
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 딥러닝 목적함수
- transfuser++
- TransFuser
- 이미지 필터링
- res paper
- grefcoco dataset
- 엔트로피란
- grefcoco
- gsoc 후기
- 1차 미분 마스크
- vlm
- gsoc 2025
- 객체 검출
- Object detection article
- E2E 자율주행
- mobilenetv1
- object detection
- 원격 학습 안끊기게
- 딥러닝 엔트로피
- gsoc
- google summer of code
- referring expression segmentation
- 에지 검출
- clip adapter
- res
- blip-2
- clip
- gres
- 논문 요약
- 논문 리뷰
- Today
- Total
My Vision, Computer Vision
[논문 요약/리뷰] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning 본문
[논문 요약/리뷰] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
gyuilLim 2025. 2. 4. 17:11DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
We introduce our first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1. DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step, demonstrates remarkable reasonin
arxiv.org
Abstract
- 본 논문에서는 DeepSeek-R1-Zero와 DeepSeek-R1이라는 모델을 소개한다.
- DeepSeek-R1-Zero는 Supervised Fine-tuining 과정을 거치지 않고 대규모 강화 학습만을 통해 Base model(DeepSeek-V3-Base)를 훈련시킨 버전이다.
- DeepSeek-R1은 DeepSeek-R1-Zero의 Language mixing(언어 혼합) 문제 해결 및 SFT를 거친 버전이다.
- 또한, DeepSeek-R1은 OpenAI-o1-1217과 대적한다.
1. Introduction
- 최근, Post-training(Transfer learning, Fine tuning)이 전체 훈련 과정에서 중요한 구상 요소로 부상했다. 또한 Post-training은 Pre-training에 비해 상대적으로 적은 자원이 들어간다.
- OpenAI의 o1 시리즈 모델은 추론 과정의 길이를 늘림으로써(Chain-of-Thought, 사고의 연쇄) 추론 시간을 확장하는 매커니즘을 처음으로 도입했으나 테스트 시간(추론 시간)이 늘어나는 것은 여전히 해결해야 하는 문제다.
- 이 논문은, Post-training 단계에서, Supervised data 없이, 순수하게 강화 학습만으로 LLM의 잠재력을 탐구하는 것을 목표로 한다.
1.1 Contributions
- DeepSeek-R1 논문의 Contribution은 두 가지인데, 다음과 같다.
- Post-training. Pre-training된 모델을 한번 더 학습하는 과정이다. 일반적인 LLM과 다르게, 강화 학습만을 사용하여 모델이 독립적으로 추론 능력을 개발하도록 한다. 이게 무슨 말이냐면, 강화 학습으로 학습하기 때문에 모델이 자신의 출력을 평가하고 확인하는 Self-verification이 가능해진 다는 것이다.
여기서 알아두어야 할 것은, 강화학습을 Supervised learning을 거친 DeepSeek-V3-Base 모델에 적용한다는 것이다.
즉 처음부터 강화학습만을 사용해서 모델을 만들어낸 것이 아니라, Supervised learning으로 Pre-training이 끝난 베이스 모델에 강화학습을 적용하는 것이다.
- Distillation. DeepSeek-R1을 더 작은 모델에 전이해도 벤치마크에서 뛰어난 성능을 보이는 것으로 나타났다.
Distillation이란, Knowledge distillation(지식 증류)으로, 큰 모델을 더 작은 모델로 전이하는 과정이다.
여러가지 방법이 있는데, Knowledge distillation의 목표는 큰 모델의 확률 분포를 작은 모델이 가지게 하는 것이다. 근사(Approximation)라고 볼 수 있다.
1.2 Summary of Evaluation Results
Reasoning Tasks(추론 작업)
- AIME 2024에서는 79.8%을 달성하여 OpenAI-o1-1217보다 약간 높다.
- MATH-500에서는 97.3%로, OpenAI-o1-1217과 동등한 정도이다.
- 코딩 관련 작업(Codeforces)에서, 2,029 Elo 등급을 달성하며 96.3%의 인간 참가자들을 제치는 성과를 보인다.
AIME 2024 : 미국의 중학생 및 고등학생을 대상으로 하는 수학 경시 대회.
MATH-500 : 특정 수학 문제 세트를 포함하는 벤치마크.
Codeforces : 프로그래머들과 개발자들이 코딩을 연습하고 경쟁하는 플랫폼.
