
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- gres
- mobilenetv1
- 원격 학습 안끊기게
- Object detection article
- 논문 요약
- referring expression segmentation
- vlm
- gsoc 후기
- E2E 자율주행
- clip adapter
- 논문 리뷰
- clip
- google summer of code
- transfuser++
- 딥러닝 엔트로피
- grefcoco dataset
- 객체 검출
- 이미지 필터링
- 에지 검출
- res paper
- 1차 미분 마스크
- grefcoco
- 엔트로피란
- gsoc
- gsoc 2025
- blip-2
- TransFuser
- res
- 딥러닝 목적함수
- object detection
Archives
- Today
- Total
My Vision, Computer Vision
[논문 리뷰/요약]MobileNetV2: Inverted Residuals and Linear Bottlenecks 본문
MobileNetV2: Inverted Residuals and Linear Bottlenecks
In this paper we describe a new mobile architecture, MobileNetV2, that improves the state of the art performance of mobile models on multiple tasks and benchmarks as well as across a spectrum of different model sizes. We also describe efficient ways of app
arxiv.org
Abstract
- MobileNet V1의 성능을 개선
- Object detection에 효율적인 적용 방법 SSDLite 소개
- Semantic segmentation 모델 Mobile DeepLabv3 구축 방법 소개
- 정확도와 연산량, 지연시간과 파라미터 사이의 균형을 평가했다.
1. Introduction
- 현대, 성능이 높은 신경망 모델은 모바일, 임베디드 환경에서 높은 계산 자원이 필요하다.
- 이 논문에서는 위와 같은 분야에서의 활용을 목적으로 정확도를 동일하게 유지하면서 연산량과 메모리 양을 감소시켰다.
- 이번 주요 기여는 inverted residual with linear bottleneck 이다.
- 저차원의 채널의 입력을 받아 고차원으로 투영시킨 후 필터링을 거쳐 다시 저차원 채널로 투영하는 구조.
- 메모리 사용량을 크게 줄였기 때문에 임베디드 하드웨어 디자인에서 주 메모리의 액세스 필요성이 줄어들었다.
2. Related Work
- 최근 연구에서 하이퍼 파라미터 최적화, 네트워크 가지치기, 연결 학습과 같은 다양한 방법이 시도되었다.
- 또한 유전 알고리즘, 강화 학습과 같은 방법도 등장했지만 이러한 방법들은 네트워크를 매우 복잡하게 만드는 단점이 있었다.
- MobileNet은 많은 연산량을 필요로 하지 않으면서 Sota 성능을 달성한다.
3.1. Depthwise Separable Convolutions
- MobileNetv1에서 제시한 Depthwise Separable Convolutions 방법은 핵심이고 v2에서도 여전히 사용했다.
Manifold
- Linear Bottlenecks에 manifold라는 개념이 등장하는데, '다양체'를 뜻하는 단어이다.
- 딥러닝, 데이터 사이언스에서 manifold란, '데이터가 표현되는 공간', 즉 특징맵을 의미한다.
- Data manifold 학습이란? 고차원의 데이터를 더 잘 표현하는 subspace의 데이터가 존재 할 것이라는 가정하에 학습을 진행하는 방법이다.

스위스 롤 - 위 그림에서 Roll처럼 표현된 데이터가 있다. 만약 두 점 사이의 거리를 구한다고 할 때, 고차원의 데이터보다 저차원의 데이터에서 거리를 더 잘 표현하는데, 이를 manifold라 한다.
3.2. Linear Bottlenecks
- manifold는 저차원 하위공간(low-dementional subspace)에 임베딩될 수 있는 것으로 가정되어 왔다.
- 즉 뉴럴 네트워크의 manifold는 저차원의 subspace로 매핑이 가능다는 것이다.
- 이런 관점에서 manifold가 ReLU를 통과하고 나서 0이 되지 않았다면, linear transformation(선형 변환) 연산을 거친 것이라고 할 수 있다.(ReLU는 0 이상일 때 y=x이므로)
- 네트워크를 거치면서 저차원으로 매핑되는 연산이 계속 되는데, ReLU는 양수의 값은 단순히 그대로 전파하므로 manifold 상의 정보를 그대로 유지한다고 볼 수 있다.
- 즉, 차원은 줄이되 manifold 상의 중요한 정보들을 그대로 유지하는 것이 핵심이다.
3.3. Inverted residuals
- MobileNet V1의 DW convolution은 Depthwise → pointwise 순서로 진행됐다.
- Depthwise는 채널 별로 kernel이 있기 때문에 채널 수는 유지하고 특징만 추출하는 단계이다.
- Pointwise는 1*1 kernel로 피쳐맵의 채널을 늘려주기 위한 단계이다.
- MobileNet V2의 Residuals+ DW(depth wise separable convolution) 과정
- 원래의 bottleneck : 1*1 커널로 채널을 줄여준 후 3*3 커널로 특징을 추출한다. 이어서 1*1 커널로 다시 채널을 늘려주는 병목 구조이다.

ResNet에서 등장한 Residual Bolck(bottleneck) - Bottleneck dw conv은 1*1 커널로 채널을 늘려준 후 DW컨볼루션을 진행한다. 이어서 1*1 컨볼루션으로 채널을 다시 줄여준다.
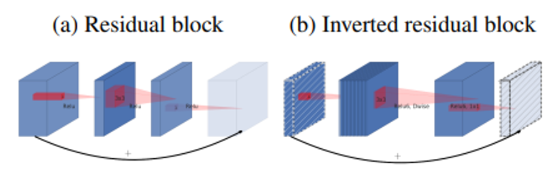
(a) Residual block, (b) Inverted residual block. (b)가 (a)와는 정반대로 동작하는 것을 확인할 수 있음.
- 원래의 bottleneck : 1*1 커널로 채널을 줄여준 후 3*3 커널로 특징을 추출한다. 이어서 1*1 커널로 다시 채널을 늘려주는 병목 구조이다.
- ReLU를 통과하기 전 피쳐맵의 채널을 늘려주는 이유는 활성화 함수로 ReLU를 사용하게 되면 음수값을 가진 정보는 모두 0으로 변환되어 손실되는데, Input에 대한 손실을 최대한 줄이기 위함이다.

- MobileNet V2의 전체적인 구조는 다음과 같다. $t$는 expansion factor로, Inverted Residual Blcok에서 채널을 증가시킬 비율을 의미한다. 예를들어 채널 수가 $d'$이고 높이와 너비가 $h, w$인 입력 데이터가 있을 때, 출력 채널이 $d''$이고 커널의 크기가 $k$인 경우 Inverted Residual Block에서의 연산량은 $h*w*d*t(d'+k^2+d'')$이 된다.

- MobileNetV2를 MobileNetV1, ShuffleNet 과 각각 비교하면 MobileNetV2의 경우 파라미터의 개수가 400K개로 가장 적은 것을 확인할 수 있다.

Conclusion
- MobileNetV2는 Real time, mobile, 임베디드 분야에 사용하기 위해 만들어진 경량화 모델이다.
- 속도와 용량은 줄이되 정확도, 성능은 유지하는 MobileNetV2를 구축했다.
728x90
'Paper' 카테고리의 다른 글
'Paper' Related Articles
more



