
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 논문 리뷰
- 이미지 필터링
- blip-2
- google summer of code
- res paper
- Object detection article
- E2E 자율주행
- vlm
- gres
- gsoc 2025
- grefcoco
- 엔트로피란
- transfuser++
- grefcoco dataset
- 딥러닝 목적함수
- referring expression segmentation
- gsoc
- object detection
- 1차 미분 마스크
- 원격 학습 안끊기게
- 에지 검출
- 딥러닝 엔트로피
- clip adapter
- res
- clip
- 논문 요약
- TransFuser
- gsoc 후기
- 객체 검출
- mobilenetv1
- Today
- Total
My Vision, Computer Vision
[논문 리뷰/요약]A Survey of Modern Deep Learning based Object Detection Models(2) 본문
[논문 리뷰/요약]A Survey of Modern Deep Learning based Object Detection Models(2)
gyuilLim 2024. 2. 15. 17:14A Survey of Modern Deep Learning based Object Detection Models
Object Detection is the task of classification and localization of objects in an image or video. It has gained prominence in recent years due to its widespread applications. This article surveys recent developments in deep learning based object detectors.
arxiv.org
이전 글에서 이어집니다.
A Survey of Modern Deep Learning based Object Detection Models 논문 리뷰/요약(1)
A Survey of Modern Deep Learning based Object Detection Models Object Detection is the task of classification and localization of objects in an image or video. It has gained prominence in recent years due to its widespread applications. This article survey
mvcv.tistory.com
이 논문은 Object Detection 분야 딥러닝 기반의 현대 모델들의 발전 과정을 다룬다. 또한 Object detecion 분야의 표준이 되는(benchmark) Dataset과 평가 지표(Evaluation metrics), 주로 사용되는 backbone architecture와 edge device에서 사용되는 가벼운(Lightweight) 분류 모델에 대해 간단히 비교 분석한 결과를 보여준다.
Two-Stage Detectors
R-CNN(The Region-based Convolutional Neural Network, 2013)
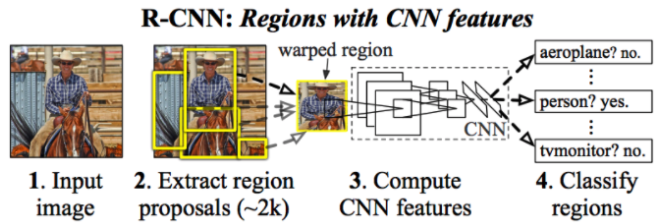
- Selective search로 2000개의 proposal 추출
- 추출된 2000개의 RoI가 모두 CNN을 거친 다음 SVM과 regressor로 나뉜다.
- SVM은 classifier의 역할을, regressor는 bounding box를 예측한다.
- R-CNN은 여러 단계의 훈련 과정을 거쳐야 하는 번거로움이 있고 test time이 하나의 이미지 당 47초 정도로 매우 느리다.
SPP-Net(Spatial Pyramid Pooling, 2014)
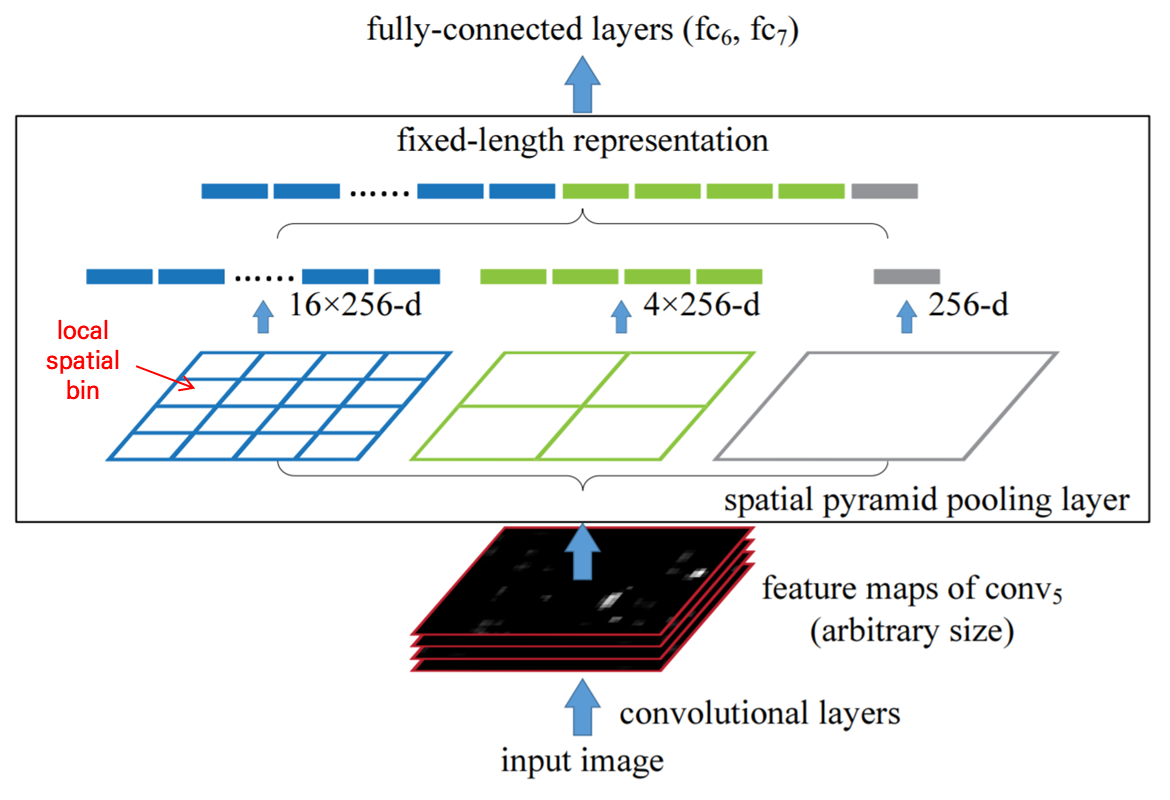
- Fully connected layer는 고정된 크기의 입력을 요구하기 때문에 입력 특징맵의 크기를 조절해야 하는데, SPP layer를 사용하여 해결했다.
- Selective search는 여전히 region proposal을 생성하기 위해 사용한다.
- SPP-Net은 R-CNN에 비해 빠르고 정확하지만, 여전히 여러 단계의 훈련 과정을 거쳐야 하는 번거로움이 남아있다.
Fast R-CNN(2015)

