
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- gsoc 2025
- 논문 요약
- grefcoco dataset
- mobilenetv1
- 딥러닝 엔트로피
- 딥러닝 목적함수
- gsoc
- res paper
- 에지 검출
- clip adapter
- 엔트로피란
- 1차 미분 마스크
- 객체 검출
- grefcoco
- object detection
- 원격 학습 안끊기게
- gres
- referring expression segmentation
- Object detection article
- google summer of code
- vlm
- blip-2
- 논문 리뷰
- E2E 자율주행
- clip
- 이미지 필터링
- gsoc 후기
- transfuser++
- TransFuser
- res
- Today
- Total
My Vision, Computer Vision
[논문 리뷰/요약]Faster R-CNN 본문
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
State-of-the-art object detection networks depend on region proposal algorithms to hypothesize object locations. Advances like SPPnet and Fast R-CNN have reduced the running time of these detection networks, exposing region proposal computation as a bottle
arxiv.org
Abstract
현대의 object detection network들은 region proposal algorithm(ex. selective search)에 의존한다. Fast R-CNN, SPPnet은 detection network의 running time은 줄였지만 region proposal computation은 여전히 bottle neck으로 남아있다. 이 논문에서는 Region Proposal Network를 도입하여 cost-free region proposals을 가능하게 한다. 이 방법으로 이미지 당 300개의 proposal만을 이용하여 SOTA를 달성한다.
1. Introduction
R-CNN의 region-based convolutional neural networks는 큰 계산 비용이 필요했지만 Fast R-CNN과 SPPnet이 그 부분을 크게 줄여주었다. 하지만 여전히 region proposal을 추출하는 과정은 bottleneck이다. (*bottleneck(병목) : 대부분의 시간을 차지함.)
Selective search 같은 방법은 CPU 환경이기 때문에 이미지 당 2초 정도 걸린다. quality와 speed에서 trade-off 하여 구현한 방법인 EdgeBoxes는 이미지당 0.2초 정도 걸리지만 여전히 네트워크 running time의 대부분을 차지한다.
이런 bottleneck 문제를 해결하기 위해 GPU 환경에서 Region Proposal Networks(RPN)을 구축했고 SPPnet, Fast R-CNN과 convolution layer를 공유할 수 있게 하여 이미지당 10ms 걸린다.
Fast R-CNN에서 convolution layer를 거치고 만들어진 feature map들을 region proposals에도 사용할 수 있었다. 몇 개의 추가적인 convolution layer를 추가하여 RPN을 구축했고 각각의 location에 대해 regress와 objectness scores를 동시에 수행한다.
pyramid of images, pyramid of filters를 사용하는 기존 방법들과 다르게 새로운 방법인 anchor boxes를 도입한다. anchor란 기존의 proposal에 scales, aspect ratios를 적용하여 정형화된 references를 만드는 것이다. 이 방법은 signle-scale images를 사용하기 때문에 running speed에 이점이 있다. RPN와 Fast R-CNN을 통합하기 위해 두 네트워크를 번갈아가며 fine tunning하는 방법을 사용한다.
RPN은 selective search와 비교했을 때 계산 부담이 적어 매우 빠르다.(10ms) 성능 또한 향상되었다.
2. Related Work
Object Proposals. 많은 method들이 있는데 그중 유사한 픽셀을 병합(super-pixel)하면서 찾는 방법인 Selective Search, CPMC, MCG가 있고, Sliding Windows 방법인 EdgeBoxed가 있다. 하지만 이런 Object proposal method들은 네트워크 외부 모듈로 취급되었다.
Deep Networks for Objedt Detection. R-CNN의 CNN은 end-to-end로 학습되지만 주로 분류기로서 작동한다. 마지막 B-box regressor부분을 제외하면 이 end-to-end로 학습되는 CNN layer에서는 객체의 bounds를 예측하지 않는다. 따라서 regressor의 정확도는 region proposal module에 크게 의존한다.
