
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- res paper
- 1차 미분 마스크
- 논문 리뷰
- object detection
- Object detection article
- gsoc 후기
- 이미지 필터링
- 딥러닝 엔트로피
- 기계학습
- mobilenetv1
- 에지 검출
- 엔트로피란
- 딥러닝 목적함수
- referring expression segmentation
- gsoc가 뭔가요
- 논문 요약
- gsoc 지원
- gsoc
- gsoc 2025
- blip-2
- grefcoco
- gres
- grefcoco dataset
- vlm
- clip
- 객체 검출
- 원격 학습 안끊기게
- res
- google summer of code
- clip adapter
Archives
- Today
- Total
My Vision, Computer Vision
[논문 리뷰/요약] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 본문
Paper
[논문 리뷰/요약] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
gyuilLim 2025. 2. 12. 15:49BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations from unla
arxiv.org
발행일 : 2018. 10. 11.
Google AI Language
Problem
- 기존의 Language model들은, 대표적으로 GPT의 경우 모델이 단방향이기 때문에 Self-Attention 레이어에서 이전 토큰만을 참조할 수 있고, 따라서 생성되는 언어 표현(Language Representation)에 제한이 생기는 문제가 있다.
- 이를 이유로 사전학습된 Language model을 다운스트림 태스크에 적용하려면, 복잡한 추가적인 네트워크가 필요했다.
- 이 논문에서는 BERT(Bidirectional Encoder Representations from Transformers)를 제안하여 단방향성 문제를 Masked Language Model(MLM)로 완화하였다.
- 결과적으로 이렇게 사전학습된 모델을 다운스트림 태스크에 적용할 때, 추가적인 출력층 하나만으로도 SOTA를 달성하였다.
Contributions
- 좋은 언어 표현을 생성하기 위해 Bidirectional Pre-training의 중요성을 입증한다.
- 복잡하게 설계된 Task-specific 아키텍쳐 없이도, SOTA를 달성한 최초의 파인튜닝 기반 모델이다.
- 11개의 NLP Task에서 SOTA를 달성했고, 오픈소스로 공개된다.
Method

- BERT는 Pre-training과 Fine-Tuning 단계로 나뉜다.
- Pre-training에서는 Unlabeled 데이터로 학습하고 Fine-Tuning에서는 사전 학습된 가중치로 초기화한 후 Labeled 데이터를 사용하여 모든 파라미터를 End-to-end로 학습한다.
- BERT의 차별점은 사전학습과 파인튜닝이 똑같은 구조로, 모델 아키텍쳐의 별다른 수정없이 가능하다는 것이다.
- BERT는 [CLS] 토큰과 [SEP] 토큰을 사용하는데, 이에 대해 알아보자.
[CLS] 토큰
- Special classification token(특수 분류 토큰)이다.
- 입력 문장의 제일 앞에 위치하고, 문장의 전체적인 의미를 대표하는 벡터로 사용된다.
- 예를 들어 “[CLS] I like sky” 형태로 모델에 입력되는 것이다.
- 문장 분류, 감성 분석 같은 작업에서 이 벡터가 최종 출력으로 사용된다.
[SEP] 토큰
- BERT의 입력은 단일 혹은 두 개로 구성될 수 있는데, 두 가지 방법으로 문장을 구분한다.
- 첫번째는 특수 토큰 [SEP]를 사용하는 것이다. 문장과 문장 사이 [SEP] 토큰을 추가하여 구분하는 것이다.
- 두번째는 문장 A/B 임베딩을 사용하는 것이다. Segment Ebedding이라고 하고, 첫 문장(A)끼리의 임베딩, 다음 문장(B)끼리의 임베딩을 다르게한다.

