
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- res paper
- google summer of code
- gsoc 2025
- referring expression segmentation
- transfuser++
- mobilenetv1
- 논문 리뷰
- clip adapter
- gres
- clip
- 논문 요약
- blip-2
- 1차 미분 마스크
- 에지 검출
- gsoc
- res
- vlm
- object detection
- 원격 학습 안끊기게
- E2E 자율주행
- Object detection article
- 딥러닝 엔트로피
- 객체 검출
- 이미지 필터링
- TransFuser
- grefcoco
- 딥러닝 목적함수
- 엔트로피란
- gsoc 후기
- grefcoco dataset
- Today
- Total
My Vision, Computer Vision
[논문 리뷰/요약] BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation 본문
[논문 리뷰/요약] BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
gyuilLim 2025. 2. 3. 18:11BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
Vision-Language Pre-training (VLP) has advanced the performance for many vision-language tasks. However, most existing pre-trained models only excel in either understanding-based tasks or generation-based tasks. Furthermore, performance improvement has bee
arxiv.org
Abstract
- Vision-Langauge Pre-training(VLP)은 많은 vision-language task에서 성능을 향상시켰다.
- 그러나 기존의 사전 학습 모델들은 이해 기반(Understanding based) task나 생성 기반(Generation-based) task 중 하나에서만 뛰어난 성능을 보인다.
- 본 논문에서는 Vision-language의 이해 및 생성 기반 모두 적용될 수 있는 새로운 VLP 프레임워크인 BLIP(Bootstrapping Language-Image Pre-training)을 제안한다.
Introduction
- 기존의 VLP method에는 두 가지 한계가 있다.
Model perspective : 모델 관점에서의 한계
- 대부분 인코더 기반(encoder-based), 인코더-디코더(encoder-decoder) 구조를 사용하지만
- 인코더 기반 모델은 텍스트 생성 작업에 직접 전이하기 어렵고(텍스트 생성은 디코더에서 담당하기 때문)
- 인코더-디코더 구조는 Image-text retrieval 작업에서 성공적으로 연구된 사례가 없다.
Data perspective : 데이터 관점에서의 한계
- 대부분 Pre-training을 위해 웹에서 수집(데이터 규모 증가)한 Image-text pair 데이터를 사용한다.
- 하지만 웹에서 불특정 다수의 데이터를 크롤링했기 때문에 텍스트가 이미지를 정확하게 설명하지 않는 경우가 생길 수 있다.
- 따라서 본 논문에서는 노이즈가 많이 포함된 웹 데이터가 최적이 아님을 입증한다.
Contributions
Multimodal mixture of Encoder-Decoder(MED)
- MED는 Unimodal encoder, 이미지 기반 Text encoder, 이미지 기반 Text decoder로 작동할 수 있다.
- 이 모델은 세 가지 Objective(Image-text contrastive, Image-text matching, Image-conditioned language modeling)로 학습된다.
Captioning and Filtering(CapFilt)
- Noisy image-text pair 데이터로부터 학습하는 부트스트래핑 방법이다.
- 사전학습된 MED를 두 가지 모듈로 파인튜닝하는데, 첫번째 모듈은 주어진 웹 이미지로부터 캡션을 생성하는 캡셔너이고 두번째 모듈은 웹 텍스트와 생성된 텍스트에서 노이즈를 필터링하는 필터이다.
Problem
Vision-language Pre-training
- 기존 VLP 연구에서는 데이터 수집을 위해 웹으로부터 Image, Alt-text pair를 대규모로 크롤링한다.
- 규칙 기반 필터링으로 Noise를 없애지만, 여전히 남아있다.
- 하지만 데이터셋의 규모가 커짐에 따라 이런 문제는 간과되었다.
Knowledge Distillation
- 기존 KD는 교사 모델을 크기가 작은 학생 모델로 증류하는 방식으로 사용됐다.
- Self-distillation은 교사 모델과 학생 모델의 크기가 동일한 경우를 말한다.
- 기존 KD 모델은 학생 모델이 교사 모델과 동일한 클래스를 예측하도록 강제하지만, 이 논문에서 제안하는 CapFilt는 캡션을 생성하고, Noisy 캡션을 제거하는 방식으로 증류한다.
Method
- Image encoder는 ViT, Text encoder는 BERT이다.
- MED는 Unimodal encoder, Image-grounded(이미지 기반) text encoder, Image-grounded text decoder 중 하나로 작동할 수 있는 Multi-task 모델이다.
Model architecture

Unimodal encoder
- 이미지와 텍스트를 각각 인코딩한다.
- Visual encoder는 이미지를 인코딩하고, Text encoder는 텍스트를 인코딩한다.
Image-grounded text encoder
- 텍스트 인코더에 Visual 정보를 주입하는 과정을 추가한다. 그래서 Image-grounded인 것이다.
