
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 딥러닝 목적함수
- mobilenetv1
- clip
- mabp
- vision transformers for dense prediction 논문 리뷰
- Object detection article
- 1차 미분 마스크
- 딥러닝 엔트로피
- grefcoco dataset
- 이미지 필터링
- res
- res paper
- vit segmentation
- referring expression segmentation
- vision transformers for dense prediction 논문 요약
- vlm
- clip adapter
- 원격 학습 안끊기게
- 객체 검출
- vit dense prediction
- 엔트로피란
- 기계학습
- 에지 검출
- blip-2
- grefcoco
- 논문 요약
- object detection
- gres
- 논문 리뷰
- dpt 논문
- Today
- Total
My Vision, Computer Vision
[논문 요약/리뷰] CoOp : Learning to Prompt for Vision-Language Models 본문
Learning to Prompt for Vision-Language Models
Large pre-trained vision-language models like CLIP have shown great potential in learning representations that are transferable across a wide range of downstream tasks. Different from the traditional representation learning that is based mostly on discreti
arxiv.org
발행일 : 2021년 9월 2일
저널/학회 : SPRINGER 2022
Problem
- CLIP과 같은 기존 VLM은 프롬프트 엔지니어링을 통한 Zero-shot transfer가 가능했다.
- 하지만 프롬프트 엔지니어링은 도메인에 대한 전문 지식이 필요하고, 프롬프트의 작은 변화에도 성능이 크게 달라지기 때문에 시간 비용이 큰 한계가 있다.

- 예를 들어, 위 (a)번째 이미지에서 프롬프트에 ‘a’가 하나 추가됐을 뿐인데 성능은 약 6%정도 향상된다.
- 하지만 결국 Manual(수동)이기 때문에, 최적의 프롬프트를 보장하지 않을 가능성이 더 높다.
- 본 연구에서는 학습 가능한 컨텍스트(프롬프트) 벡터를 네트워크에 추가한다.
Contributions
- VLM을 다운스트림 태스크에 적용할 때, 프롬프트 엔지니어링의 효율의 중요성을 보여준다.
- Context Optimization(CoOp), 학습 가능한 프롬프트 벡터가 추가된 네트워크를 제안하고, 두 가지 방식으로 구현한다.
Methods
Zero-Shot Inference
- 이미지 $x$ 에 대해 추출된 특징을 $f$, “a photo of a [CLASS]” 라는 프롬프트에서 추출된 벡터를 ${ w_i}^K_{i=1}$ 라고 할 때($K$ 는 클래스 개수) 특정 클래스에 대한 출력 확률은 아래와 같다.
$$p(y=i|x)=\frac{\mathrm {exp}(\mathrm {cos}(w_i, f)/\tau)}{\sum^K_{j=1}\mathrm{exp}(\mathrm{cos}(w_j,f)/ \tau)}$$
- 기존 Closed-set 분류에서는 랜덤으로 초기화된 벡터에서 시각 개념을 학습하지만, Vision-Language Pre-training 방식을 활용하면 텍스트 인코더로부터 Open-set 시각 개념을 사용할 수 있다.
Context Optimization

- Pre-trained 파라미터는 모두 Frozen 상태로, 프롬프트 벡터만 학습한다.
- 위 이미지는 CoOp 아키텍쳐의 오버뷰이다.
- CLIP과 거의 동일하게 Image Encoder, Text Encoder가 각각 있는데, 입력 텍스트에 Learnable Context만 추가된 것을 확인할 수 있다.
- Unified Context, Class-Specific Context 두 가지 옵션으로 구현한다.
Unified Context
- Unified Context는 모든 클래스에 같은 Context가 적용되는 방식이다.
- Text encoder에 입력으로 들어가는 텍스트 $t = [V]_1[V]_2 \cdots[V]_M[CLASS]$ 이다. 512차원의 벡터 $V$ 가 총 M개로 구성된다. 이 때, M은 하이퍼 파라미터이다.
$$p(y=i|x)=\frac{\mathrm {exp}(\mathrm {cos}(g(t_i), f)/\tau)}{\sum^K_{j=1}\mathrm{exp}(\mathrm{cos}(g(t_j),f)/ \tau)}$$
- 이 때 $g$ 는 텍스트 인코더, $t_i$ 는 i번째 클래스 이름을 의미한다.
- $t = [V]1\cdots[V]{\frac{M}{2}}[CLASS][V]_{\frac{M}{2}+1} \cdots [V]_M$ 처럼 Class의 위치를 프롬프트 중간에 넣어, 학습 유연성을 높일 수 있다.
Class-Specific Context
- CSC(Class-Specific Context)는 Class별로 Context가 다르게 적용된다.
- 즉 $[V]^i_1[V]^i_2 \cdots [V]^i_M \ne [V]^j_1[V]^j_2 \cdots [V]^j_M$ 인 것이다.
- 실험에서, CSC가 Fine-grained 분류 작업에서 더 좋을 수 있다는 것을 보여준다.