- 여러 단계로 나누어 학습해야 했던 R-CNN, SPP-Net과 다르게 Fast R-CNN은 end-to-end 학습 과정을 구현했다.
- CNN에서 출력된 feature map에서 selective search로 추출된 proposal들을 모두 RoI pooling 한다.
- 이후 2개의 FC층으로 나뉘는데, 하나는 classifier, 다른 하나는 regressor이다.
- 정확도 향상과 더불어 R-CNN에 비해 속도가 약 146배 증가했다.
- Region proposal을 추출하는 데 CNN을 사용하지 않았다.
Faster R-CNN(2015)

- Fast R-CNN이 속도를 증가시키긴 했으나 아직 실시간에 미치지 못함.
- Faster R-CNN은 RPN(Region Proposal Network)를 도입하여 porposal을 추출하는 데에 CNN을 사용했다.
- Anchor box를 도입하여 scale, aspect ratio 조정
- 기존 Sota 모델에 비해 정확도가 3% 향상됐고, region proposal method의 bottleneck을 해결했다.
FPN(Feature Pyramid Network, 2016)

- 다양한 scale의 feature를 사용함으로써 작은 객체에 대한 검출을 향상한다.
- FPN을 ResNet-101 기반 Faster R-CNN의 RPN으로 사용한다.
- FPN은 모든 스케일의 고수준 특징을 사용한다.
Feature map의 크기가 작아질수록 작은 크기의 객체들은 더욱 작아지기 때문에, 여러 scale의 feature map을 사용하게 되면 작은 객체에 대한 검출 능력이 향상하게 된다.
R-FCN(Region based Convolutional Network, 2016)

