
반응형
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- evaluating object hallucination in large vision-language models paper
- vlm 환각이란
- vlm hallucination
- dinov2: learning robust visual features without supervision 논문
- 엔트로피란
- vlm 환각
- dinov2: learning robust visual features without supervision 논문 리뷰
- 에지 검출
- 이미지 필터링
- polling-based object probing evaluation
- Object detection article
- mobilenetv1
- 1차 미분 마스크
- evaluating object hallucination in large vision-language models 논문
- dinov2 논문 리뷰
- 논문 요약
- 딥러닝 엔트로피
- clip adapter
- clip
- 객체 검출
- 딥러닝 목적함수
- 논문 리뷰
- vlm hallucination paper
- evaluating object hallucination in large vision-language models
- blip-2
- vlm
- object detection
- 기계학습
- 원격 학습 안끊기게
- dinov2: learning robust visual features without supervision
Archives
- Today
- Total
My Vision, Computer Vision
[논문 리뷰/요약] BEIT: BERT Pre-Training of Image Transformers 본문
BEiT: BERT Pre-Training of Image Transformers
We introduce a self-supervised vision representation model BEiT, which stands for Bidirectional Encoder representation from Image Transformers. Following BERT developed in the natural language processing area, we propose a masked image modeling task to pre
arxiv.org
Problem

- BEIT(Bidirectional Encoder representation from Image Transformers)를 제안한다.
- ViT는 CNN 보다 학습에 더많은 데이터가 필요한 문제가 있는데, 이를 해결하기 위해 self-supervised pre-training, contrastive learning, self-distillation 등 방법이 연구되었다.
- 이 논문에서는 BERT의 Masked Langauge Modeling 방법을 ViT에 도입한다.
- 하지만 BERT와 다르게 ViT에서는 입력(ex. 패치)에 대해 미리 정의된 Vocabulary가 없다.
- 직접적인 대안은 픽셀을 직접 예측하는 회귀 문제로 대체하는 것인데, 이는 단기 의존성과 고주파 세부 정보를 모델링하는 데 불필요한 계산 자원을 낭비한다는 문제가 있다.
Contributions
- Masked Image Modeling을 Self-supervsed 방식으로 사전학습하는 ViT를 제안한다.
- Pre-trained된 BEIT를 Image classification, Semantic segmentation과 같은 다운스트림 태스크에 파인튜닝한다.
- Human annotation 없이 Self-supervised 학습으로도 Semantic 영역과 객체의 영역을 잘 구분하도록 학습된다는 것을 보여준다.
Methods
Image Patch
- 이미지 x 는 N 개의 패치로 나누어진다. 이 때, x∈RH×W×C 이고 N=HW/P2 이다.
- C,H,W 는 각각 채널(Channel), 높이(Height), 너비(Width)이고, (P,P) 는 패치의 Resolution이다.
- 이미지는 벡터로 Flatten된 후 선형으로 프로젝션된다. 이는 BERT의 Word embedding 과정과 유사하다.
- 논문의 실험에서는, 224 * 224 이미지를 14 * 14 개의 패치로 나눈다. 이 때 패치의 크기는 16 * 16이다.
Visual Token
- 자연어와 유사하게, 입력 이미지를 Image tokenizer로 토큰의 시퀀스로 매핑한다.
- 이미지 x 를 토큰 집합 z 로 매핑하는 것이다. 이 때, z=[z1,⋯,zN]∈Vh×w 이고 V 는 vocabulary이다.
- Image tokenizer(q_{\boldsymbol \phi}(z|x))는 DALL-E의 dVAE를(discrete Variational Autoencoder) 사용한다.
- 그 후 Decoder(p_{\boldsymbol \psi}(x|z)) 는 Visual token z 를 기반으로 입력 이미지 x 를 복원하도록 학습한다.
- 디코더는 Pre-training에서 사용하지 않고, Semantic segmentation에 파인튜닝할 때 사용한다.
- 위에서 각 이미지에 대해 14 * 14 크기의 패치로 나눈다고 했는데, 토큰도 마찬가지로 14 * 14 개이다.
- 어휘 \mathcal V 의 크기는 8192개이다. |\mathcal V| = 8192
Backbone Network: Image Transformer
- 백본 네트워크는 ViT를 사용한다.
- 이 때, 네트워크의 입력은 이미지 x 의 패치 집합 {x^p_i}^N_{i=1} 이다.
