
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- 이미지 필터링
- 객체 검출
- 원격 학습 안끊기게
- blip-2
- res
- object detection
- TransFuser
- gres
- 딥러닝 엔트로피
- res paper
- gsoc
- clip
- grefcoco
- transfuser++
- 에지 검출
- google summer of code
- referring expression segmentation
- 엔트로피란
- gsoc 후기
- 1차 미분 마스크
- 딥러닝 목적함수
- gsoc 2025
- grefcoco dataset
- vlm
- E2E 자율주행
- clip adapter
- Object detection article
- 논문 리뷰
- 논문 요약
- mobilenetv1
Archives
- Today
- Total
My Vision, Computer Vision
[논문 리뷰/요약] Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text DatasetFor Automatic Image Captioning 본문
Paper
[논문 리뷰/요약] Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text DatasetFor Automatic Image Captioning
gyuilLim 2025. 1. 21. 14:00[논문 링크 : https://aclanthology.org/P18-1238.pdf]
Abstract

- 본 논문은 Conceptual Captions라는, 이미지 캡션으로 어노테이션된 데이터셋을 제시한다.
- 이 데이터셋은 이미지 캡션에서 주로 사용되는 데이터셋인 MS-COCO보다 약 20배 많은 330만개이다.
- 약 10억개의 웹페이지로부터 이미지, 텍스트를 추출하고 필터링하여 데이터셋을 구축한다.
1. Introduction
- 딥러닝 모델의 발전으로 Automatic image description Task도 발전하고있다.
- 이 분야에서는, Computer vision과 Natural Language Processing의 교집합을 어떻게 다루는지가 중요하다.
- 본 논문에서는 두 가지 Contribution을 제시한다.
- 첫번째는 새로운 Image caption dataset인 Conceptual Captions를 제안하는 것이다.
- 웹 이미지에 있는 Alt 속성으로부터 이미지와 캡션을 추출하여 약 330만 개의 (Image, Description) pair를 구축한다.

- 위와 같은 자동화된 파이프라인을 구축하여 Image/caption을 추출, 필터링, 변환한다.
- Image와 Alt-text를 이미지 필터링, 텍스트 필터링, 이미지/텍스트 필터링, 텍스트 변환 과정을 통해 데이터를 정제하고 선별한다.
- 두번째는 Image-captioning 모델들을 평가하는 것이다.
- Image-feature extraction으로는 Inception-ResNet-v2를 사용했고, Caption generation으로는 RNN 기반 모델과 Transformer 기반 모델을 사용했다.
2. Related Work
- COCO dataset은 약 16만장으로, DNN을 학습하기에 크지 않은 양이다.(ImageNet은 약 128만개)
- 그럼에도 주로 사용되는 데이터셋인 이유는 객체의 Non-iconic, Non-canonical한 장면으로 구성되어 있기 때문에, 일상의 장면을 잘 나타내기 때문이다.
- 본 연구와 관련된 또 다른 데이터셋으로, Pinterest image and sentence-description이 있는데, 이 데이터셋은 텍스트가 이미지를 잘 묘사하지 않기때문에 학습에 사용하기에는 어려움이 있다.
3. Conceptual Captions Dataset Creation
- Flume(분산 데이터 수집 프레임워크)를 통해 인터넷 웹 페이지에서 전처리 전, 후보 (Image, Caption) pair를 추출한다.
1. Image-based Filtering
- 첫번째 필터링 단계로, 조건에 충족하지 않는 이미지는 제거하는 과정이다.
- 이미지 포맷이 JPEG이어야 함.
- 높이, 너비의 최소 길이가 400 픽셀이어야함.
- 가로, 세로의 비율이 2 이하여야함.
- Pornography(음란물), Profanity(비속어)가 감지되지 않아야한다.
- 이 과정을 통해 후보 이미지의 65%가 제거된다.
2. Text-based Filtering
- 두번째 필터링 단계로, 텍스트에 기반하여 데이터를 제거하는 과정이다.
- Alt-text를 사용하는데, Alt-text는 HTML의 속성이고 이미지에 대한 Description 정보를 담고있다.
- 텍스트 필터링에 적용되는 휴리스틱 규칙은 다음과 같다.
- 한정사, 명사, 전치사가 포함되어야 함.
- 명사 비율이 지나치게 높지 않아야 함.
- 토큰 반복률(Token repetition rate)이 높지 않아야 함.
- 첫 번째 단어가 대문자로 시작하지 않거나, 대문자 비율이 높은 경우 제거.
- English Wikipedia에서 5번 이상 등장한 토큰으로 Vocab을 구성하여, 여기에 속하지 않으면 제거.
- 음란물/비속어라고 탐지된 경우 제거.
- “Click to enlarge picture(크게 보려면 클릭)”, “Stock photo(스톡 이미지)”, “Embedded image permalink(임베디드 링크 제공)”, “Profile photo(프로필 사진)” 등 사전 정의된 텍스트에 해당되면 제거.
- 이 과정을 통해 후보 데이터 중 3%만 남게된다.
3. Image&Text-based Filtering
- Google Cloud Vision API를 통해, 10만 개의 라벨을 할당할 수 있는 모델을 사용한다. 이 때, 10만 개의 라벨은 모두 Vocab에 포함되어있다.
- 이미지에는 약 5개에서 20개 정도의 라벨이 할당되고, 레이블 수는 이미지에 따라 다르다.
- 이미지에 할당된 라벨과 후보 텍스트를 비교하여 매칭되지 않는 (Image, Text) pair는 제거한다.
- 이 과정에서 입력된 후보 데이터의 약 60%가 필터링된다.
4. Text Transformation with Hypernymization
- 위 과정에서 전체 후보 데이터 중 약 0.2%만 남게 되는데, 그 데이터들은 아래와 같다.

