
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- res
- vlm
- gsoc
- google summer of code
- 이미지 필터링
- gsoc 2025
- 에지 검출
- 논문 요약
- 논문 리뷰
- 딥러닝 목적함수
- 딥러닝 엔트로피
- res paper
- gsoc 후기
- TransFuser
- 엔트로피란
- transfuser++
- 원격 학습 안끊기게
- grefcoco dataset
- blip-2
- gres
- object detection
- clip
- 객체 검출
- mobilenetv1
- referring expression segmentation
- E2E 자율주행
- grefcoco
- Object detection article
- clip adapter
- 1차 미분 마스크
- Today
- Total
My Vision, Computer Vision
[논문 리뷰/요약]MobileNetv1, MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications 본문
[논문 리뷰/요약]MobileNetv1, MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
gyuilLim 2024. 3. 29. 20:12
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
We present a class of efficient models called MobileNets for mobile and embedded vision applications. MobileNets are based on a streamlined architecture that uses depth-wise separable convolutions to build light weight deep neural networks. We introduce tw
arxiv.org
Abstract
- MobileNet 탄생 배경 : 모바일 및 임베디드 비전 응용 프로그램을 위해 효율적인 모델을 제시하기 위함.
- 어떻게? : Depth wise separable convolutions을 사용하여 streamlined(간소화된) architecture 설계하였다.
- 지연 속도와 정확도를 모두 고려하였고 두 개의 하이퍼 파라미터(width, resolution multiplier)로 네트워크의 크기를 조절할 수 있다.
- MobileNet은 ImageNet뿐만 아니라 여러 분야에서 다른 모델과 비교했을 때도 좋은 성능을 보여준다.
1. Introduction
- AlexNet 이후 CNN 모델의 연구가 많아지고, 다양한 모델이 등장했다.
- 하지만 대부분의 모델이 성능을 높이기 위해 더 깊고 복잡하게 만들어졌기 때문에 효율과 속도에 대해서는 고려되지 않았다.
- 로보틱스, 자율주행과 같은 실시간 작업은 더 빠른 시간을 요구하기 때문에 정확하지만 지연시간이 짧은 모델을 구축할 필요가 있었다.
2. Prior Work
- 최근 연구는 작은 네트워크를 구축할 때 주로 크기에 초점을 맞추고 속도는 고려하지 않는 경향이 있다.
- 최근 등장한 경량화 모델
- Flattened networks - factorized convolution 사용
- Xception network - dw convoltion을 사용하여 Inception V3 발전
- Squzzeznet - 병목 접근 방식 사용
3. MobileNet Architecture
- Depthwise separable convolution과 네트워크의 크기를 조절하는 두 개의 하이퍼 파라미터를 설명한다.
3.1 Depthwise Separable Convolution
- 입력 데이터의 크기를 $M*D_F*D_F$($M$ : 입력 채널, $D_F$ : 입력 해상도), 출력 데이터의 크기를 $N*D_G*D_G$($N$ : 출력 채널, $D_G$ : 출력 해상도) 라 하자.
- Standard Convolution

- 위 그림은 일반적인 convolution 연산을 나타낸 것이다.
- 입력 데이터의 채널이 3, 해상도가 224 * 244이고 출력 데이터의 채널이 5, 해상도가 224 * 224 라고 할 때, 커널은
5(out channel)*3(in channel)*3*3(kernel size)의 크기로 구성된다. - 이 때 커널의 파라미터 개수는 135(5*3*3*3)개이다.
- Depthwise Separable Convlution

- Depthwise Separable Convolution은 Standard Convolution을 depthwise와 pointwise 단계로 나눠놓은 것이다.
- 먼저 Depthwise, pointwise 각각에 대해 알아보자.
- Depthwise Convolution

