
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- object detection
- dinov2 논문 리뷰
- dinov2: learning robust visual features without supervision 논문 리뷰
- Object detection article
- 에지 검출
- vlm hallucination paper
- blip-2
- 논문 리뷰
- vlm 환각이란
- vlm 환각
- 딥러닝 엔트로피
- 원격 학습 안끊기게
- 기계학습
- 논문 요약
- polling-based object probing evaluation
- mobilenetv1
- vlm hallucination
- dinov2: learning robust visual features without supervision
- 1차 미분 마스크
- evaluating object hallucination in large vision-language models
- 엔트로피란
- dinov2: learning robust visual features without supervision 논문
- 이미지 필터링
- clip adapter
- vlm
- 딥러닝 목적함수
- evaluating object hallucination in large vision-language models 논문
- clip
- evaluating object hallucination in large vision-language models paper
- 객체 검출
- Today
- Total
My Vision, Computer Vision
[논문 요약/리뷰] CIDEr: Consensus-based Image Description Evaluation 본문
CIDEr: Consensus-based Image Description Evaluation
Journal : CVPR 2015
Published Date : 2014년 11월 20일
Keyword : CIDEr score, Evaluation Metric, Microsoft
CIDEr: Consensus-based Image Description Evaluation
Automatically describing an image with a sentence is a long-standing challenge in computer vision and natural language processing. Due to recent progress in object detection, attribute classification, action recognition, etc., there is renewed interest in
arxiv.org
Problem
- 이미지 캡셔닝 분야가 주목을 받게되면서 이미지로부터 생성된 문장을 평가하는 자동화 방식이 요구됨.
- 사람이 직접 평가하는 방식은 비용이 많이들고, 재현하기 어렵고, 느린 문제가 있음.
- 기계 번역 평가 지표인 BLEU, METEOR 기계 요약 평가 지표인 ROUGE는 사람 평가와의 상관 관계가 약함.
- 본 논문에서는 합의(Consensus) 기반 자동화 평가 지표 CIDEr(Consensus-based Image Description Evaluation)을 제시함.

- Consensus란, 위에서 굵게 표시된 부분들이다. 즉, 사람이 이미지에 대해 묘사할 때 대부분 공통적으로 포함하는 것을 Consensus라고 함.
Contributions
- 새로운 자동화 평가 지표 및 두 개의 새로운 데이터셋을 도입.
- 이미지 당 5개 정도의 캡션만 있던 기존 데이터셋과 달리 50개 캡션이 있는 PASCAL-50S, ABSTRACT-50S.
Methods
Consensus Interface

- Consensus score를 측정하는 방식에 대해 설명함.
- (a)는 이미지, (b)는 이미지에 대한 캡션(Reference), (c) 윗부분은 이미지로부터 생성된 문장(Candidate), (c) 아랫부분은 Triplet Annotation.
- Triplet Annotation이란, 문장 A, B, C를 말함.
- Sentence A : (b)에서 50개의 문장 중 한 개의 문장.
- Sentence B : 생성된 후보 문장 1.
- Sentence C : 생성된 후보 문장 2.
- 이 때, 평가자에게 “B, C 중 어느 문장이 A와 더 유사한가?”라는 질문이 주어지고, 3개의 응답 중 과반수인 문장을 더 유사하다고 판단함.
- 2명이 B가 더 유사하다고 판단했으면 B가 채택.
- 이 방식으로 사람 평가자와 자동화 평가 지표 간에 상관관계를 측정.
CIDEr Metric
- 목표는 이미지($I_i$) 에 대해 생성된 Candidate($c_i$)가 이미지 캡션(Reference, $S_i={s_{i1}, \cdots, s_{im}}$)과 얼마나 잘 일치하는지 자동으로 평가하는 것.
- 먼저 Candidate와 Reference 모두 어근 혹은 기본 형태로 매핑.
- “fishes”의 경우 “fish”로 매핑됨.
- 이이서 각 문장을 N-gram 집합으로 표현한다. N은 1부터 4까지임.
- N-gram 집합이란, 문장에서 연속된 N개 단어의 모든 경우의 수를 포함한 것.
- “I like you”에서 N=2라면, [“I like”, “like you”]임.