Knowledge(지식)
- MMLU, MMLU-Pro, GPQA와 같은 벤치마크에서 DeepSeek-V3보다 크게 향상되었지만 OpenAI-o1-1217에는 약간 뒤처진다.
MMLU(Massive Multitask Language Understanding) : 다양한 언어 이해 작업을 평가하기 위한 벤치마크.
MMLU-Pro : MMLU의 확장된, 향상된 버전.
GPQA(Generalized Programmatic Question Answering) : 질의 응답 시스템을 평가하기 위한 벤치마크.
2. Approach
2.1 Overview
- 이전 LLM들은 Post-training(Fine-tuning) 단계에서, 대량의 Supervised data에 의존하는 경향이 있다.
Supervised data 란, 타겟(정답)이 있는 데이터를 말한다. 번역, 감정 분석 등이 있다.
- 이 연구에서는 Supervised fine-tuning(SFT) 없이 대규모 강화 학습을 통해 추론 능력을 향상 시킬 수 있다는 것을 보여준다.
- 또한, 소량의 Cold-start 단계에서 소량의 Data를 사용하여 성능을 더 향상시켰다.
딥러닝에서 Cold-start란, 모델이 처음 학습할 때 충분한 학습 데이터가 없어서 성능이 불안정하거나 낮은 상태를 말한다.
- 다음 섹션에서는 아래와 같은 내용을 제시한다.
- SFT 없이 Base 모델에 강화 학습을 적용한 DeepSeek-R1-Zero
- Chain-of-Thought(CoT) 를 도입한 DeepSeek-R1
- DeepSeek-R1으로부터 증류된 작은 모델들
2.2. DeepSeek-R1-Zero : Reinforcement Learning on the Base Model
- 이 섹션에서는 LLM이 Supervised data 없이 추론 능력을 향상시킬 수 있는, 강화 학습 프로세스를 제시한다.
2.2.1. Reinforcement Learning Algorithm
- 강화 학습의 비용 절감을 위해, GRPO(Group Relative Policy Optimization)을 사용한다.
- GRPO는 본 논문 저자들의 선행 연구로, 강화 학습 시 Critic(비평가) model을 사용하지 않고 출력 간 상대적인 평가를 사용하는 것이다.
Actor-Critic : Actor(정책 모델)은 현재 상황에서 최적의 행동(출력)을 생성하고, Critic(비평가 모델)은 Actor의 행동이 얼마나 좋은지 평가하면서 학습이 진행된다.
$$
\mathcal J_{GRPO}(\theta) = \mathbb E[q \sim P(Q), {o_i}^G_{i=1} \sim \pi_{\theta_{old}}(O|q)]
$$
- 위 식은 GRPO의 목적 함수를 기대값으로 정의한 것이다. 정책 모델($\pi_\theta$)는 위 목적함수를 최대화하게끔 학습된다.
- $q \sim P(Q)$ : 질문 분포($P(Q)$)에서 샘플링된 질문($q$)이다. 자연어 모델의 경우, 사용자의 입력인 셈이다.
- ${o_i }^G_{i=1} \sim \pi_{\theta_{old}}(O|q)$ : $\pi_{\theta_{old}}(O|q)$는 이전 정책($\pi_{\theta_{old}}$)에서, 특정 질문($q$)에 대해 생성할 수 있는 출력($O$)의 확률 분포이다. 이 때 ${o_i }^G_{i=1}$은, 이전 정책( $\pi_{\theta_{old}}$)에서 생성된 $G$개의 서로 다른 출력 그룹이다. 다시말해 입력 질문에 대해 모델이 출력한 응답이다.
- 예를 들어 질문($q$) 가 “What is the captial of France?” 라고 했을 때, 이전 정책에 의해 생성된 출력이 아래와 같다고 하자.
- $o_1$ = “Paris”
- $o_2$ = “The capital of France is Paris.”
- $o_3$ = “I think it’s Paris, but I’m not sure.”
- 이렇게 샘플링한 $G(=3)$개의 응답을 비교하여 상대적인 평가를 통해 학습하는 것이다.
- 그렇다면 상대적인 평가는 어떻게 이뤄질까? 그 답은 아래와 같다.
$$
\frac{1}{G} \sum ^G_{i=1}(\min( \frac{\pi_\theta(o_i|q)}{\pi_{\theta_{old}} (o_i|q)} A_i, \mathrm {clip}(\frac{\pi_\theta(o_i|q)}{\pi_{\theta_{old}} (o_i|q)}, 1-\epsilon, 1+\epsilon) A_i) - \beta D_{KL}(\pi_\theta || \pi_{ref}))
$$
- 위에서 정의한 기대값을 풀어서 쓰면, 위 식과 같다. 이 때 각 항의 의미를 살펴보자.