객체의 B-box를 예측하는 과정에 deep networks를 사용하는 몇 가지 방법이 있다. 그중 OverFeat Method는 fully conneted layer를 학습시켜 box의 좌표를 예측하게끔 학습되지만 single object에만 적용된다. 이후 fully connected layer는 다중 클래스 예측을 위해 convolution layer로 바뀐다. MultiBox method는 OverFeat의 single-box 방식을 일반화하여 class-agnostic box를 만들어낸다. Fast-RCNN은 shared convolutional featuers에서 detector를 end-to-end로 학습한다.
3. Faster R-CNN
Faster R-CNN은 2개의 모듈로 구성된다. 첫 번째 모듈은 region proposal을 만들어내는 deep fully convolutional network이고 두 번째 모듈은 만들어진 proposal을 사용하는 Fast R-CNN detector이다. 최종 모델은 두 가지의 모듈이 통합된 single model이다.
3.1. Region Proposal Networks
RPN(Region Proposal Network)는 any size image를 입력으로 받고, 사각형 object proposal과 objectness score를 출력한다. 최종적인 목표는 Fast R-CNN과 computation을 공유하는 것이기 때문에 두 개의 네트워크가 convolution layer의 한 부분을 공유한다고 가정한다. 실험을 위해 각각 5개, 13개의 shareable convolutional layer가 있는 ZF(Zeiler and Fergus) model과 VGG-16를 연구했다.
RPN에서 region proposal을 생성하기 위해 마지막 convolution layer에서 출력된 feature map에 대해 sliding window 방식을 적용한다. 이때 window는 n * n 크기이며 이 논문에서는 n=3을 사용한다. sliding window 방식(커널 연산)을 적용하여 feature map을 lower-dimensional feature로 매핑시킨다.(ZF : 256-d, VGG : 512-d) 이 feature는 두 개의 sibling fc layer(reg, cls)의 입력으로 들어간다. fc layer의 입력으로 만들어내기 위해 1 * 1 convolution을 사용한다. 이 과정을 VGG로 예를 들어 그림으로 살펴보면 다음과 같다.
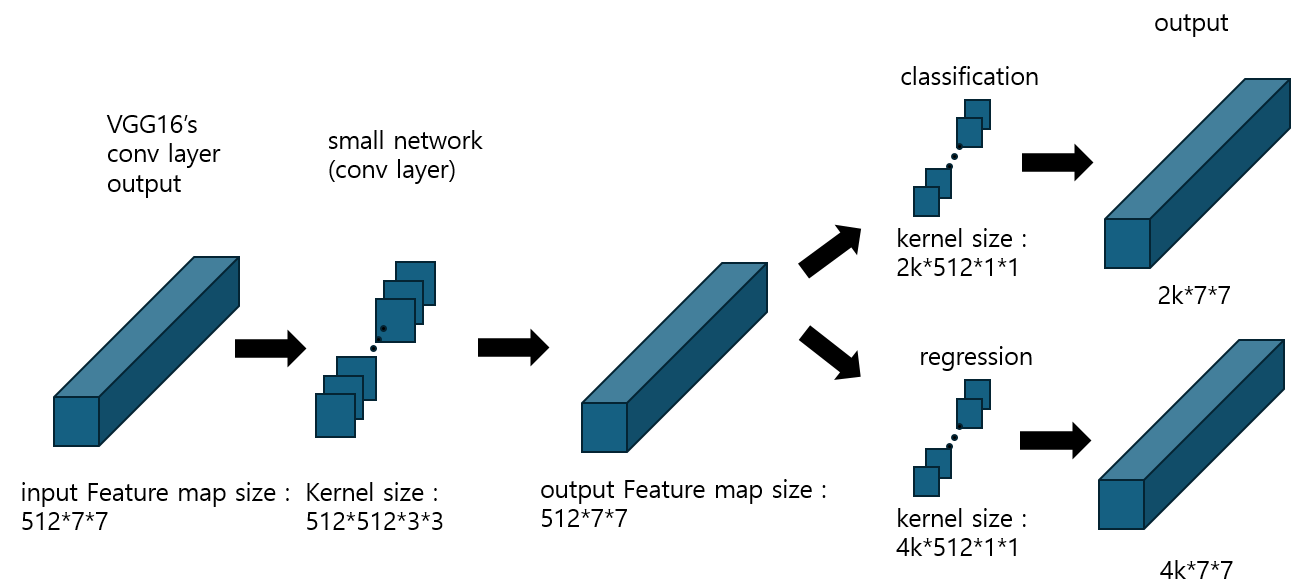
input feature map의 size는 VGG16 기준 512 * 7 * 7이다. 이 피쳐맵에 채널 수를 와 size를 그대로 유지하는 small network를 적용하여 512 * 7 * 7 크기의 Feature map을 출력한다. 출력된 Featuremap을 각각 classification과 regression에 해당하는 피쳐맵으로 만들어주기 위해 sibling conv layer를 적용해 준다.(Fast R-CNN의 sibling fc layer와는 다름) 이때 각각의 kerenl size는 2k * 512 * 1 * 1, 4k * 512 * 1 * 1이다. 최종적으로 만들어지는 두 개의 Feature map의 size는 각각 2k * 7 * 7, 4k * 7 * 7이다. 이제 k는 무엇인지, 왜 2k와 4k로 각각 출력되는지 알아보자.