- N-gram 집합에서 임의의 원소를 $w_k$라 함.
TF-IDF
- 하나의 이미지 내에서 자주 반복되는 단어는 높은 가중치를, 모든 이미지에서 자주 등장하는 단어는 낮은 가중치를 부여.
- $\mathrm{TF}(t, d) = \frac{단어\ t가\ 문서\ d에서\ 나타나는\ 횟수}{문서\ d의\ 총\ 단어\ 수}$
- $\mathrm{IDF}(t) = \log(\frac{N}{1+\mathrm{df}(t)})$, $df(t)$는 단어 $t$ 가 등장한 문서의 수.
- $\mathrm{TF-IDF}(t,d) = \mathrm{TF}(t,d) \times \mathrm{IDF}(t)$
- 따라서 N-gram에 대한 TF-IDF를 계산하여, 가중치로 사용.
- N-gram($w_k$)이 Reference($s_{ij}$)에서 등장하는 횟수를 $h_k(s_{ij})$,
- N-gram($w_k$)이 Candidation($c_i$)에서 등장하는 횟수를 $h_k(c_i)$ 라 할 때,
$$g_k(s_{ij})=\frac{h_k(s_{ij})}{\sum_{w_l \in \Omega}h_l(s_{ij})}\mathrm{log}(\frac{|I|}{\sum_{I_p \in I}\mathrm {min}(1, \sum_q h_k(s_{pq}))})$$
- TF-IDF 가중치($g_k$)는 위와 같다. $\Omega$ 는 N-gram의 Vocab, $I$ 는 이미지셋임.
- 첫번째 항은 TF에, 두번째 항은 IDF에 대응.
CIDEr score
- CIDEr score는 Candidate와 Reference의 코사인 유사도(L2 norm)로 계산.
$$ \mathrm{CIDEr}n(c_i, S_i) = \frac{1}{m}\sum_j\frac{\mathbf g^n(c_i)\cdot \mathbf g^n(s_ij)}{||\mathbf g^n(c_i)||\ ||\mathbf g^n(s{ij})||} $$
- $n$ 은 N-gram에서 길이(N)을 의미.
- $g_n(c_i)$ 는 Candidate($c_i$)의 모든 N-gram에 해당하는 가중치로 구성된 벡터 $g_k(c_i)$ 이다. $s_{ij}$ 도 동일하게 적용됨.
- $n$ 을 여러 길이로 확장하면 아래와 같음.
$$ \mathrm{CIDEr}(c_i, S_i) = \sum^N_{n=1} w_n \mathrm{CIDEr}_n(c_i, S_i) $$
- N=4로 설정하고, $w_n = 1/N$ 이다. 즉 N이 증가할수록 반영을 적게함.
Experiments
Accuracy of Automated Metrics
- 위에서 Consensus score를 측정할 때, Triplet Annotation을 사용했었음.
- 이제 Triplet Annotation 방식으로 사람과 평가 지표간 수치를 측정.
- 예를 들어 사람 평가에서 B 문장이 채택되었다고 하자.
- Sentence A에 대한 CIDEr score가 B가 더 높다면, 정답이라고 간주함.
- 평가에 사용되는 Reference 문장의 개수가 많아질 수록 CIDEr, ROUGE는 ACC가 증가한다.
- BLEU는 참조되는 문장이 많아질수록 ACC가 감소한다.
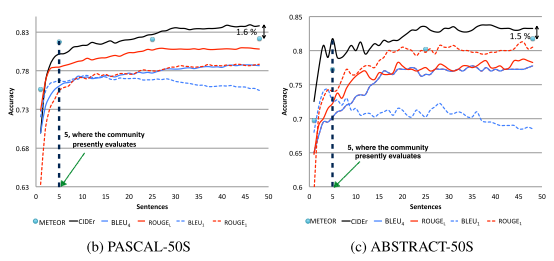
- PASCAL-50S, ABSTRACT-50S 두 개의 데이터셋에 대한 그래프이다.
- 마찬가지로 Reference 문장의 개수가 증가할 수록 ACC가 증가하는 경향이 있다.
- CIDEr가 가장 높게 측정된다.