- $r_i = \frac{\pi_\theta(o_i|q)}{\pi_{\theta_{old}}(o_i|q)}$ : 정책 비율을 의미한다. 1보다 큰 경우 현재 정책이 이전 정책보다 더 사용된다는 것이고, 1보다 작은 경우 이전 정책이 현재 정책보다 더 사용된다는 것이다. 이를 최대화 함으로써 현재 정책을 사용하게끔, 즉 정책이 좋은쪽으로 학습되게 한다.
- $A_i = \frac{r_i - mean({r_1, r_2, \cdots, r_G})}{std({r_1, r_2, \cdots, r_G })}$ : Advantage function이다. 출력 $o_i$ 가 현재 그룹 내에서 상대적으로 얼마나 좋은지를 측정하는 값이다. $r_i$ 를 정규화한 값으로 나타낸다.
- $\mathrm {clip}(r_i,1-\epsilon, 1 + \epsilon)$ : 클리핑을 적용하여 값이 지나치게 커지는 것을 방지한다.
- $\min(r_i A_i ,; \mathrm{clip}(r_i, 1-\epsilon, 1+\epsilon)A_i)$ : 클리핑된 버전과 원래 비율을 비교하여 더 작은 값을 선택한다. 이는 불필요한 큰 업데이트를 방지하는 역할을 한다.
- $\beta D_{KL}(\pi_\theta || \pi_{ref})$ : 규제항으로, 새로 업데이트된 정책이 기준 정책(Reference policy)과 너무 멀어지지 않도록 규제한다.
2.2.2. Reward Modeling
- DeepSeek-R1-Zero의 훈련을 위해, 두 가지 유형의 보상함수를 사용한다.
- Accuracy rewards : 응답이 올바른지 평가한다. 예를 들어 수학 문제나, 코딩 문제의 경우 미리 정의된 정답이나 테스트 케이스를 기반으로 평가한다.
- Format rewards : 모델의 Thinking process를 ‘’ 와 ‘’ 태그 사이에 넣도록 강제하는 형식 보상을 사용한다.
2.2.3. Training Template
- DeepSeek-R1-Zero의 훈련을 위해, 먼저 Base 모델이 따르는 간단한 템플릿을 설계한다.

- 사용자의 질문에 대해, 추론 과정을 <think> 태그 안에, 답을 <answer> 태그 안에 넣은 형태로 답변하라는 것이다.
2.2.4. Performance, Self-evolution Process and Aha Moment of DeepSeek-R1-Zero
Performance of DeepSeek-R1-Zero

- 위 그래프를 보면 DeepSeek-R1-Zero(실선)의 성능이 학습이 진행됨에 따라 o1-0912(점선)와 비슷한 수준에 도달했다.
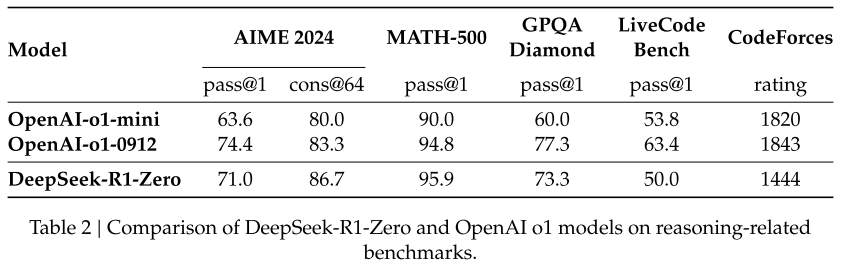
- 다양한 추론 관련 벤치마크에서 DeepSeek-R1-Zero와 OpenAI-o1-0912 모델 간의 비교 분석 테이블이다.
- 위 결과는 Supervised fine-tuning 없이 강화 학습만으로도 o1에 준하는 추론 능력을 갖출 수 있다는 것을 시사한다.
- 즉 강화 학습만으로도 효과적으로 학습하고 일반화할 수 있다는 것이다.
Self-evolution Process of DeepSeek-R1-Zero

- 위 그래프는 학습이 진행됨에 따른 DeepSeek-R1-Zero의 평균 응답 길이가 증가하는 것을 나타낸 것이다.