- 위 그림에 있는 Alt-text를 보면, 고유 명사(사람, 장소, 위치 등)이 아직 남아있는 것을 알 수 있고, 이 고유 명사를 상위 개념으로 치환하기 위한 과정을 거친다.
- 먼저 Google Cloud Natural Langauge API로 고유 명사를 추출하고, Google Knowledge Graph search API로 추출된 고유명사에 대한 Hypernym(상위 개념)을 찾는다.
- 예를들어, “Harrison Ford”, “Calista Flockhart” 등의 이름 속성은 “Actor”로 바뀌게 되는것이다.
- Text Transformations의 과정은 다음과 같다.
- 고유 명사, 숫자, 단위 등 특정 유형의 명사 수식어 제거.
- 날짜, 기간, 위치 명(ex. “in Los Angeles”) 제거.
- 추출된 개체를 식별한 후 Knowledge Graph와 매칭시키고 해당 Hypernym으로 교체.
- “Actor and Actor”와 같은 경우, 복수형 “Actors”로 변환.
- 이 변환 과정에서 약 20%의 후보가 제거된다.
- 각 개체(”Actor”, “Dog”, “Neighborhood” 등)의 개수가 후보 데이터에서 100개 미만인 경우 제거하여 약 55%의 후보 데이터만 남긴다.
Conceptual Captions Quality
- 구축된 데이터셋의 퀄리티를 평가하기 위해 Huamn Evlauation을 진행한다.

- 3명의 사람에게 데이터 샘플 4000개를 추출하여 GOOD/BAD 라벨을 부여하게 한다.
- 위 표는 이미지에 대해 GOOD이 최소 1개인 경우 96.9%, 2개인 경우 90.3%, 3개인 경우 78.5%라는 것을 보여준다.
4. Image Captioning Models

- Image captioning 모델은 위와 같이 구축했다.
- CNN으로 이미지 임베딩을 추출한 후, RNN 또는 Transformer의 Encoder, Decoder로 Caption을 학습하는 구조이다.
- 자세한 설명은 논문을 참고할 것.
5. Experimental Results
- Image Captioning 모델을 이용해 실험한 결과를 제시한다.
- 실험은 Conceptual Captions dataset, COCO dataset으로 각각 학습시킨 후 3개의 Test data에 적용한다.
- Test data는 COCO-C40, Conceptual test set, Flickr 1K test set이다.
- COCO-C40은 COCO에 도메인이 맞춰져있고, Conceptual test set은 Conceptual Captions에 도메인이 맞춰져있다. Flickr 1K test set은 두 데이터셋 모두 맞춰져있지 않다.

- 위 표는 각각 COCO, Conceptual로 훈련한 모델이 이미지에 대해 추론한 캡션에 Human evaluation을 적용한 것이다.
- Coceptual로 학습한 결과가 대체로 높은 것을 확인할 수 있다.
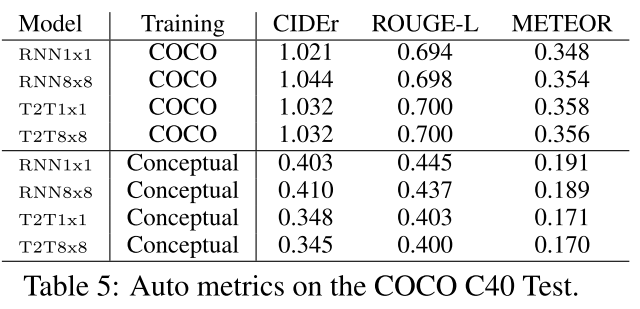
- 위 표는 COCO C40에 대한 테스트 결과를 보여준다.
- Evaluation metric으로 3개의 Auto metrics(CIDEr, ROUGE-L, METEOR)를 사용했다.
- CIDEr : 단어 일치 기반
- ROUGE-L : LCS(Longest Common Substring) 기반
- METEOR : 단어의 동의어, 형태 변화를 반영하여 평가
- COCO dataset과 도메인이 유사한 Test dataset이기 때문에, COCO로 훈련한 모델이 더 높은 것을 확인할 수 있다.
- Conceptual Captions Test set에서 평가한 모델이다.
- 마찬가지로 Conceptual Captions dataset과 유사한 도메인이기 때문에, Conceptual로 훈련한 모델이 더 높게 측정됐다.

- 위 표는 Flickr 1K Test set으로 평가한 결과이다. COCO로 훈련한 모델이 Conceptual로 훈련한 모델보다 더 성능이 좋다는 것을 확인할 수 있다.
- 이 논문에서 저자는 Auto metrics 결과가 Human Evaluation 결과를 뒷받침하지 못한다고 주장하며, 아직 인간이 평가하는게 더 우수할 것이라고 말한다.
- Hallucination이 발생했을 때, Auto metrics는 작은 패널티만 부여되는 반면, 인간 평가에서는 점수가 급격하게 떨어진다는 것도 이유로 들었다.
6. Conclusions
- 본 논문에서는 새로운 Image captioning dataset인 Conceptual Captions를 제시했다.
- 약 330만 개의 데이터로 구성되어있다.
- 또한 이 데이터셋으로 학습한 결과, COCO dataset으로 훈련한 모델에 비해 Hallucination이 덜 나타나는 것으로 확인되었다.
728x90
'Paper' 카테고리의 다른 글
'Paper' Related Articles
more