Training
- 기존 Contrastive loss처럼 Cross-entropy로 학습하고 텍스트 인코더를 거쳐 역전파가 수행된다.
Experiments
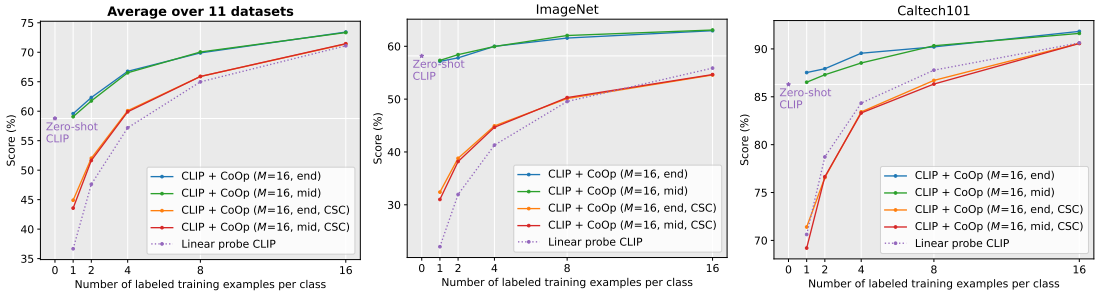
- 왼쪽 그래프는 ImageNet, Caltech101을 포함한 총 11개의 데이터셋에 대한 평균이다.
- CoOp은 학습을 필수적으로 해야하기 때문에 Zero-shot은 불가능하고, 1-shot부터 측정된다.
- 그래프를 보면 Linear probe를 상회하는 것을 확인할 수 있다.
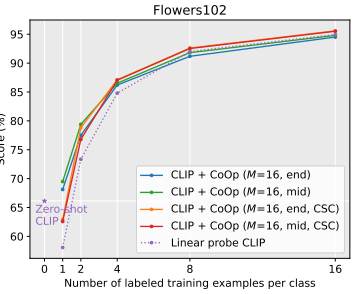
- 또한 Flowers102와 같은 Fine-grained 데이터셋에서는 CSC가 더 높게 측정된다.
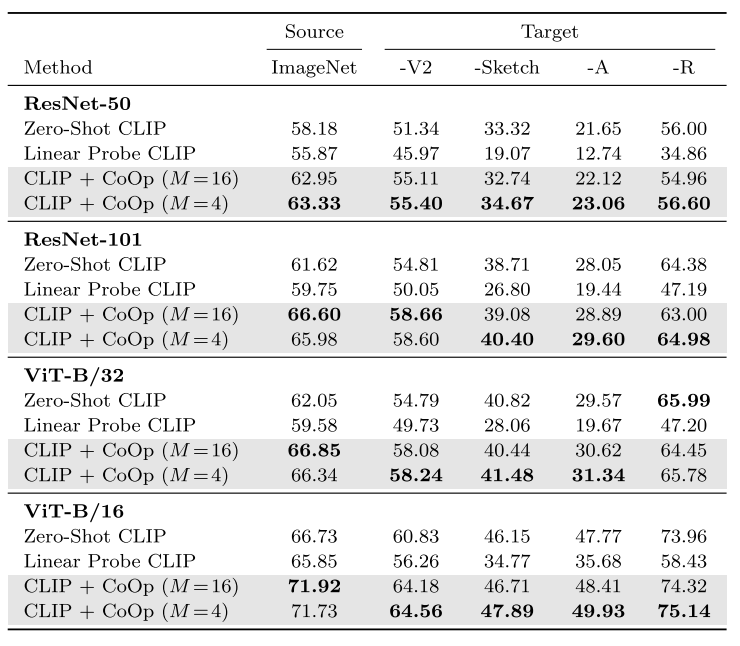
- 백본을 다르게 하여 Robustness에 대해 실험한 테이블이다.
- (소스)ImageNet에서 학습한 후 변종 데이터셋(타겟)인 V2, Sketch, A, R에 대해 성능을 측정한 것이다.
- Linear probe 방식은 도메인 일반화에서 성능이 낮은 것을 확인할 수 있다.
- CoOp은 소스 데이터셋에 노출되었음에도, 타겟 데이터셋에서 좋은 일반화 성능을 보여준다.
Conclusion
- CoOp은 학습 가능한 프롬프트 벡터를 텍스트 인코더의 입력으로 넣어, 프롬프트 학습의 중요성을 보여주었다.
- 하지만, 프롬프트가 벡터의 형태로 존재하기 때문에 결과의 해석이 힘들다는 단점이 있다.
Review
- 접근 방식이 상당히 나이브하다. 비슷한 방법으로 좀 더 창의적으로 할 수 있었을 것 같은데, 급하게 쓴 것 같기도 하다.
- 어찌됐건 VLM에서 중요한 건 두 가지 모달리티를 융합하여 좋은 Representation을 만들어내는 것이다.
- CoOp은 원본 네트워크를 전혀 건드리지 않고, 추가적인 벡터만으로 성능을 올렸기 때문에 가치가 있다.



