
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 에지 검출
- clip
- E2E 자율주행
- res
- 딥러닝 목적함수
- res paper
- mobilenetv1
- gsoc
- 딥러닝 엔트로피
- object detection
- 객체 검출
- 논문 요약
- blip-2
- transfuser++
- grefcoco
- clip adapter
- 1차 미분 마스크
- gres
- 엔트로피란
- 이미지 필터링
- 논문 리뷰
- gsoc 2025
- referring expression segmentation
- google summer of code
- grefcoco dataset
- vlm
- Object detection article
- 원격 학습 안끊기게
- TransFuser
- gsoc 후기
- Today
- Total
My Vision, Computer Vision
[논문 리뷰/요약] ALIGN : Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision 본문
[논문 리뷰/요약] ALIGN : Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
gyuilLim 2025. 1. 20. 19:31
Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
Pre-trained representations are becoming crucial for many NLP and perception tasks. While representation learning in NLP has transitioned to training on raw text without human annotations, visual and vision-language representations still rely heavily on cu
arxiv.org
Abstract
- NLP에서 Representation Learning은, 사람의 Annotation없이 Raw(원시) text를 학습하는 형태로 변화하고 있다.
- 하지만 Visual, Vision-language 모델은 여전히 비용이 많이들고, 전문적인 지식이 필요한 데이터셋에 의존하고 있다.
- Vision-language에서 주로 쓰이는 데이터셋인 Conceptual Captions, MSCOCO, CLIP(WIT)는 데이터를 수집하기 위해 Process 과정을 거친다.
- 이 과정은 많은 비용을 요구하기 때문에, 데이터셋의 크기를 제한한다.
- 본 논문에서는 Conceptual Captions에서 사용된 (비싼)전처리 과정없이, 10억개 이상의 Image, Alt-Text 쌍으로 이루어진 데이터셋을 구축한다.
- 여기서 Alt-text란, HTML에서 사진에 대해 설명하는 텍스트를 말한다.
# Alt-text
<img src="cat.jpg" alt="A fluffy white cat sitting on a sofa">
1. Introduction
- Visual, Vision-language는 각각 다른 데이터셋에서 연구되었다.
- VIsion 도메인에서는 ImageNet, OpenImages, JFT-300M 등에서 Pre-training하는 것이 다운스트림 태스크에 적용하는 데 도움이 된다는 것으로 입증되었다.
- Vision-language에서도 마찬가지로 Pre-training이 사실상 표준적인 접근 방식이 되어가고 있다.
- 하지만 Conceptual Captions, Visual Gnome Dense Captions, ImageBERT 등 Visual-language 도메인에서 사용하는 데이터셋은 Annotation, Semantic parsing, Cleaning, Balancing 등에 더 많은 비용이 필요하기 때문에, Visual 도메인보다 약 10배 이상 작은 규모인 천만개 정도이며, 이는 NLP pre-training에서 사용되는 말뭉치 데이터셋에 비해 훨씬 적다.
- 본 논문에서는 약 10억개 이상의 Noisy Image, Text 쌍 데이터셋을 구축한다. Conceptual Captions dataset의 구성 절차는 따르되, 복잡한 필터링이나 후처리 작업은 제거하고, 빈도 기반(Frequency-based) 필터링만 적용한다.
- 결과적으로 Noise가 생기지만, Conceptual Captions보다 약 100배 이상 크고, 이 데이터셋으로 Pre-training하여 성능을 입증했다.
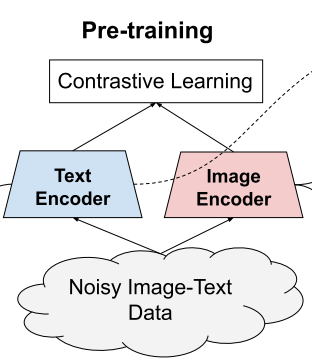
- 또한 Dual-encoder 구조를 Contrastive loss로 학습하여 모델을 구축한다. 이 모델을 ALIGN: A Large-scale ImaGe and Noisy-text embedding이라고 한다.
2. Related Work
- 이 연구와 밀접하게 관련된 CLIP과의 주요 차이점은 Training data에 있다.
- CLIP에서 사용하는 Pre-training dataset인 WIT(Web Image Text)는 영어 위키피디아에서 주로 등장하는 High-frequency allowlist를 만들지만, ALIGN은 Natural distribution을 따르는 Raw alt-text data을 사용한다.
- Natural distribution을 따른다는 것은 인터넷에서 별도의 (변형)조건없이 데이터를 수집했다는 의미이다.
3. A Large-Scale Noisy Image-Text Dataset
- 본 연구의 초점은 Visual, Vision-language representation learning의 스케일을 키우는 것이다.
- 이를 위해, 기존 데이터셋보다 훨씬 큰 데이터셋을 구축한다. 특히, Conceptual Captions의 데이터셋 구축 매커니즘을 따르지만, 복잡한 필터링과 후처리 과정을 완화하여, 최소한의 Frequency-based(빈도 기반) 필터링만 적용했다.
- 결과적으로 크기가 18억개로 더 커졌지만 더 Noise가 포함된 데이터셋을 구축했다.