- 모든 layer가 convolution layer로 구성되어 있기 때문에 다른 two-stage 검출기와 다르게 거의 모든 연산을 공유한다.
- 공간적인 정보를 담고 있는 position-sensirive score map을 사용한다.
- Faster R-CNN과 유사하게 4-step 학습 방식이다.
- ResNet-101을 backbone으로 사용하여 feature map 추출
- RPN으로 RoI proposal 추출
- Classifier와 regressor로 분기
- 정확도는 많이 향상되지 않았지만 속도는 2.5 - 20배 향상되었다.
Mask R-CNN(2017)
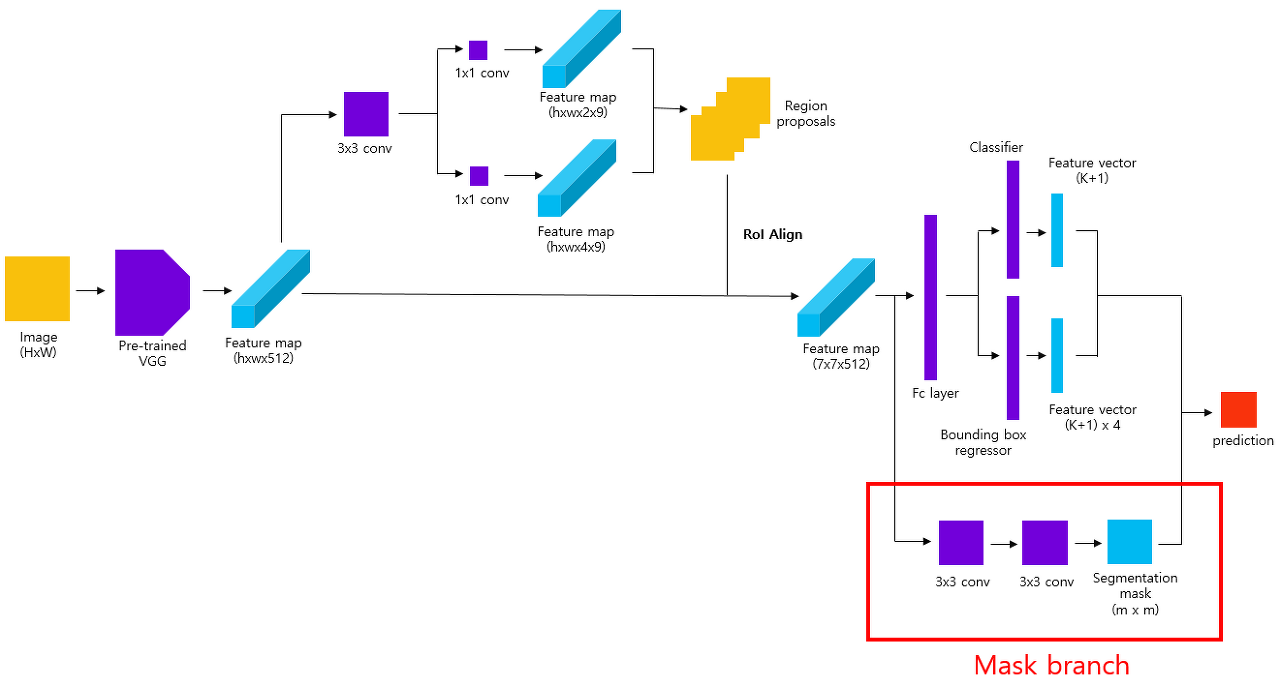
- Instance segmentation을 위해, Faster R-CNN에 segmentation을 담당하는 mask branch를 추가한 형태.
- RoI pooling layer 대신 RoIAlign layer 사용
- backbone으로 ResNeXt-101을 FPN과 사용한다.
- 전반적인 학습 과정은 Faster R-CNN과 비슷하다.
- 정확도는 향상됐지만 아직 real-time에 미치지 못한다.
RoIAlign이란 RoI pooling을 더 디테일하게 구현한 메서드이다. RoI poolin은 RoI를 projection 하는 과정에서 float type을 int type으로 형변환한다. 이때 quantization error가 발생하는데, 이 문제를 해결한 것이 RoIAlign이다.
DetectoRS(2020)