3.1.1. Anchors
먼저 k는 Anchor box의 개수이다. 이 논문에서 실험의 결과로 k=9를 사용한다. 즉 피쳐맵의 한 픽셀에서 만들어지는 Anchor box의 개수가 9개라는 의미이다. 그리고 Classification과 Regression에 해당하는 피쳐맵의 채널은 2k, 4k이다. classification은 출력으로 특정 anchor box의 objectness probability를 출력한다. 이 anchor box가 객체인지 아닌지를 나타내는 확률값 2개이고 총 k개의 anchor box가 있으므로 2k 개의 채널을 출력하게 되는 것이다. 다음으로 Regression은 특정 anchor box의 좌표(x, y, w, h)를 출력하기 때문에 4k 개의 채널이 되는 것이다. 앵커의 종류는 scale과 aspect ratio에 따라 결정된다. 이 논문에서는 3개의 scale과 3개의 aspect ratio를 설정했기 때문에 3*3=9개의 anchor box가 만들어지는 것이다. 아래 사진은 논문에서 표현한 RPN의 구조이다.
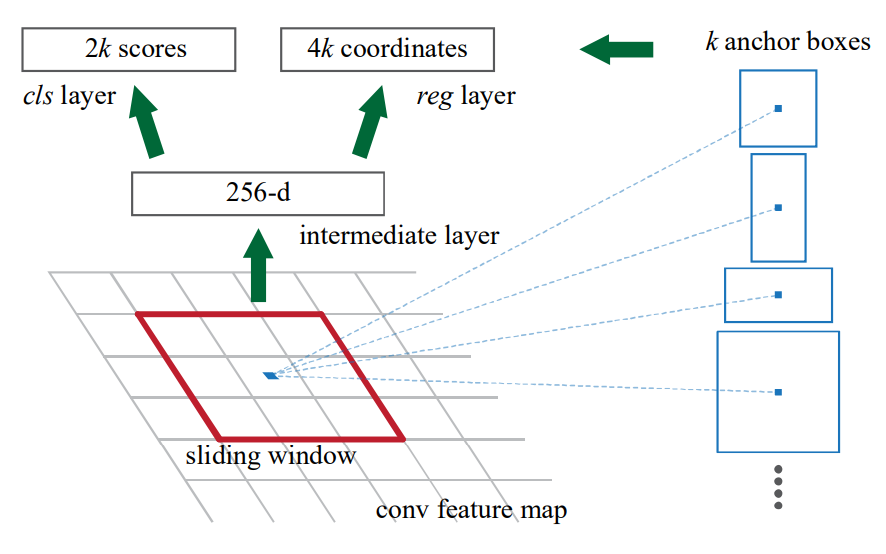
Translation-Invariant Anchors
translation-invariant란 변환 불변성을 의미한다. 이미지 내에서 객체가 이동해도 똑같은 결과를 출력한다는 것이다. 논문의 저자들은 이 변환 불변성을 RPN의 important property라고 말한다. 객체의 위치와 상관없이 모든 픽셀에 대해 k개의 anchor box가 만들어지고 anchor에 의해 계산되는 function(cls layer, reg layer)을 통과하기 때문이다. 반면 k-means로 800개의 anchor를 만들어내는 MultiBox method는 translation invariant를 갖지 않는다.