- 위 그림은 랜덤하게 샘플된 데이터셋의 일부 예시를 보여주는 것이다.
- 두번째 예시인 “thumbnail for version as of 21 57 29 june 2010”를 보면, 이는 이미지에 대한 설명이 아니라 이미지의 메타 데이터로 볼 수 있다. 즉 Noise인 것이다.
Image-based filtering
- 이미지를 기반으로 실행되는 필터링이다. 필터링 기준은 아래와 같다.
1. 윤리, 법적인 문제를 이유로 Pornographic images 제거.
2. 최소 길이 200 픽셀, Aspect ratio 3 이하.
3. Alt-text가 1000개 이상인 경우 제거.
4. Test image 혹은 Downstream task의 evaluation dataset인 ImageNet, Flickr30K, MSCOCO 이미지이거나, 유사한 이미지인 경우 제거.
Text-based filtering
- 텍스트를 기반으로 실행되는 필터링이다. 필터링 기준은 아래와 같다.
1. ”1920x1080”, “alt_img”, “christina” 등과 같이 Alt-text가 10개 이상의 이미지에서 겹치면 제거.
2. Raw dataset을 기준으로 빈도 순으로 정렬했을 때, 1억번째 미만인 경우 제거.
3. Token의 개수가 3 미만, 20 초과인 경우 제거.
4. Pre-training and Task Transfer
4.1. Pre-training on Noisy Image-Text Pairs
- ALIGN은 Image encoder와 Text encoder로 이루어진 Dual-encoder 구조이다.
- Image encoder는 EfficientNet, Text encoder는 BERT 사용.
- 각 Encoder들은 From scratch로 학습된다.
- Image encoder와 Text encoder는 Normalzied soft max loss를 통해 최적화된다.
- 학습에서, 매칭된 Image-text pair는 Positive로 취급하고, 배치 내 다른 Image-text pair는 Negative로 취급한다.
- Loss 함수는 Image-to-text classification, Text-to-image classification 두 가지로 계산한 후 합한다.
$$ L_{i2t} = -\frac{1}{N} \sum^N_i \log \frac{\exp (x^T_i y_i / \sigma)}{\sum^N_{j=1}\exp(x^T_i y_j/\sigma)} $$
$$ L_{t2i} = -\frac{1}{N} \sum^N_i \log \frac{\exp(y^T_i x_i / \sigma)}{\sum^N_{j=1} \exp(y^T_i, x_j / \sigma)} $$
- 여기서 $x_i, y_i$ 는 각각 $i$ 번째 이미지, $j$ 번째 텍스트, $N$ 은 배치 크기이다.
- $\sigma$ 는 logits 값을 스케일링하기 위한 Temperature 변수인데, 이 변수는 두 개의 임베딩 벡터 $x_i, y_i$ 가 L2 정규화되기 때문에 필요하다.
벡터는 크기와 방향으로 이루어져있는데, 두 벡터의 유사도를 구하기위해선 각 벡터의 크기를 1로 만들어준 후 방향으로 유사도를 계산한다.
따라서 벡터의 크기를 구한 후 나누어준다.
이 때, 벡터의 크기를 구하기 위해 사용하는 방법이 L2 정규화이다.
벡터의 크기가 1이기 때문에, 스케일링을 위해 Temperature 변수가 필요한 것이다.
- Temperature 파라미터는 튜닝하지않고 학습으로 찾아내는것이 더 효과적이었다.
4.2. Transferring to Image-Text Matching & Retrieval
- 저자들은 ALIGN 모델을 Flickr30K, MSCOCO 데이터셋을 사용하여 Image-to-text, Text-to-image retrieval 작업에서 평가한다.
4.3. Transferring to Visual Classficiation
- ALIGN을 Classification task에서 평가하기 위해, ImageNet의 여러 버전을 사용한다.
- ImageNet-R : 미술, 만화, 스케치 등 Non-natural 이미지가 추가된 버전.

- ImageNet-A : ResNet 모델이 잘못 분류한 이미지를 추가한 버전.