- micro, macro 두 개의 level에서 ‘Looking and thinking twice’ 메커니즘.
- Macro level
- FPN에 extra feedback connection을 추가한 RFP(Recursive Feature Pyramid) 형태
- FPN의 출력은 ASPP(Atruos Spatial Pyramid Pooling) layer를 거쳐 다시 FPN의 입력으로 들어가게 되고, 첫 번째 output과 두 번째 output을 fusion 하여 최종 predict를 도출한다.
- Micro level
- SAC(Switchable Atrous Convolution)을 이용하여 이미지를 두 개의 스케일(원본, 확대)을 본 후 더 좋은 스케일을 선택한다.
- SOTA를 달성했지만 4 fps로, real-time에 미치지 못한다.
Two stage Detector 요약
Classifier와 Regressor를 따로 학습시키기 때문에 Single stage에 비해 높은 정확도를 가지지만 그만큼 학습 과정이 번거롭기 때문에 시간이 오래 걸리게 되어 real-time에 미치지 못한다.
Single Stage Detectors
YOLO(You Only Look Once, 2015)
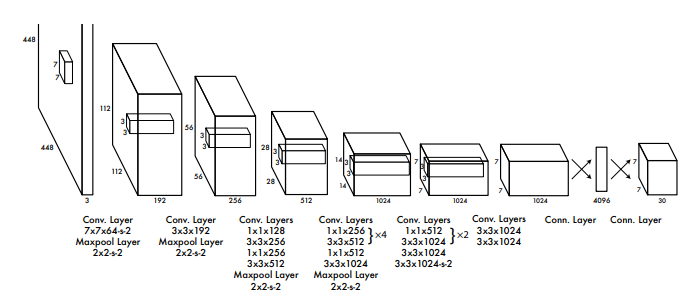
- 기존 two-stage 모델들은 object detection을 도출된 candidate 중에서 객체와 배경을 구별하는 classification 문제로 생각했지만, YOLO는 regression 문제로 보았다.
- 이미지를 S * S개의 grid로 나눈 후 각 grid cell마다 여러 개의 bounding box와 confidence score를 예측한다.
- 당시 다른 single stage, real time 모델에 대해 정확도와 성능 모두 넘어섰다.
- 작은 객체, 여러 객체가 몰려있는 경우에 취약하지만 이후 version의 YOLO에서 해결됐다.
SSD(Single Shot MultiBox Detector, 2015)
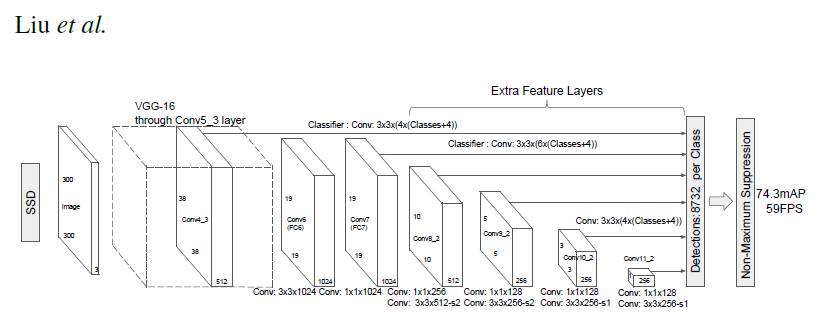
- Single stage 모델 중 real-time에 비슷한 속도를 가지면서도 two stage 모델과 비슷한 성능을 가지는 첫 번째 모델.
- Ground truth와 default box의 IoU를 비교하여 매칭하는 MultiBox와 유사한 학습 과정.
- YOLO와 Faster R-CNN 보다 빠르고 정확하지만 작은 객체에 대한 약점이 있다.
YOLOv2 and YOLO9000(2016)

- Batch normalization 등 여러 가지 technique들 결합했다.
- 속도와 정확도 모두 향상됐고 더 적은 paramter를 가진다.
RetinaNet(2017)

- 하나의 이미지 내에서 객체의 비율보다 배경의 비율이 훨씬 크기 때문에 학습이 비효율적으로 진행될 수 있다.
- 이를 해결하기 위해 RetinaNet의 저자는 cross entropy의 변형인 Focal loss를 제시했다.
- Two stage detector에 비해 향상된 정확성과 속도를 달성했다.
YOLOv3(2018)
- Feature extractor 부분을 larger Darknet-53 모델 사용
- Data augmentaion, multi-scale training, batch normalization 등 다양한 method를 추가로 적용
- 이전 버전보다 속도 향상은 됐지만 별다른 구조적 변화는 없고, SOTA에 미치지 못하는 정확도를 보인다.
CenterNet(2019)