이러한 속성은 model의 size를 줄이는 데에도 기여한다. MultiBox의 경우 output 채널의 크기가 (4+1) * 800이지만 RPN의 output 채널은 (4+2) * k이다.(k=9) paprameter의 개수를 비교해 보면 RPN은 2.8 * 10^4개(512 * 512 * 3 * 3 + 6k * 512), MultiBox는 6.1 * 10^6개이다. 따라서 RPN은 PASCAL VOC와 같은 작은 데이터셋에 대해 과적합을 방지할 수 있다.
Multi-Scale Anchors as Regression References
객체의 multiple sacle을 고려하기 위한 두 가지 인기 있는 방식이 있는데 첫 번째는 image/feature pyramids이고 두 번째는 sliding window of multiple scale 방법이다. 첫 번째 방법은 이미지를 다양한 크기로 resize 한 후 feature map을 계산하기 때문에 시간이 오래 걸린다는 단점이 있다. 두 번째 방법은 다양한 size의 kernel을 적용하는 방식인데 pyramid filter라고도 할 수 있다. 두 번째 방법은 주로 첫 번째 방법과 함께 사용된다.
저자들은 논문에서 제시한 RPN을 pyramid of anchor라고 표현한다. RPN은 single scale 이미지와 single size의 kernel을 사용하기 때문에 비용면에서 효율적이라고 할 수 있다. multi-scale anchors의 핵심은 추가적인 scale의 이미지를 고려하지 않는다는 것이다.
3.1.2. Loss Function
RPN의 학습에서 각 anchor에 객체가 있는지 없는지에 대한 binary class label을 부여한다고 했다. 이때 positive label에는 두 종류가 있는데 첫 번째는 ground-truth box에 대해 가장 높은 IoU값을 가지는 anchor이고, 두 번째는 아무 gounrd-truth box에 대해 IoU가 0.7 이상인 anchor들이다. 당연히 하나의 ground-truth box는 여러 개의 anchor에 positive label을 부여할 수도 있다. 두 번째 조건으로 positive anchor를 결정하기 충분하지만 특정한 경우(positive가 하나도 없을 경우)를 대비하여 첫 번째 조건도 사용한다. ground-truth box와의 IoU가 0.3 이하인 anchor에는 negative label을 부여한다. negative와 positive에 모두 속하지 않게 되는 anchor는 학습에 사용되지 않는다. 이러한 정의에서, Fast R-CNN에 사용되는 Loss는 다음과 같다.
$$ L({p_i, t_i}) = \frac{1}{N_{cls}}\sum_i L_{cls}(p_i, p^*_i) \\ + \lambda \frac{1}{N_{reg}}\sum_i p^*_iL_{reg}(t_i, t^*_i). $$
$i$ : mini batch 내 anchor의 index
$p_i$ : i번째 anchor의 probability
$p^*_i$ : anchor가 positive면 1, negative면 0
$t_i$ : i번째 anchor의 예측된 4개 좌표
$t^*_i$ : ground-truth box의 4개 좌표
이때, $L_{cls}, L_{reg}$는 Fast R-CNN의 Loss를 따른다. classification의 Loss는 object와 non-object의 log loss로 계산되고 regression은 smoothed L1을 사용한다. 이때 $p^\_i L\{reg}(t_i, t^_\_i)$는 i번째 anchor가 negative일 때 0이 되므로 무시된다.
$N_{cls}, N_{reg}$는 일반화를 위해 나누어주는 항이고 $\lambda$는 두 loss항의 scale을 조정해 준다. 일반적으로 $N_{cls}$는 mini batch의 크기인 256이고, $N_{reg}$는 anchor의 개수인 약 2400이다. 이때 두 loss 항의 scale은 약 10배 차이이므로 $\lambda$는 10으로 두고 사용한다.
