
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- object detection
- clip
- clip adapter
- google summer of code
- 원격 학습 안끊기게
- grefcoco dataset
- 딥러닝 목적함수
- gsoc 2025
- vlm
- E2E 자율주행
- 객체 검출
- Object detection article
- grefcoco
- blip-2
- gres
- 이미지 필터링
- res
- mobilenetv1
- gsoc
- TransFuser
- res paper
- 딥러닝 엔트로피
- 에지 검출
- 논문 요약
- 논문 리뷰
- transfuser++
- 엔트로피란
- gsoc 후기
- 1차 미분 마스크
- referring expression segmentation
Archives
- Today
- Total
My Vision, Computer Vision
[논문 리뷰/요약] VGA: Vision GUI Assistant - Minimizing Hallucinations through Image-Centric Fine-Tuning 본문
Paper
[논문 리뷰/요약] VGA: Vision GUI Assistant - Minimizing Hallucinations through Image-Centric Fine-Tuning
gyuilLim 2024. 11. 21. 14:12VGA: Vision GUI Assistant -- Minimizing Hallucinations through Image-Centric Fine-Tuning
Recent advances in Large Vision-Language Models (LVLMs) have significantly improve performance in image comprehension tasks, such as formatted charts and rich-content images. Yet, Graphical User Interface (GUI) pose a greater challenge due to their structu
arxiv.org
Abstract
- 기존 VLM은 시각적 입력을 무시하고 텍스트에 과도하게 의존하는 경우가 많음
- 여기서 발생하는 부정확성은 'hallucinations'이라고 하며, 모델이 GUI 요소에 대한 시각적 검증 시 잘못되거나 비논리적인 응답을 생성하는 경우를 말함
- 이러한 문제를 해결하기 위해, 우리는 포괄적인 GUI 이해를 위해 Fine-tuned model인 VGA를 소개한다.
1. Introduction

- VLM은 다양한 유형의 데이터를 Latent space로 매핑하는 Visual-language projector를 사용하여 시각 및 언어 정보를 효과적으로 처리할 수 있다.
- GUIs는 복잡한 과제를 제시한다. Can the success ofVLMs be applied to the GUI domain?
- 기존 컴퓨티 비전 기술은 GUI 구성 요소를 식별하는 데 중점을 두지만, 그래픽 및 텍스트 정보, 레이아웃, 인터페이스 내 상호 작용 맥락을 완전히 이해하지 못한다.
- 반면 ferret-UI와 CogAgent와 같이 LVLM을 활용하는 최신 접근 방식은 이 영역에서 상당한 이점을 보여준다.
- ferret-UI(You et al., 2024)와 CogAgent(Hong et al., 2023)는 사전 훈련된 지식에 과도하게 의존하여 중요한 시각적 콘텐츠를 간과(Hallucinations)
- 이러한 문제를 해결하기 위해 자체적으로 구성한 63,800개의 데이터셋으로 새로운 훈련 방법(Novel train method)로 파인 튜닝된 모델인 VGA를 제안한다.
- Contributions는 아래와 같다.
1. Large-scale GUI corpus for LVLM Fine-tuning
2. A Fine-tuned LVLM for GUI task
3. A Fine-tune Method to efficient improve LVLMs
4. performancePerformance enhancements on real-world GUI tasks.
3. Problem in GUI Comprehension
- 비전-언어 모델(VLMs)에서 환각의 주된 원인은 기존의 대규모 언어 모델(LLMs)로부터 학습된 응답 패턴에 대한 의존성 때문
3.1. Hallucination in GUI Comprehension
- 시각 모듈이 추가되면, 이렇게 학습된 텍스트 응답 패턴이 다중 모드 작업 중 모델의 동작에 부정적인 영향
- 이러한 텍스트 중심의 편향은 다음과 같은 환각으로 이어짐
- Over-reliance on textual content : 텍스트 데이터를 과도하게 우선시하는 경향
- Word-to-image coincidences : 요소가 의도된 기능적 요구 사항과 일치하지 않는 경우 발생