- Bounding box의 center(point)를 예측하는 방식으로 학습.
- 입력 이미지가 FCN을 거쳐 heat map을 생성한 후 convolution layer에 통과한 후 point를 예측한다.
- Bounding box가 아닌 center poing를 예측하기 때문에 NMS는 사용하지 않는다.
EfficientDet(2019)

- EfficientDet은 EfficientNet의 발전형이다(EfficientNet은 width, depth, resolution 3가지의 scale을 조절하는 모델).
- NAS-FPN을 개선한 BiFPN을 도입했다. 또한 Backbone, BiFPN, class/box network의 scale을 조절할 수 있는 복합 계수를 도입했다.
- 이전 검출기들에 비해 더 좋은 성능과 속도 향상을 이루었다.
YOLOv4(2020)
- YOLOv4는 여러 가지 method들을 두 가지로 분류했는데, 첫 번째는 “Bag of freebies”로 훈련 시간은 증가시키지만 추론 시간은 증가시키지 않는 방법, 두 번째는 “Bag of Specials”로 추론 시간에만 영향을 주는 방법이다.
- Bag of freebies : Data augmentation, regularization methods, class label smoothing, CIoU-loss, Cross mini-batch Normalzation(CmBN), etc.
- Bag of Specials : Mish activation, Cross-stage partial connections(CSP), SPP-Block, etc.
- YOLOv4는 multi GPU를 사용하는 다른 모델들과 달리 single GPU에서도 훈련이 가능하다. 또한 Real-time detector 중 SOTA를 달성했고, EfficientDet에 비해 두 배 정도 빠르다.
Swin Transformer(2021)
- 기존 CNN에서는 context의 중요성의 부재가 있었다.
- Swin Transformer는 vision task에도 transformer 기반 backbone을 제공한다.
- Input image를 여러 개의 patch로 나눈 후 임베딩하여 벡터로 변환한다. 그 후 multi-head self-attention이 적용된다.
- MS-COCO dataset에서 SOTA를 달성했지만 CNN 모델들에 비해 많은 parameter를 가진다.
6. LIGHTWEIGHT NETWORKS
높은 정확도를 도출하는 대부분의 모델들은 과도한 컴퓨팅 자원을 요구하기 때문에 모바일등의 edge device 등에 적용하기 어렵다. 따라서 pruning, quantization, distillation 등의 method로 edge devcie에서도 좋은 성능을 내는 모델을 만들기 위한 연구가 진행되었다.
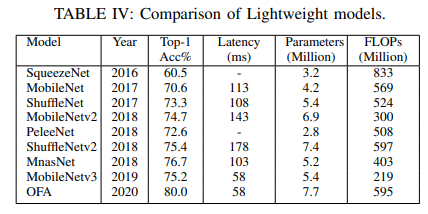
SqueezeNet(2016)
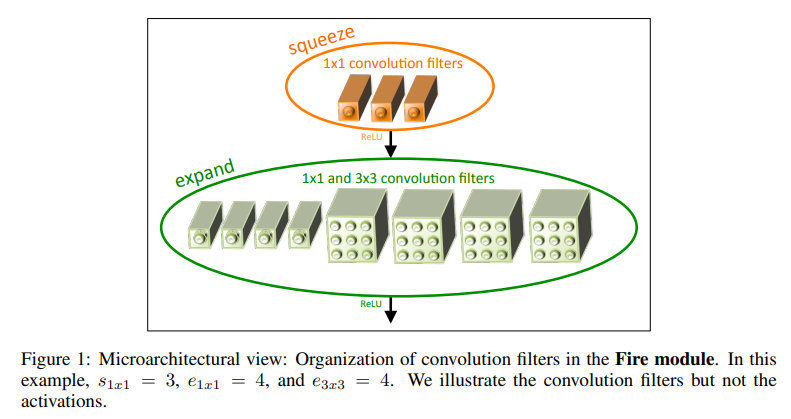
- SqueezeNet은 3가지 접근 방법으로 모델을 경량화하면서 성능을 증가시켰다.
- 3_3 fileter를 *11로 대체,*_ 입력 채널 수 감소, 풀링 레이어를 네트워크 뒷단에 배치
- 1_1으로 채널 수를 줄이고 1_1, 3*3으로 다시 채널수를 증가시키는 연산을 통해 모델의 paramter의 개수를 감소시킨다.
- AlexNet에 비해 크기가 약 510배 작지만 정확도는 거의 그대로 유지한다.
MobileNets(2017)