각 anchor마다 4개의 좌표를 가지고 있는데, 이 좌표들은 anchor가 만들어진 위치에 따라 나타내는 위치가 다를 것이기 때문에 모든 좌표에 대해 정규화를 적용해야 한다. 이 논문에서는 다음과 같은 방법으로 좌표를 정규화한다.
$$ t_x = (x-x_a)/w_a, t_y=(y-y_a)/h_a $$
$$ t_w = log(w/w_a), t_h=log(h/h_a), $$
$$ t^*_x=(x^*-x_a)/w_a, t^*_y=(y^*-y_a)/h_a, $$
$$ t^*_w = log(w^*/w_a), t^*_h=log(h^*/h_a), $$
$x$ : 예측된 x 좌표
$x_a$ : anchor의 x좌표
$x^*$ : Ground-truth 좌표
위 방법은 예측된 좌표와 Ground-truth 좌표를 anchor box의 좌표에 대해 정규화함으로써 B-box의 좌표를 근처에 있는 ground-truth 좌표에 회귀하는 문제로 생각할 수 있다.
모든 RoI에 대해 같은 가중치를 공유했던, 즉 같은 Regrssor를 학습했던 기존의 방법과는 다르게 각각의 scale과 aspect ratio를 담당하는 k개의 Regressor를 학습시킨다. 이 k개의 Regressor는 서로 가중치를 공유하지 않는다.
3.1.3. Training RPNs
하나의 이미지에서 만들어진 각각의 미니 배치는 많은 positive, negative anchor를 가지게 되는데, negative anchor의 비율이 많기 때문에 편향되어 학습될 수 있다. 따라서 loss를 계산하기 위해 하나의 이미지에서 1:1의 비율을 유지하며 256개의 anchor들을 랜덤 하게 추출한다. 만약 positive가 128개보다 적다면 negative로 채운다.
모든 새로운 레이어는 평균이 0, 표준 편차가 0.01인 가우시안 분포로 초기화하고 다른 모든 layer( shared convolutional layers)는 ImageNet으로 사전훈련된 layer를 사용한다. ZF net은 모든 layer를 훈련하고 VGG16 dms conv3_1부터 훈련한다. 60k의 미니 배치동안은 학습률 0.001을, 그 후 20k의 미니 배치는 0.0001의 학습률을 적용한다. momentum은 0.9, weight decay는 0.0005를 사용한다.
3.2. Sharing Features for RPN and Fast R-CNN
RPN와 Fast R-CNN을 독립적으로 훈련하게 되면 두 네트워크가 다르게 학습될 수 있기 때문에 convolution layer 공유하게 만들 수 있는 방법을 개발해야 했고 다음과 같은 세 가지 방법이 있다.
- Alternate training
- 이 방법은 먼저 RPN을 학습시킨 후 추출된 proposal로 Fast R-CNN을 학습시키는 방법이다. 뒤이어 학습된 Fast R-CNN은 RPN을 초기화하는 데 사용된다. 이러한 학습이 반복되면서 같이 학습하는 효과를 내게 한다.
- Approximate joint trainingproposal boxes’ coordinates에 대한 도함수(미분)가 무시된다는 것은 RoI pooling의 back propagation에서 B-box의 좌표에 대한 정보가 반영되지 않는다는 것이다. 그렇기 때문에 RoI 전과 후로 나누어 학습을 해주는 1번 방법을 채택한 것이다.
- 이 방법은 근사적으로 함께 학습시키는 방법이다. 함께 학습시킨다는 것은 RPN의 loss와 Fast R-CNN의 loss를 혼합하여 back propagation을 수행한다. 이 방법은 구현하기 쉽지만 proposal boxes’ coordinates에 대한 미분을 무시하기 때문에 1번 방법에 비해 근사한 값을 취한다고 볼 수 있다. 하지만 두 네트워크가 한 번에 학습되기 때문에 Alternate tarining과 비교했을 때 훈련 시간을 약 25-50% 감소시킨다.
- Non-approximate joint training
- Fast R-CNN의 RoI pooling layer는 입력으로 Feature map과 bounding box를 모두 입력으로 받기 때문에 이론적으로는 backpropagation에서 boundig box의 좌표에 대한 그래디언트도 계산되어야 한다. 이 부분은 논문의 주제를 벗어나기 때문에 논의하지 않는다.