- 각 패치들을 Linear projection하여 패치 임베딩 E x^p_i로 변환한다. 이 때 E \in \mathbb R^{(P^2C)\times D} 이다. 즉 P^2C 크기의 패치를 D 차원으로 변환하는 과정이다.
- 또한 특수 토큰 [s]와 Positional embedding E_{pos} \in \mathbb R^{N \times D} 를 더하여 최종적으로 입력 벡터는 H_0 = [e_{[s]}, Ex^p_i, \dots, Ex^p_N] + E_{pos} 가 된다.
- 인코더는 L 개의 트랜스포머 레이어로 구성되며, H_L = \mathrm{Transformer}(H_{l-1}) 로 나타낼 수 있다.
- 마지막 레이어의 출력 벡터는 H_l = [h^{[S]}_L , h^1_L, \dots, h^N_L] 이며, h^i_L 은 i 번째 이미지의 인코딩된 Representation을 의미한다.
Masked Image Modeling
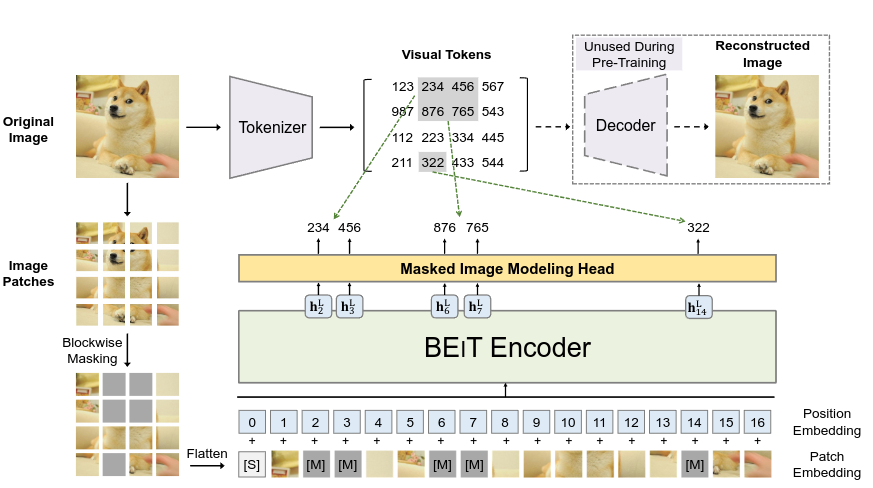
- MIM(Masked Image Modeling)은 이미지 패치 집합에서 랜덤하게 40%를 마스킹하는 작업이다.
- 입력 이미지 x 를 N개의 패치 {x^p_i }^N_{i=1} 와 N개의 토큰 {z_i}^N_{i=1} 으로 변환한다.
- 여기서 N개의 이미지 패치 중 40%를 마스크 임베딩 토큰 e_{[M]} \in \mathbb R^D 로 교체한다.
- 따라서 마스킹을 포함한 이미지 패치는 x^{\mathcal M} = {x^p_i : i\notin \mathcal M }^N_{i=1} \cup { e_{[M]} : i\in \mathcal M }^N_{i=1} 로 나타낼 수 있다. \mathcal M 은 마스킹된 패치의 인덱스이다.
- 마스크 임베딩 토큰의 Representation은 |\mathcal V|=8192h^L_i 수식은 아래와 같다.
p_{MIM}(z'|x^\mathcal M)=\mathrm{softmax}_{z'}(W_ch^L_i+b_c)
Blockwise Masking
- 이미지 패치에서 마스킹 인덱스를 선별할 때, 완전한 무작위가 아닌 블럭 단위로 수행된다.
- 다음은 Blockwise Masking의 알고리즘이다.
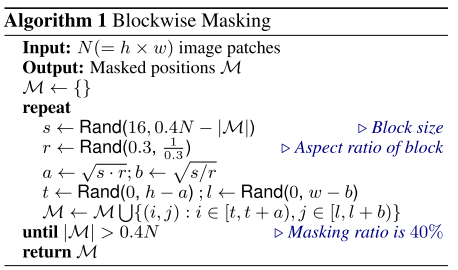
- s 는 Block size로, 패치의 최소 크기인 16과 0.4N - |\mathcal M| 사이이다.
- r 은 Aspect ratio로 0.3, 1/0.3 사이이다.
- a 와 b 는 block의 가로, 세로 크기이고 t 와 l 은 Block의 시작 지점이다.