- Visual 정보를 주입한다는 것은, Text encoder의 SA(Self-attention) block과 FFN(Feed forward network) block 사이에 CA(Cross attention)을 추가하여 Image modality를 어텐션에 사용한다는 것이다.
Image-grounded text decoder
- Image-grounded text encoder의 양방향 SA layer를 Causal(단방향) SA layer로 교체한다.
Pre-training Objectives
- Pre-training 동안 세 개의 Objective로 학습하는데, Understanding-based 1개, Generation-based 2개이다.
- ViT에서는 한번의 순전파, 텍스트 트랜스포머에서는 세 번의 순전파가 이뤄진다.
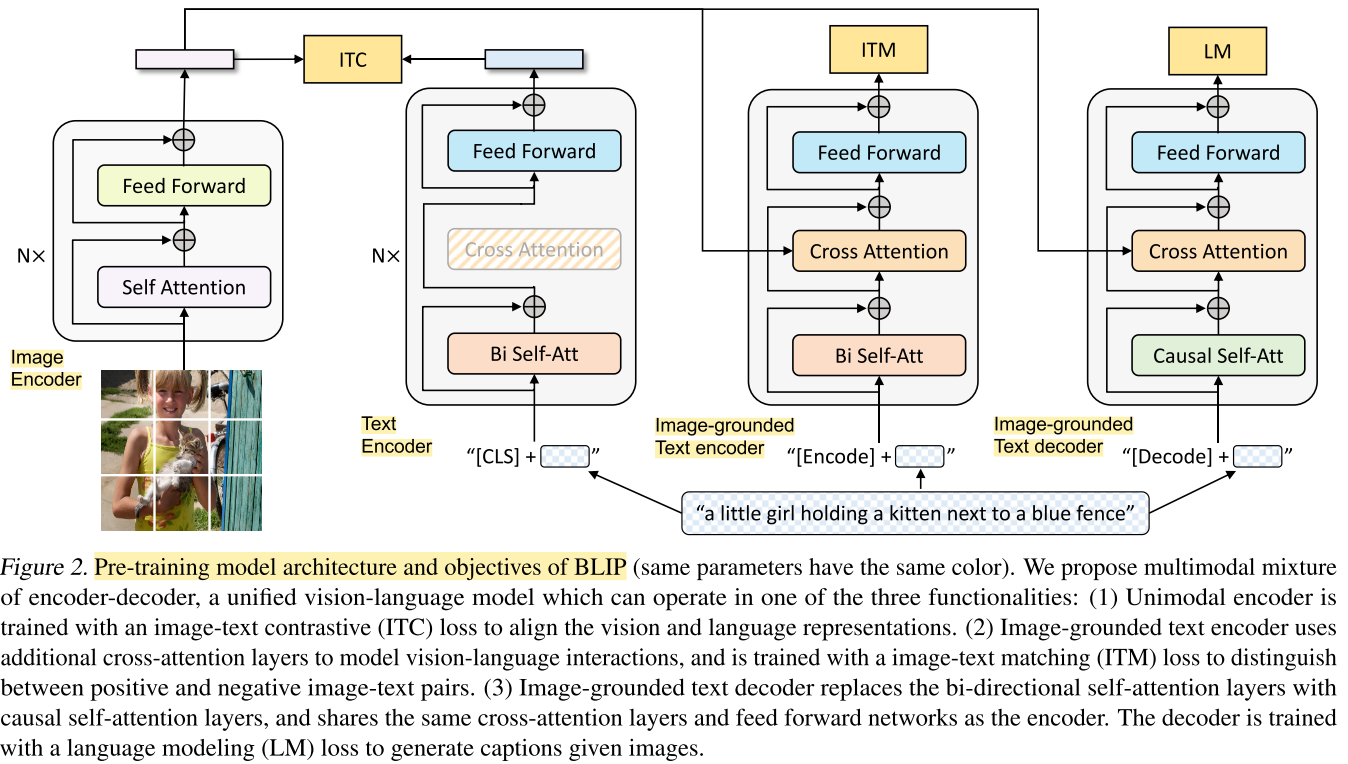
Image-Text Contrastive Loss(ITC)
- Unimodal encoder를 학습하는 데 사용한다.
- Vision-language의 이해를 향상시키는데 효과적이라고 입증되었다.
- 모멘텀 인코더를 도입하여, 소프트 라벨을 훈련 타겟으로 사용한다.
Image-Text Matching Loss(ITM)
- Image-grounded text encoder를 학습하는 데 사용한다.
- Image-Text 멀티모달 표현을 학습하는 것을 목표로 한다.
- Binary classification task로, Image-Text pair가 긍정인지, 부정인지를 예측한다.
Language Modeling Loss(LM)
- Image-grounded text decoder를 학습하는 데 사용한다.
- 이미지에 대한 캡션을 생성하는 것을 목표로 한다.
- Autoregressive 방식으로 Cross entropy loss를 최소화하게 끔 학습한다.