4-Step Alternating Training
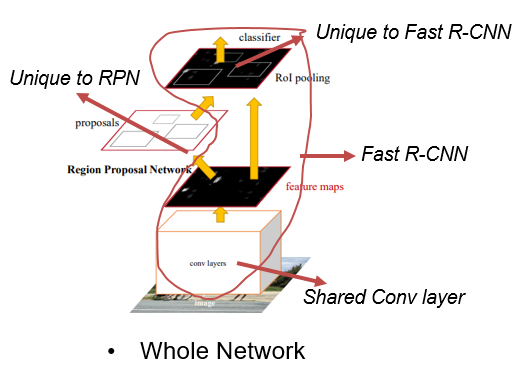
우선 Faster R-CNN의 전체 네트워크 구조는 위와 같다. 맨 밑에 있는 이미지가 input image이다. input image바로 위에 있는 convolution layer가 Shared Conv layer라고 하는 부분이다. VGG16은 13개의 convolution layer와 3개의 fully connected layer로 구성되어 있는데, 13개의 convolution layer만 가져와서 피쳐맵을 추출하는 데 사용한다. 이 추출된 피쳐맵이 RPN과 Fast R-CNN의 RoI Pooling의 입력으로 각각 들어가게 되는 것이다. 이 논문에서는 shared conv layer를 제외한 RPN만을 Unique to RPN이라고 한다. 또한 RPN과 shared conv layer를 제외한 Fast R-CNN, 즉 RoI pooling layer를 포함한 뒷단을 Unique to Fast R-CNN이라고 한다. 위에 그려진 빨간색 선에 해당하는 영역은 shared conv layer를 포함한 전체 Fast R-CNN을 가리킨다.
이 논문에서는 Alternating optimization을 통해 학습하는 방법인 4-step training algorithm을 사용한다(위 1번 방법과 같음). 4개의 step은 다음과 같다.
- Train the RPN
- 이 네트워크는 ImageNet으로 pre-trained 된 네트워크를 사용하며 region proposal task에서는 end-to-end로 학습된다.
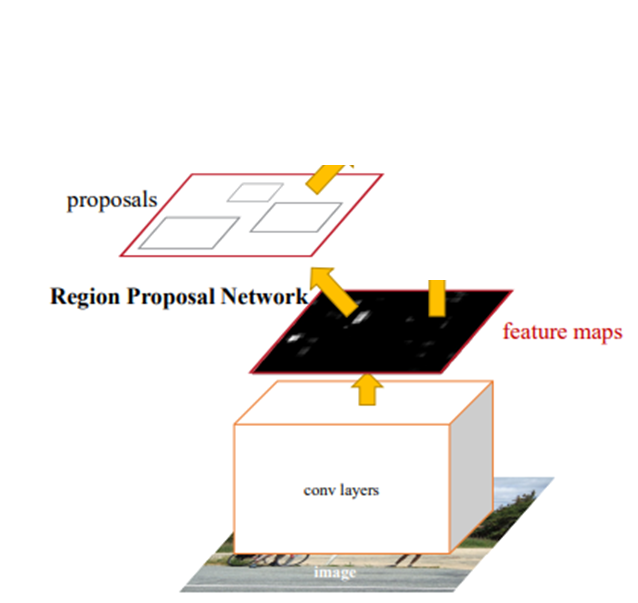
위 그림은 ImageNet으로 사전학습된 shared conv layer와 RPN만 나타낸 것인데, 이 부분만 end-to-end로 학습하는 것이다. RPN은 3.1.2절의 Loss 함수를 사용하고 3.1.3절의 방법으로 학습한다.
- Train Fast R-CNN using the proposals generated by the step-1 RPN
- step 1에서 학습된 RPN으로부터 추출된 proposal을 이용하여 Fast R-CNN을 학습시킨다. 이 부분에서는 두 개의 네트워크가 feature map은 공유하지만 convolution layer를 공유하지 않는다.