- Depthwise Separable convolution을 사용하여 모델의 paratmer를 감소시켰다.
- 하이퍼 파라미터로 너비 배율과 해상도 배율을 사용했다.
- MobileNet은 다양한 응용 분야에 활용될 수 있다. 하지만 구조가 단순하고 선형적이어서 gradient flow가 적은 문제가 있었다.
ShuffleNet(2017)
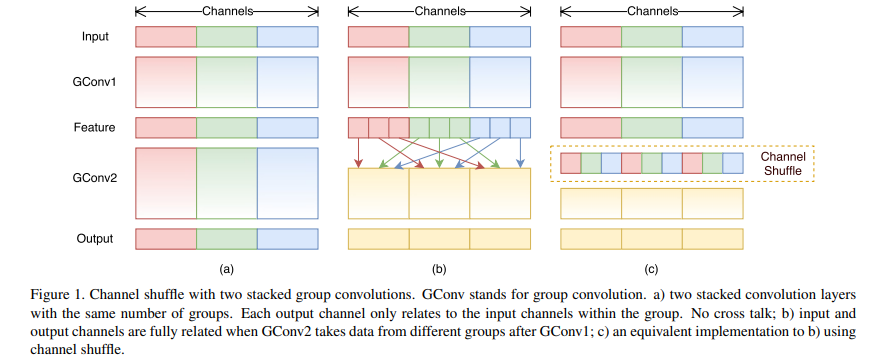
- Group convloution 연산을 한 후 group당 채널을 일정하게 섞는 방법을 적용
- 그룹의 개수와 모델의 크기를 조절하는 scaling factor를 조절한다.
- ShuffleNet은 모델의 크기를 더욱 감소시켰음에도 기존 경량화 모델의 성능을 능가했다.
MobileNetv2(2018)

- 모델의 정확도를 유지하면서 경량화시키기 위해 채널을 줄이고 다시 늘려주는 residual block과는 반대로 채널을 늘려주고 다시 줄여주는 Inverted residual block을 사용했다.
- MobileNetv2를 backbone으로 사용한 SSDLite 모델은 매개변수를 8배 정도 감소시킨다.
PeleeNet(2018)

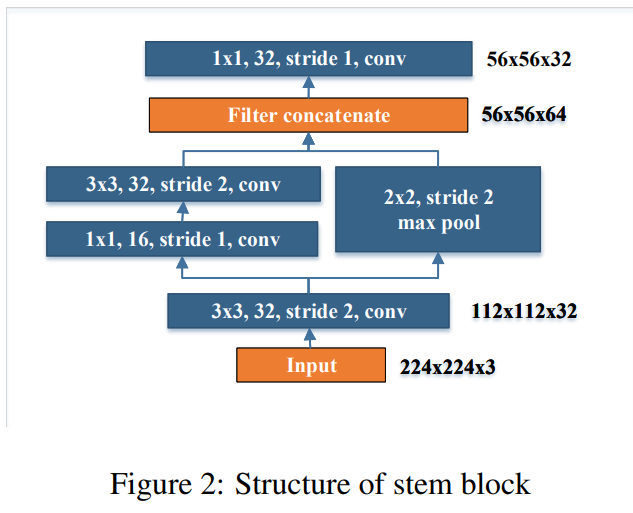
- 기존 dense layer를 수정한 2-way dense layer 사용
- Feature map의 size를 줄여주는 stem block 추가
- 위 방법들을 SSD에 적용한 Pelee라는 검출기 제안
- 간단한 디자인이 전체적인 성능에 큰 차이 만들어낼 수 있다는 것을 보여준다.
ShuffleNetv2(2018)