- 텍스트 인코더와 텍스트 디코더는 SA layer를 제외한 모든 파라미터를 공유한다.
- 저자는 이 이유를 인코딩과 디코딩 작업의 차이가 SA layer에서 가장 두드러지기 때문이라고 주장한다.
- 나머지 임베딩, CA, FFN layer는 인코딩 작업과 디코딩 작업에서 비슷하게 기능하기 때문에 공유함으로써 훈련의 효율을 높인다.
CapFilt
- 사람이 어노테이션하는 작업은 비용이 많이 들기때문에 데이터의 수가 그렇게 많지 않다.
- 그래서 최근 연구들은 웹에서 수집한 Image, Alt-text 쌍 ($I_w, T_w$) 을 활용하지만, 종종 텍스트가 이미지를 정확하게 설명하지 않는 경우가 생겨 학습에서 노이즈로 작용할 수 있는 문제가 있다.
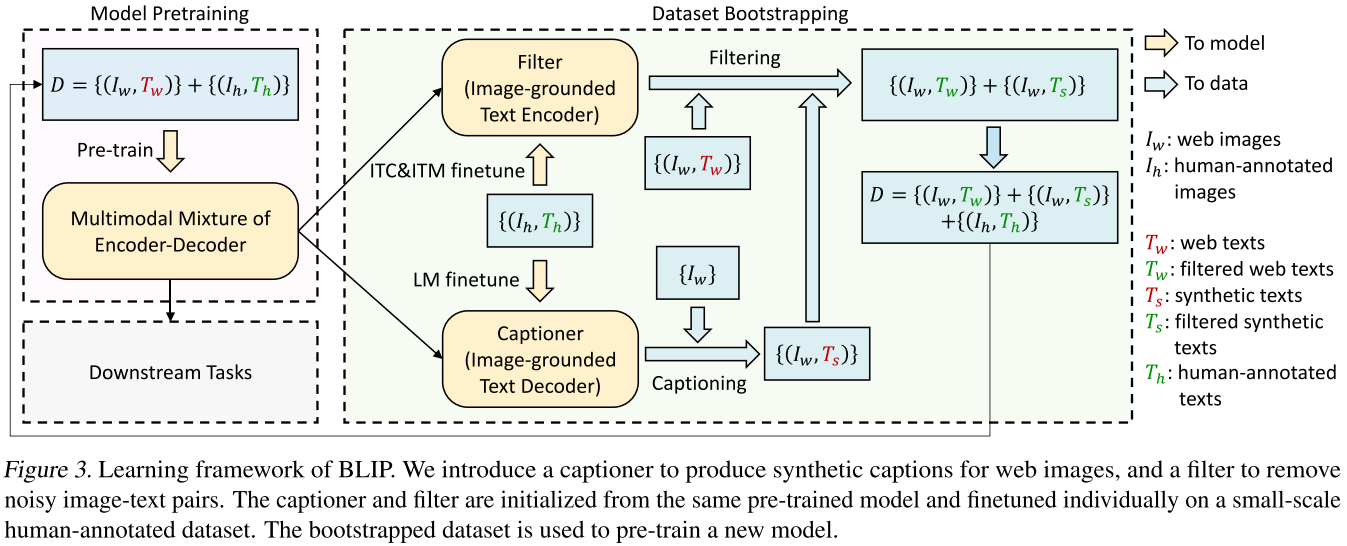
- 이 논문에서는 데이터셋의 품질을 향상시킬 수 있는 CapFilt를 제안한다.
- CapFilt는 Captioner와 Filter로 나뉘는데, Captioner는 주어진 웹 이미지로부터 캡션을 생성하고 Filter는 노이즈로 취급될 수 있는 Image-Text pair를 제거한다.
Captioner
- Captioner는 위에서 언급한 Image-grounded text decoder이다.
- LM(Language Modeling Loss)로 파인튜닝되어 주어진 이미지로부터 텍스트를 생성한다.
- 웹 이미지 $I_w$ 를 입력으로 받으면 캡션 $T_s$ 를 생성하는 역할인 것이다.
Filter
- ITC(Image-Text Contrastive loss)와 ITM(Image-Text Mathcing loss)으로 파인튜닝되어 텍스트가 이미지와 일치하는지 학습한다.
- 노이즈가 있을 수 있는 원본 웹 캡션 $T_w$ 와 생성된 캡션 $T_s$ 로부터 Noise라고 판단되면 데이터를 제거하는 것이다.
- Noise라고 판단하는 것은 Binary classficiation을 통해 판단한다.
- 이렇게 Captioner로부터 생성된 캡션과 원본 웹 캡션, 사람이 어노테이션한 데이터를 모두 합쳐 새로운 데이터셋으로 만든다.
- 이 새로운 데이터셋으로 모델을 다시 Pre-training하면 BLIP이 완성된다.



