는 경우
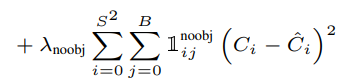
$1^{obj}_{ij}$가 모두 0이 되면서 위 항만 남게 된다. object가 없는 grid cell의 경우, bounding box의 좌표와 class probabiliy는 계산하지 않아도 되기 때문에, confidence score만 loss 계산에 이용된다.
- $\lambda$의 역할(문제점 1의 해결)
$\lambda_{coord}$와 $\lambda_{obj}$는 각각 객체가 있을 경우와 없는 경우에 곱해지는 Loss의 scale값이다. Object detection에서 대부분의 이미지는 객체가 아닌 부분(배경)이 객체인 부분보다 많기 때문에 객체에 더 가중치를 줘야 한다. 따라서 $\lambda_{coord}=5, \lambda_{noobj}=0.5$로 설정한다. - w, h에 제곱근을 씌운 이유(문제점 2의 해결)
큰 박스에서의 offset 차이는 작은 박스에서의 offset차이보다 둔감하다. 즉 작은 박스의 차이에 더 가중치를 두어 계산해줘야 한다. 이 문제는 제곱근을 씌워 해결한다.
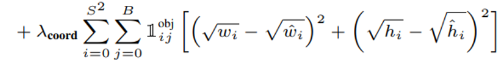
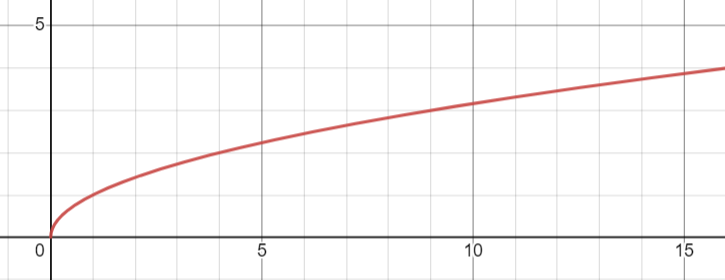
위 그래프는 $y=\sqrt x$인데, 큰 값의 규모를 작게 만들어주는 효과를 내준다.
예를 들어 $w_i = 64,\hat w_i = 49$이면 $(\sqrt w_i- \sqrt {\hat w_i})^2=1$이다.
반면, $w_i = 16,\hat w_i = 4$이면 $(\sqrt w_i- \sqrt {\hat w_i})^2=4$이다. 즉 large box의 차이는 상대적으로 작게, small box의 차이는 상대적으로 크게 만들어주는 효과를 취하게 되는 것이다.
하지만 어쨌거나 small box와 large box를 구분하여 weight를 달리해준다던가의 근본적인 해결책은 아니기 때문에, 근사적으로 해결했다고 볼 수 있다.
Training Setting.
- epoch : 135(1 epoch : 1e-3 → 1e-2, 75 epch : 1e-2, 30 epoch : 1e-3, 30 epoch : 1e-4)
- batch size : 64
- drop out : 0.5(after the first fc layer)
- data augmentation : random scaling and translations(0.2), exposure, saturation, HSV
2.3. Inference
YOLO는 하나의 이미지당 98개의 bounding box를 만들어낸다(B=2). 또한 single network만 훈련시키기 때문에 classifier-based method와 비교했을 때 test-time이 매우 빠르다.
Grid design은 bounding box를 예측하는 과정에서 공간적 다양성을 제한시킨다. 제한적인 grid에서 정해진 개수만큼의 bounding box만 생성하기 때문이다. NMS도 적용했는데, mAP를 약 2-3% 정도 증가시켰다.
2.4. Limitations of YOLO
YOLO는 하나의 grid당 2개의 bounding box만 만들어내기 때문에 공간적 제약이 있다. 이런 공간적 제약은 가까이 몰려있는 object들을 잘 탐지하지 못한다.
또한 새롭거나 일반적이지 않은 비율의 물체를 잘 탐지하지 못한다. YOLO는 여러 번의 down sampling을 거치기 때문에 다른 모델에 비해 상대적으로 coarse(조잡한) 특징을 사용하게 된다.
마지막으로 YOLO의 Loss function은 detection performance를 근사적으로 표현한 형태이다. 따라서 작은 박스와 큰 박스를 같은 error로 취급하기 때문에 localization이 부정확하다.
3. Comparison to Other Detection Systems
Deformable parts models(DPM). DPM은 분리된 pipeline을 sliding window 방식으로 학습시켰다. YOLO는 분리된 부분을 하나의 신경망으로 통합하였다. 이 네트워크는 특징 추출, bbox 예측, NMS을 동시에(한 번에) 수행하기 때문에 DPM보다 정확하고 빠르다.
R-CNN. R-CNN 등의 방법들은 RoI를 추출하는 데에 selective search와 같은 region proposal method를 이용하고 분류기로 SVM, bounding box prediction에 regressor를 사용한다. Selective search는 cpu 환경에서 구현되고 conv layer, svm, regressor의 3가지 학습 단계가 모두 분리되어 있기 때문에, 굉장히 시간이 오래 걸린다. 하나의 이미지를 예측하는 데에 약 40초 소요된다. 또한 하나의 이미지당 약 2000개의 proposal을 사용하는 R-CNN과 달리 YOLO는 98개의 bounding box를 예측한다.
Other Fast Detectprs. Fast, Faster R-CNN과 같이 R-CNN의 속도를 증가시킨 모델들은 selective search를 conv layer로 대체하였다. R-CNN에 비해 속도와 정확도 모두 상승했지만 real-time에 적용하기에는 아직 부족하다.
Deep MultiBox. Deep MultiBox는 R-CNN과 다르게 Bounding box를 예측하기 위해 single conv layer와 confidence score를 사용하지만 class-agnostic 하다는 단점이 있다. class-agnostic이라는 것은 사진 안에 개, 고양이 등 여러 종류의 객체가 있더라도 객체의 종류에 상관없이 위치만 검출한다는 의미이다.
OverFeat. 이 모델도 conv layer를 사용하고 sliding window 방식으로(RoI pooling처럼) feature의 size를 조절하지만 지역적인 정보밖에 사용하지 못한다.
MultiGrasp. MultiGrasp은 물체를 안전하게 들어 올리기 위한 무게중심을 찾는 방법이다. 물체의 이미지가 주어지면 x, y, theta, w, h를 예측한다. YOLO는 MultiGrasp의 구조를 기반으로 만들어졌는데, 이 task는 물체의 영역, 클래스를 예측하지 않기 때문에 object detecion에 비해 간단한 작업이다.
'Paper' 카테고리의 다른 글
| [논문 리뷰/요약]How to Read a Paper (0) | 2024.02.21 |
|---|---|
| [논문 리뷰/요약]A Survey of Modern Deep Learning based Object Detection Models(2) (0) | 2024.02.15 |
| [논문 리뷰/요약]A Survey of Modern Deep Learning based Object Detection Models(1) (3) | 2024.02.15 |
| [논문 리뷰/요약]Faster R-CNN (1) | 2024.02.09 |
| [논문 리뷰/요약]Fast R-CNN (2) | 2024.02.09 |