- 위와 같은 구조로 네트워크를 구성한다. 왼쪽 그림은 일반 convolution layer이고 오른쪽 그림은 pooling layer이다.
- FLOP과 같은 연산량이 아닌 속도와 지연 시간 등 시간과 직접적으로 관련된 수치를 지표로 사용했다.
- ShuffleNetv2는 적은 FLOP으로 우수한 성능을 보여주었고 비슷한 복잡도의 모델들을 능가했다.
MnasNet(2018)
- NAS(Neural Architecture Search)를 통해 모바일 환경에서도 사용 가능한 구조를 찾는다.
- RNN 기반 강화 학습 에이전트를 컨트롤러로 사용
- MobileNetv2보다 거의 2배 빠르면서 더 높은 정확도를 보이지만 훈련할 때 천문학적인 컴퓨팅 자원이 필요하다.
MobileNetv3(2019)
- MnasNet과 비슷한 방법이 사용된다. NetAdapt에 의해 최적화된다.
- ReLU와 hard swish를 혼합하여 사용하여 계산 비용을 감소시켰다.
- 이전 버전들보다 약 35% 빠르면서 더 높은 정확도 달성
Once-For-All(OFA, 2019)
- 모든 매개변수가 최댓값으로 설정된 가장 큰 네트워크가 훈련된다.
- 그 후 값을 줄여가면서 모델의 크기를 세밀하게 조정한다.
- ImageNet top-1 acc로 SOTA를 달성했고 LPCVC에서 우승했다.
7. COMPARATIVE RESULTS
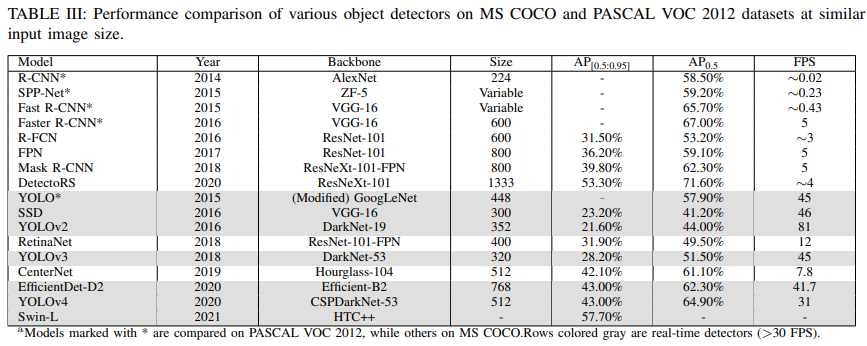
- MS COCO, PASCAL VOC 2012 데이터셋에 대한 검출기 성능 비교
- Lightweight model 비교
- MS COCO 데이터셋에 대한 검출기 성능 비교 시각화(등장 시기에 따른 성능)

8. FUTURE TRENDS
- AutoML(Automatic Machine Learning)
- 활발히 성장하고 있지만 이 분야는 여전히 초기 단계이고 많은 자원을 필요로 한다.
- Lightweight detectors
- 여전히 정확도에서 50% 이상 부족하지만 연구가 진행되면서 작고 효율적이면서도 정확한 모델이 등장하게 될 것이다.
- Weakly supervised/few shot detection
- Object detection의 annotation data는 만드는데 많은 비용이 걸리기 때문에 이러한 비용을 줄일 수 있는 weakly supervised 학습 또한 요구될 것이다.
- Domian trasfer
- 훈련된 모델의 재사용성과 높은 정확도를 달성하기 위해 필요하다.
- 3D object detection
- 이 분야는 자율 주행에 중요한 문제이다. 안전과 관련된 문제이기 때문에 높은 정확도가 필요하다.
- Object detection in video
- Object detection은 Image 단위로 수행되기 때문에 이미지 간의 상관관계가 부족하다. 프레임 간의 관계를 사용하는 것은 여전히 열린 문제이다.
9. CONCLUSION
지난 10년 동안 object detection 기술은 계속 발전해 왔지만 여전히 성능 면에서는 포화 상태에 도달하지 못했다. 또한 모바일, 임베디드 등 에지 시스템에 적용하기 위한 경량화된 모델의 필요성 또한 증가하고 있다. 자료에서처럼 현재까지는 Swin Transformer가 가장 정확한 감지기이지만 더 정확하고 빠른 감지기가 등장할 것이다.
'Paper' 카테고리의 다른 글
| [논문 리뷰/요약]SSD: Single Shot MultiBox Detector (0) | 2024.02.22 |
|---|---|
| [논문 리뷰/요약]How to Read a Paper (0) | 2024.02.21 |
| [논문 리뷰/요약]A Survey of Modern Deep Learning based Object Detection Models(1) (3) | 2024.02.15 |
| [논문 리뷰/요약]YOLO v1 (1) | 2024.02.09 |
| [논문 리뷰/요약]Faster R-CNN (1) | 2024.02.09 |