- 일반적인 커널의 역할(특징 추출)을 수행하는 부분.
- 필터를 거쳐 특징 추출을 위한 convolution이다.
- 커널의 파라미터 개수는 27(3*3*3)개이다.
- Pointwise Convolution
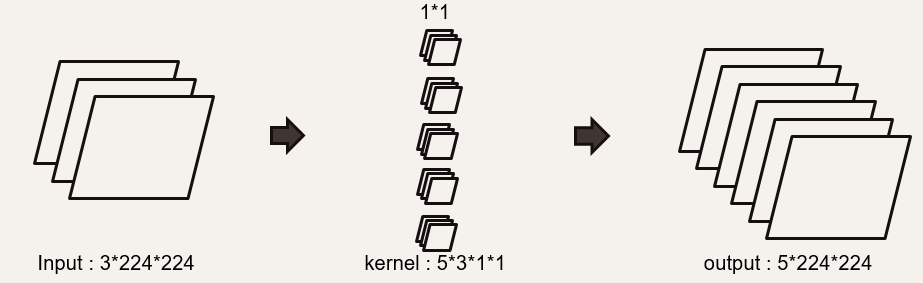
- Depthwise 단계에서 출력된 데이터를 결합하는 단계이다.
- 채널을 늘려주는 역할을 한다.
- 커널의 파라미터 개수는 15(3*1*1)개이다.
- Depthwise Separable Convolution
- 다시 Depthwise Separable Convolution을 보자.
- 커널의 총 파라미터의 개수는 42(27+15)개로, Standard Convoution에 비해 약 60%감소했다.
- Depthwise Separable Convolution의 이점은 Standard Convolution과 비슷한 효과를 내면서 파라미터의 개수를 줄여주었다는 것이다.
- Standard Convolution과 Depthwise Separable Convolution의 연산량 비교
- 각각 Standard와 Depthwise로 간략하게 표현.
- Standard : $D_K * D_K * M * N * D_F * D_F$($M$ : 입력 채널, $D_F$ : 입력 해상도,
N$ : 출력 채널, $D_K$ : 커널 크기) - Depthwise : $D_K * D_K * M * D_F * D_F + M * N * D_F * D_F$
- Depthwise convolution : $D_K * D_K * M * D_F * D_F$
- Pointwise convolution : $M * N * D_F * D_F$
- Standard를 Depthwise에 대해 나눠주면,
$$\frac{D_K * D_K * M * D_F * D_F + M * N * D_F * D_F}{D_K * D_K * M * N * D_F * D_F} = \frac{1}{N} + \frac{1}{D^2_K}$$
가 되고,
- 이 때 $N$ 은 출력 채널로 $\frac{1}{N}$은 0에 가깝다.(네트워크 후반부 출력 채널이 크기때문)
- $D_k$ 는 커널의 크기인데, 통상적으로 커널의 크기를 3으로 설정한다.
- 따라서 Depthwise는 Standard에 비해 연산량을 8~9배 줄여주는 것이다.
3.2 Network Structure and Training

- 위 이미지는 Standard와 Depthwise를 비교한 사진이다.
- MobileNet 구조의 특징은 처음 layer를 제외한 모든 layer가 Depthwise conv라는 점과 Depthwise, Pointwise(1x1) 단계 모두에서 BN, ReLU를 거친다는 것입니다.
- 이 둘을 각각의 layer로 구분하면 총 28개의 layer로 구성됩니다.
네트워크의 전체적인 구조

- 논문의 자료를 그대로 가져온것인데, 눈에 확 들어오진 않는다.
- 28개의 Convolution layer와 1개의 Fully connected layer로 이루어져있다.
Layer 단위 연산량, Parameter 비율

- Pointwise가 대부분의 연산량을 차지한다.
- Pointwise와 FC layer가 각각 75%, 24% 정도의 파라미터를 차지한다.
3.3 Width Multiplier: Thinner Models
- MobileNet은 이미 가볍고 빠르지만 특정 상황에서 더욱 경량화해야할 수 있기때문에 너비 배율 α라는 변수를 추가로 도입했다.
- 주어진 레이어와 너비 배율 α에 대해
- 입력 채널 수 $M$ → $αM$
- 출력 채널 수 $N$ → $αN$
- 즉 연산량은 아래와 같이 바뀌게 된다.
$$ D_K * D_K * \alpha M * D_F * D_F + \alpha M * \alpha N * D_F * D_F $$
- α는 일반적으로 1, 0.75, 0.5, 0.25로 설정하고 0과 1사이의 값을 가진다.
- 너비 배율 α는 계산 비용과 파라미터 수를 약 $\alpha^2$ 만 감소시킨다.
3.4 Resolution Multiplier: Reduced Representation
- 네트워크를 경령화하기 위한 두 번째 하이퍼 파라미터는 해상도 비율(ρ) 이다.
- 아래 식은 α와 ρ를 모두 적용한 후의 연산량을 나타낸 것이다.
$$D_K * D_K * \alpha M * \rho D_F * \rho D_F + \alpha M * \alpha N * \rho D_F * \rho D_F$$
- 마찬가지로 ρ도 0과 1 사이의 값을 갖고 일반적으로 입력 해상도가 224, 192, 160, 128이 되도록 설정한다.
- α = 1, ρ=1 이면 MobileNet의 baseline에 해당한다.