평균 응답 길이가 길어진다는 것은, 모델이 정답까지 도달하는 과정이 길어짐으로써 더욱 논리적인 추론이 가능해진다는 것을 말한다.
- 이는 외부적인 조정의 결과가 아니라, 모델 내에서 자연스럽게 일어나는 발전이다. (강화학습)
- 이 논문에서는 응답이 길어짐에따라 나타나는 변화를 자발적인 발전, 모델이 이전 단계를 다시 살펴보고 재평가하는 Reflection(반성)이라고 말한다.
Aha Moment of DeepSeek-R1-Zero
- 논문의 저자들은 DeepSeek-R1-Zero 학습 도중, 아하 하는 순간이 발생한다고 말한다.
- 이는, 모델에게 정답을 명시적으로 가르치는 대신(Supervised), 적절한 인센티브(보상)만 제공하면서 자율적으로 학습해가는 방식의 잠재력을 보여준다고 말한다.

- 위 그림에서 처럼, 수학 문제에 대한 질문을 했는데, 태그 안에서, 모델이 Aha moment(빨간색 글씨)라며, 문제에 대한 접근을 다른 방식으로 다시 시도하게 된다.
- 이처럼 Superversied learning이 아닌 강화 학습으로 모델의 자발적인 발전이 가능하게 한 것이다.
Drawback of DeepSeek-R1-Zero
- 하지만 DeepSeek-R1-Zero는 몇 가지 문제가 있다.
- 출력의 가독성이 떨어지고, 언어 혼합 문제와 같은 어려움이 있다.
- 이를 해결하기 위해 인간 친화적인(Human-friendly) Cold-start data를 활용한다.
2.3. DeepSeek-R1 : Reinforcement Learning with Cold Start
- DeepSeek-R1-Zero의 추론 결과는 자연스럽게 아래와 같은 질문으로 귀결된다.
1. 소량의 고품질 데이터를 Cold start로 사용하여 성능을 향상시키고 수렴을 가속화 할 수 있을까?(수렴을 가속화한다는 것은, 고점까지 도달하는 시간을 단축한다는 의미임.)
2. 명확한 사고 과정(CoT, )을 생성하면서도 사용자 친화적인(User-friendly) 모델을 어떻게 훈련시킬 수 있을까?
- 위 질문들을 해결하기 위해 DeepSeek-R1을 훈련시키는 파이프라인을 설계하였다. 이 파이프라인은 네 가지 단계(2.3.1 ~ 2.3.4)로 구성된다.
2.3.1. Cold start
- DeepSeek-R1은 DeepSeek-R1-Zero와 달리, 훈련 초기의 불안정한 상태를 방지하기 위해 Actor 모델을 소량의 CoT data로 파인튜닝한다.
- 결과적으로 DeepSeek-V3-Base를 파인튜닝하는 수천 개의 Cold-start data를 수집했고, 이 데이터의 장점은 두 가지이다.
- Readability(가독성) : DeepSeek-R1-Zero의 문제였던 가독성을 해결하기 위해 Cold-start 데이터를 수집할 때, 출력 형식을 |special_token||special_token| 로 지정하여 응답 끝에 읽기 쉬운 요약을 추가한다.
- Potential(잠재력) : 인간의 사전지식(휴리스틱)이 들어간 데이터 설계를 통해 DeepSeek-R1-Zero 보다 더 나은 성능을 관찰할 수 있었다.
2.3.2. Reasoning-oriented Reinforcement Learning
- DeepSeek-V3-Base를 콜드 스타트 데이터로 파인튜닝한 후 DeepSeek-R1-Zero과 동일한 강화학습을 거친다.
- 하지만 훈련 과정에서, 프롬프트에 언어가 여러개 포함된 경우 여전히 언어 혼합이 발생하는 것을 확인했다.
- 따라서 이 문제를 완화하기 위해, Langague consistency에 대한 보상을 추가한다. 이 Alignment 과정으로 인해 성능이 약간 떨어지지만, 사람이 더 읽기 쉽게 만들어준다.
2.3.3. Rejection Sampling and Supervised Fine-Tuning
- 이 단계는 Cold-start 학습을 거쳐 강화학습까지 마친 DeepSeek-R1 모델을 사용하여 SFT 데이터를 수집하는 단계이다.
- 콜드 스타트 데이터는 추론 능력 향상에 집중하는 반면, 이 단계 수집되는 데이터는 모델의 글쓰기 및 일반적인 작업에서의 능력을 향상시키는 것을 목표로 한다.