Experiment
- 실험은 Image classification, Semantic segmentation 태스크에 파인튜닝하여 진행한다.
- Image classification의 경우, Linear layer를 하나 추가하고 Average pooling을 한 뒤 Softmax로 Class의 확률을 구한다. 수식으로 나타내면 아래와 같다.
\mathrm{softmax}(\mathrm{avg}({h^L_i}^N_{i=1}W_c))
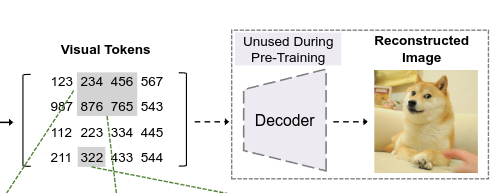
- Semantic segmentation의 경우, SERT-PUP의 Task layer를 따르는데, BEIT를 인코더로 사용하고 여러 개의 디컨볼루션 레이어를 디코더로 사용하여 Reconstructed Image를 만들어낸다.
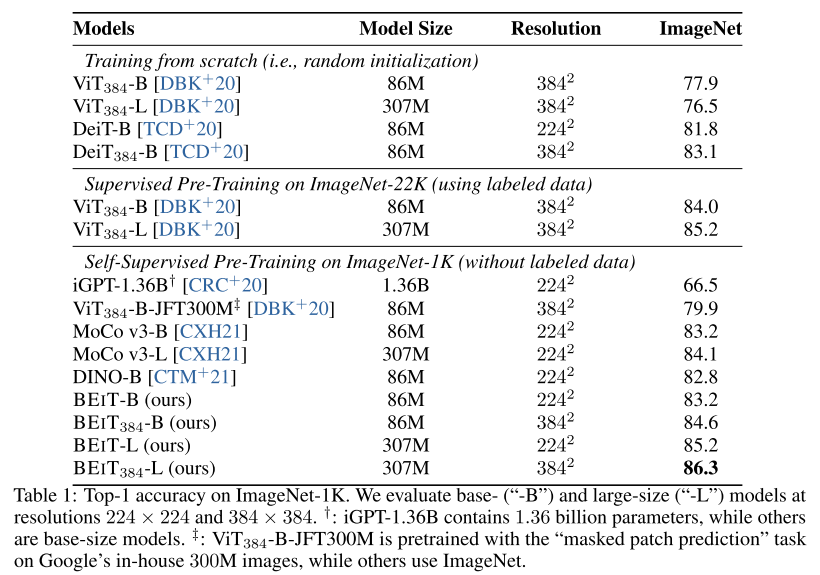
- ImageNet-1K에 대한 Top-1 정확도를 나타낸 테이블이다.
- BEIT 모델의 성능을 봤을 때 해상도의 크기가 클수록, 모델의 크기가 클수록 성능이 증가하는 것을 확인할 수 있다.
- 또한 Self-Supervised로 사전학습된 다른 모델(MoCo, DINO)에 비해 성능이 증가했다.
- From scratch로 학습한 모델과 Supervised로 사전학습한 모델과 비교했을 때도 성능이 높은 것을 확인할 수 있다.

- ADE20K에 대한 Semantic Segmentation 결과이다.

- BEIT의 Ablation study이다.
- Blockwise masking, Visual tokens, Recover, Masking에 대한 실험이고 Visual tokens와 Blockwise masking이 없을 때 성능이 가장 낮아진다.
Conclusion
- 이 논문에서는 BERT에 영감을 받아, MIM(Masked Image Modeling) 기법을 사용하여 Self-supervised로 학습하는 방법을 제안한다.
- 또한 사람이 Annotation하지 않은 이미지만으로 Representation을 효과적으로 학습할 수 있다는 것을 입증하였다.
Review
- 이미지 패치를 Vocab으로 처리하는 부분이 인상깊었다.
- Dall-E의 dVAE를 사용했다고는 하는데, Dall-E도 공부해봐야겠다.
- 하지만 문제라고 생각될 수 있는 부분은, 자연어에서 Word는 어느 텍스트에서 반복적으로 등장할 수 있는데, 하나의 이미지 내에서 패치는 또다른 이미지에서 등장할 확률이 거의 없기때문에 Vocab으로 처리하기에는 효율적으로 정보를 반영하지 못할 것 같다.
728x90
'Paper' 카테고리의 다른 글
'Paper' Related Articles
more