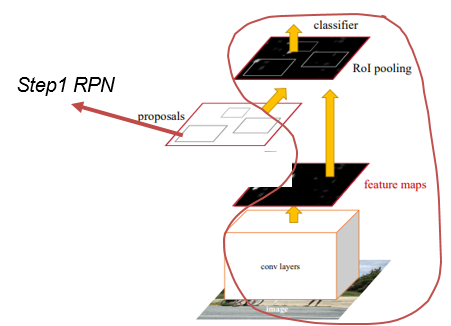
다시 말하면 위 사진에서의 shared conv layer는 ImageNet으로 사전 훈련된 네트워크로 초기화한 것이지만, step1에서 학습된 shared conv layer와는 다른, 새롭게 초기화된 conv layer이다. step2에서는 RPN을 제외한 전체 Fast R-CNN이 학습된다.- Use the detector network(Fast R-CNN) to initialize RPN training
- 이 단계에서는 Fast R-CNN을 통해 RPN을 초기화하지만 step2에서 학습된 shared convolutional layer는 고정하고 RPN을 fine-tuning 한다. 이 단계에서 두 네트워크가 convolution layer를 공유하게 되는 것이다.
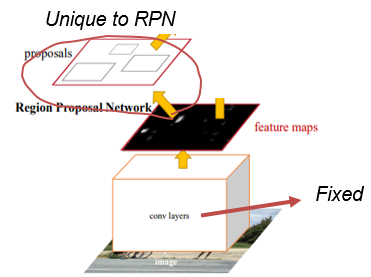
step2에서 학습된 shared conv layer와 step1에서 학습된 RPN을 불러와서 RPN을 다시 한번 더 학습시킨다.
- Keeping the shared convolutional layers fixed, we fine-tune the unique layers of Fast R-CNN
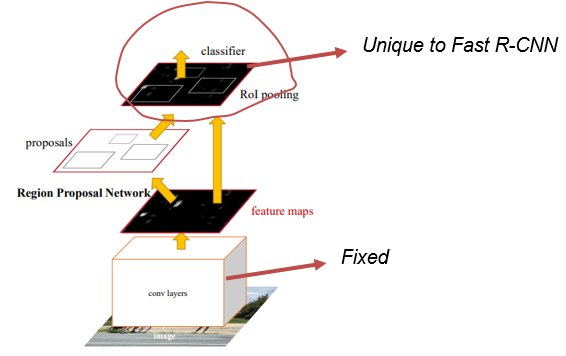
shared convolutional layers는 고정한 채로 Fast R-CNN에만 있는 layer를 fine-tunning 한다.
이 4가지 순서를 반복하며 RPN과 Fast R-CNN을 학습시킨다.
3.3. Implementation Details
앵커에 크기 조절에 사용하는 3개의 스케일은 128, 256, 512이고 3개의 aspect ratio는 1:1, 1:2, 2:1이다. 이 solution은 multi sacle을 예측하기 위해 image pyramid나 filter pyramid를 사용하지 않아도 되기 때문에 실행 시간을 단축할 수 있다. 또한 cross-boundary anchor를 다루는 것도 중요한데, 일반적으로 1000 * 600 이미지에서 60 * 40 * 9개의 anchor가 만들어진다. 이때 boundary-crossing outliers를 학습에 반영하게 되면 학습이 수렴되지 않을 수 있다. 따라서 학습에 영향을 미치지 않게 처리해야 한다. 또한 RPN에서 출력된 Proposal들은 서로 겹칠 수 있는데, 이러한 중복을 제거하기 위해 NMS 알고리즘을 사용한다. 임계 IoU값으로 0.7을 사용하여 하나의 이미지당 약 2000개의 proposal만 남긴다. NMS는 proposal을 제거하지만 성능에는 영향을 끼치지 않는다. 또한 NMS를 수행한 후 top-N개의 proposal만 남긴다. Fast R-CNN을 훈련할 때 N=2000이지만 test-time에서는 다르다.
'Paper' 카테고리의 다른 글
| [논문 리뷰/요약]How to Read a Paper (0) | 2024.02.21 |
|---|---|
| [논문 리뷰/요약]A Survey of Modern Deep Learning based Object Detection Models(2) (0) | 2024.02.15 |
| [논문 리뷰/요약]A Survey of Modern Deep Learning based Object Detection Models(1) (3) | 2024.02.15 |
| [논문 리뷰/요약]YOLO v1 (1) | 2024.02.09 |
| [논문 리뷰/요약]Fast R-CNN (2) | 2024.02.09 |