3.2. Referent Method
- 앞서 언급된 문제를 해결하기 위해 Referent Method을 제안함
- GUI 디자인은 레이아웃, 모양 및 색상으로부터 사용자에게 시각적 정보 제공
- 데이터셋 구성 시 Component의 좌표, 모양, 색상 및 상대적 위치를 명시적으로 포함시킴으로써, 모델이 응답 생성 시 이미지 콘텐츠에 더 집중하는 것을 목표
- 데이터셋 설계 과정에서 다음 참조 요소 중 적어도 하나가 포함되도록 하여 이미지와 Component를 일치시킴
- 모양(Shape): Component의 모양(둥근 모서리가 있는 직사각형 버튼)
- 색상(Color): Component의 색상(흰색 텍스트가 있는 파란색 버튼)
- 위치(Position): Component의 정확한 좌표 또는 경계(<x,y> 및 <x1,y1,x2,y2> 형식으로 표현)
- 상대적 위치(Relative Position): 다른 Component와 관련된 요소의 위치(텍스트 입력 필드 아래에 있는 것)
4. GUI Comprehension Dataset
- 이 데이터셋에는 텍스트 및 시각적 요소에 대한 상세한 주석이 포함되어 균형 있고 포괄적인 훈련 환경을 보장
4.1. Existing General Dataset
- Ferret-UI(You et al., 2024)와 CogAgent(Hong et al., 2023)는 훈련 데이터셋을 구성할 때 주로 텍스트와 위치 정보를 추출하고 활용하는 데 중점을 둠
- 텍스트와 레이아웃에만 의존하면 그래픽 인터페이스의 의미와 기능을 완전히 이해하지 못할 수 있음
- 이러한 모델들이 사용하는 데이터셋은 공개되지 않았기 때문에, 외부 연구자나 개발자에게 추가적인 어려움 야기
4.2. Data collection
- Rico 데이터셋은 모바일 앱 디자인 및 개발을 위해 만들어진 GUI 데이터셋
- 27가지 범주에서 6만 6천개의 GUI 화면과 3백만 개의 Component로 구성
- Rico(2017) 데이터셋을 VQA 데이터셋과 같은 형식으로 변환해야함
4.3. Task Design
- Data Pre-processing : Visible-to-user 속성이 False로 설정된 Element 제거, Bounds 값을 0~1 정규화, ‘Clickable’ 속성이 True로 설정된 Element에 대해 Click cordinate 속성 추가(Bounds 중점)
- GPT-4(Text-Only) Generated Tasks : 안드로이드 뷰 계층 구조 정보를 활용하여 텍스트 및 위치 데이터와 상호 작용을 정확하게 반영하는 다양한 QA 쌍을 생성
- GPT-4o(Image-Based) Generated Tasks : GUI Component의 상대적 위치, 모양, 색상 등 시각적 특징을 바탕으로 질문에 답할 수 있도록 훈련 데이터를 생성

- Instruction following(35.8%, GPT-4o), Conversation(60.2%, GPT-4o)
5. Tuning Script
- 기존의 LVLM 미세 조정 방법은 질문 토큰과 이미지 토큰을 동등하게 다루는데, 이는 LVLM이 이미지 정보를 우선시해야 할 필요성을 간과한 것
- 이를 해결하기 위해 Two-stage training method 제안
Foundation Stage
- Instruction following dataset 사용
- 명령어와 응답 형식을 고정하여 모델이 시각 데이터를 인식하고 해석하는 견고한 능력을 개발
Advanced Comprehensive Stage
- Muilti-turn dialogues, 복잡한 질문 도입
- Referent Method를 사용하여 시각 정보를 응답에 사용
- 모델이 단순히 학습된 텍스트 패턴에 의존하는 것이 아닌 시각적 정보를 더 활용하게됨
6. Experiment
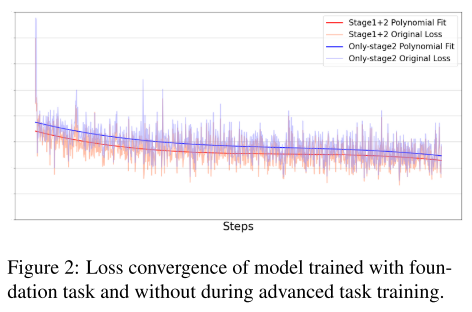
- 위 로스 그래프에서 Stage2(Advanced comprehensive stage)만 사용한 경우(파란색)보다 Stage1(Foundation stage)과
2를 모두 사용한 경우(빨간색)의 Loss가 더 낮은 것을 확인할 수 있음

- 각 테스트는 22개의 샘플 이미지와 44개의 질문을 이용하여 Score를 측정한다.
- VGA-7b-v1 모델이 타 모델에 비해 성능이 높은 것을 확인할 수 있다.
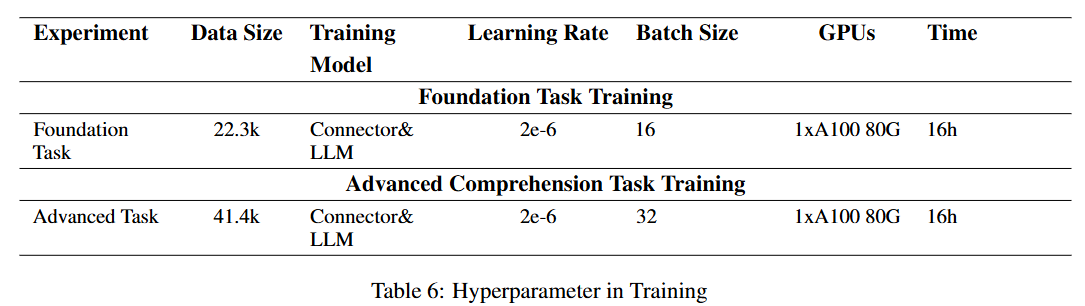
- Foundation task와 Advance task는 각각 약 2만 2천개, 4만 1천개의 데이터로 구성된다.
- GPU는 A100(80G)를 사용했다.
728x90
'Paper' 카테고리의 다른 글
'Paper' Related Articles
more