- 위와 같이, “My dog is cute.”, “He likes playing” 두 개의 문장이 입력되었을 때, 토큰 임베딩, 세그먼트 임베딩, 포지션 임베딩을 다 합한 임베딩을 사용한다.
Pre-training BERT
Task #1 : Masked LM
- MLM(Masked Language Model)이라고 불리는 방법이다.
- Cloze task(빈칸 예측) 방식으로 입력 토큰을 15% 비율로 랜덤하게 [MASK] 토큰으로 마스킹한다.
- [MASK] 토큰의 출력 벡터는 Vocabulary에 대한 소프트맥스로, 특정 토큰(단어)로 매핑된다.
- Fine-tuning 단계에서는 마스크 토큰을 사용하지 않기때문에, Pre-training과 Fine-tuning 사이 미스매치가 생길 수 있는데, 이를 완화하기 위해 마스킹은 다음과 같은 조건으로 수행된다.
Task #2 : Next Sentence Prediction (NSP)
- 문장 관계를 이해하는 모델을 훈련시키기 위해, 이진화된 Next sentence prediction을 사전학습한다.
- 두 문장 A, B에 대해 50%의 확률로 B는 A 다음에 오는 문장이고(IsNext), 나머지 50% 확률로 임의로 선택된 문장(NotNext)이다.
- 즉 답이 IsNext와 NotNext인 이진 분류인 것이다.
- [CLS] 임베딩 토큰의 출력 벡터 C가 NSP에 사용된다.
Fine-tuning BERT
- 파인튜닝은 사전학습과 유사하게 진행된다.
- 텍스트 쌍을 다루는 작업의 경우, Pre-training 단계와 똑같이 텍스트 쌍을 이어붙여 양방향으로 인코딩하는 과정을 거친다.
- Downstream task에 특화된 입력 텍스트를 BERT에 넣고, 모든 파라미터를 End-to-end로 파인튜닝한다.
- 토큰 레벨 작업(시퀀스 태깅, 질문 응답)에서는 토큰에 대한 임베딩 벡터가 출력층에 입력되고, 분류 작업(Entailment, 감성 분석)에서는 [CLS]의 임베딩 토큰이 출력층에 입력된다.
- Sequence tagging / QA 등의 토큰 레벨 작업에서는 토큰 임베딩이 출력층에 입력된다.
- Entailment / 감성 분석 등의 분류 작업은 [CLS] 토큰 임베딩이 출력층에 입력된다.
Experiment
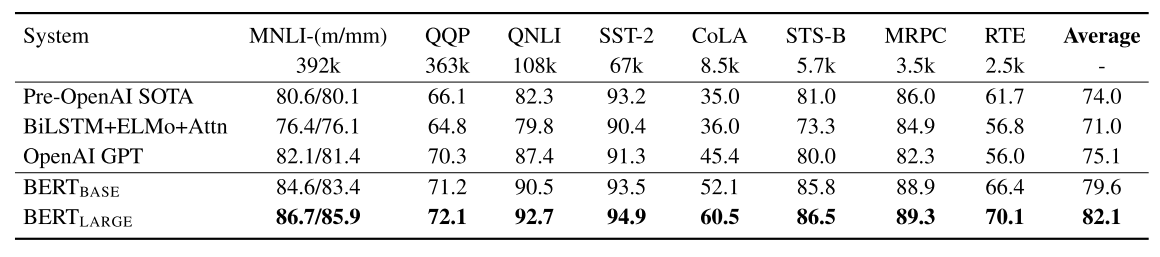
- 여러가지 데이터셋에 대한 GLEU 혹은 F1 score를 나타낸 것이다.
- BERT base와 BERT large 모델 각각 4.5%, 7% 정도의 성능이 향상되었다.

- 위 테이블은 SWAG 데이터셋에 대한 벤치마크이다.
- SWAG 데이터셋은 주어진 문장에 대해 자연스럽게 이어나갈 수 있는 문장을 4가지 중에 하나 고르는 작업이다.
- BERT를 파인튜닝할 때, 4개의 입력 시퀀스를 구성하여(주어진 문장과 4가지 문장에 대한) 학습한다.
- 결과로 OpenAI GPT에 비해 8.3% 향상되었다.
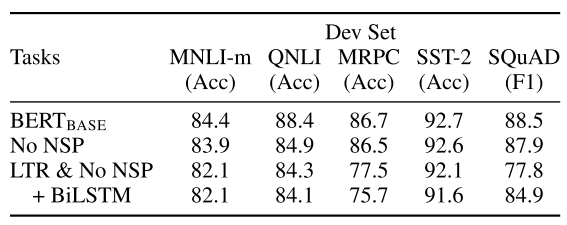
- 위 테이블은 5개 데이터셋에 대한 Ablation study이다.
- No NSP는 Pre-training에서 Next Sentence Prediction 단계를 제거한 것인데, 전체적으로 성능이 하락된다.
- LTR(Left to Right) & No NSP는 MLM(Masked Langauge Model)과 NSP 모두 사용하지 않은 것이다. No NSP와 비교했을 때 성능 하락폭이 더 크다.
- LTR & No NSP + BiLSTM은 LTR을 보완하기위해 BiLSTM을 추가한 것인데, SQuAD에서는 성능이 향상됐지만, 나머지 데이터셋에서는 그대로거나 하락했다.
Conclusion
- 본 논문은 Lagnauge Model의 단방향 아키텍쳐를 양방향으로 확장했다.
- 동일하게 사전학습된 모델이 여러 태스크에 효과적으로 적용될 수 있다는 것을 입증했다.
Review
- BERT는 2018년 10월, 구글에서 나온 논문이다.
- 이 논문에서 사용한 방법인 [CLS] 토큰은 아직도 많은 논문에서 보인다.
- Masked modeling, [CSL] 토큰 등 당시에는 신박했을 방법이라고 생각되고 무엇보다 성능 향상 폭이 크다.
- 어찌됐건 딥러닝에서 가장 기초적이고 중요한 것은 텍스트건 이미지건 좋은 표현을 만들어내는 것 같다.
- 오픈소스이기 때문에 코드도 공부해볼 수 있다.
728x90
'Paper' 카테고리의 다른 글
'Paper' Related Articles
more