- ImageNet-V2 : ImageNet을 보완한 버전
- 위 데이터셋(ImageNet-R, ImageNet-A, ImageNet-V2)은 모두 ImageNet과 같은 클래스를 가지고있고, ImageNet-R과 ImageNet-A는 ImageNet과 다른 분포에서 샘플링되었다.
- 또한 Downstream classification task를 평가하기 위해, ImageNet뿐만 아니라 Oxford Flowers-102, Oxford-IIIT Pets, Stanford Cars, Food101등의 Fine-grained 데이터셋을 사용한다.
- ImageNet에서는 두 가지 설정이 사용됐는데, ALIGN을 고정한 후 추가된 Classification layer만 학습하거나, 전체적으로 Fine tuning한 것이다. 나머지 데이터셋은 모두 Fine tuning하여 평가했다.
5. Experiments and Results
Image Encoder
- EfficientNet을 사용했고, 289 * 289 크기의 해상도로 훈련되었다.
- 입력 이미지를 346 * 346으로 Resize한 후, 학습에서는 Random crop, 테스트에서는 Cetral crop을 사용했다.
Text Encoder
- BERT를 사용했고, 최대 64토큰으로 설정.
- Temperature 변수는 1.0으로 초기화.
- Softmax loss에서 Label smoothing 파라미터를 0.1로 설정.
- LAMB(Large Batch) optimizer, weight decay는 1e-5로 설정.
- Learning rate은 10k steps에 걸쳐 0에서 1e-3으로 선형적으로 증가.
- 1024개의 Cloud TPUv3에서 훈련되었고, Batch size는 16384.
5.1. Image-Text Mathcing & Retrieval
- Cross modal retrieval 벤치마크 평가를 위해, Flickr30K, MSCOCO dataset에서 Zero-shot evaluation과 Fully fine-tunning을 각각 측정했다.
- Fine-tuning에는 Pre-training과 동일한 Loss 함수가 사용되고, 배치 크기를 16384에서 2048로 감소시켰다.
- 또한 학습률을 1e-5로 낮추었다.

- 위 표는 Flickr30K, MSCOCO에 대해 Zero-shot 성능과 Fine-tuned 성능을 비교한 것이다.
- R@K는 Recall at K로, 상위 K개의 검색 결과 중에서 정답이 포함되어있는 비율을 의미한다.
- Zero-shot, Fine-tuned 모두 ALIGN이 CLIP에 비해 우세한 것을 확인할 수 있다.
5.2. Zero-shot Visual Classification
- Class의 이름을 Text encoder의 입력으로 넣으면 Classification이 가능해진다.
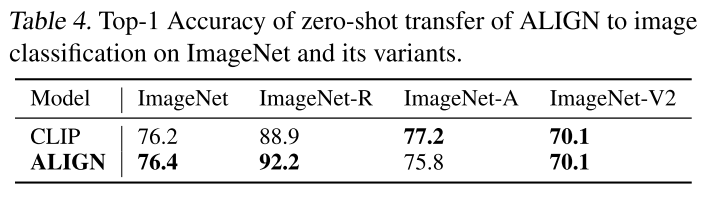
- 위 표는 ALIGN과 CLIP을 ImageNet과 변형 데이터셋에 대해 Classification 결과를 비교한 것이다.
- 공정한 비교를 위해 CLIP의 프롬프트 앙상블을 사용했다.
- ImageNet, ImageNet-R은 ALIGN이 더 우세하고, ImageNet-A는 CLIP이 더 우세하다.
5.3. Visual Classification w/ Image Encoder Only

- ImageNet은 앞에서 말했던 두가지 설정으로 나누어서 평가한다. 첫번째는 ALIGN을 고정한 후 Classification layer를 뒤에 붙여 학습시키는 것(Acc@1 w/ frozen features)이고, 두번째는 전체적으로 파인 튜닝하는 것이다.(Fully Fine-tuning, Acc@1, Acc@5)
- Random crop과 Horizontal flip을 사용하고 Test에서는 비율이 0.875인 Central crop사용한다.
- 그리고 Random crop에서 발생하는 해상도 차이를 완화하기 위해, Train/Test 해상도가 각각 289/360으로 설정된다.
- Fully Fine-tuning에서는 475/600으로 적용한다.
- Frozen features에서 ALIGN이 CLIP에 비해 0.1% 높다.
Conclusion
- 본 논문은 Visual, Vision-language representation learning에서 대량의 Noisy image-text data를 활용하는 방법을 제시한다.
- 이 방법은 데이터 선별, 어노테이션 등에 의존하지 않고 간단한 필터링 작업만으로 데이터셋을 구축한다.
- 구축된 데이터로부터 간단한 Dual-encoder 구조의 모델을 학습시켜 SOTA를 능가하였다.