- SFT 데이터는 추론 데이터 60만개, 비추론 데이터 20만개로 구성된다.
- 추론 데이터는 DeepSeek-R1 을 통한 Rejection Sampling(거부 샘플링)을 통해 추출되고, 비추론 데이터는 DeepSeek-V3의 SFT 데이터를 재활용한다.
거부 샘플링이란 모델이 강화학습 단계에서 생성한 여러 응답 중, 올바른 응답만 선택하여 사용한다는 것이다.
2.3.4. Reinforcement Learning for all Scenarios
- 모델의 유용성(Helpfulness)과 무해성(Harmlessness)을 향상시키는 것을 목표로 하는 2차 강화학습 단계이다.
- 유용성을 높이기 위해의 응답이 사용자에게 얼마나 유용한지 평가한다.
- 무해성의 경우, 와를 모두 포함한 모델의 전체 응답을 평가한다.
2.4. Distillation: Empower Small Models with Reasoning Capability
- DeepSeek-R1의 추론 능력을 작은 모델에 학습시키기 위해 Qwen과 Llama 등 오픈 소스 모델을 2.3.3. 절에서 수집한 80만개의 SFT 데이터로 파인 튜닝한다.
- Distillation을 위해 사용한 모델은 Qwen2.5-Math-1.5B, Qwen2.5-Math-7B, Qwen2.5-14B, Qwen2.5-32B, Llama-3.1-8B, Llama-3.3-70B-Instruct 총 6개이다.
3. Experiment
- 평가를 위해 pass@k를 사용한다.
$$
\mathrm{pass}@1 = \frac{1}{k}\sum^k_{i=1}p_i
$$
- $p_i$ 는 i번째 응답의 정확성을 나타낸 것이고, pass@1은 모델의 첫번째 응답이 정답인 경우를 의미한다.

- DeepSeek-R1은 Education-oriented knowledge(교육 지향 지식, MMLU, MMLU-Pro, GPQA Diamond) 벤치마크와 Factual(사실 기반, SimpleQA) 벤치마크에서 DeepSeek-V3를 능가했지만 OpenAI-o1-1217에 비해 뒤쳐지는 걸 확인할 수 있다.
- Code 부분에서는 DeepSeek-R1과 OpenAI-o1-1217이 복합적이고
- Math 부분에서는 DeepSeek-R1이 살짝 앞서는 것을 확인할 수 있다.

- Distillation 모델에 대한 평가이다.
- 참고로 파라미터 개수는 다음과 같다.
OpenAI-o1-mini : ~100B(추정)GPT-4 : 1.76T(1조 7천6백억 개)
DeepSeek-R1 : 671B(6710억 개)
GPT-4o : 12B
o1의 파라미터 개수는 내가 알고있는 한 공개되어있지 않은데, GPT-4 보다는 클 것으로 예상된다.
- DeepSeek-R1 모델의 크기는 GPT-4의 3분의 1정도이다.
- 가장 작은 Distillation 모델인 Distill-Qwen-1.5B 모델은 12B개의 파라미터를 가진 GPT-4o에 비해 성능이 약 20% 정도 높다.

- 위 테이블에서 DeepSeek-R1-Zero의 Distillation 모델인 Zero-Qwen-32B의 벤치마크가 나와있는데, R1의 Distillation 모델에 비해 많이 떨어지는 것을 확인할 수 있다.
Conclusion
- DeepSeek-R1-Zero. Cold-start 데이터 없이 강화 학습만을 사용하여 좋은 성능을 보여준다.
- DeepSeek-R1. Cold-start 데이터와 강화학습을 통해 OpenAI-o1-1217과 비슷한 성능을 보여준다.
- Distillation을 통해 작은 모델로도 비슷한 크기의 다른 LLM을 능가했다.
- 앞으로는 Language mixing 문제 해결, 프롬프트 엔지니어링 등에 대해 연구한다고 한다.
Review
- DeepSeek-R1은 현재 대세이면서도 비슷한 수준인 o1에 비해 모델의 크기가 작고(정확한 수치는 모르나 1/3 ~ 1/5 정도로 추측) 오픈 소스로 공개돼서 때문에 화제가 된 모델이다.
- 이미 코드, 가중치등 모두 공유가 되어있기 때문에 이 모델을 사용한 여러가지 후속 연구가 진행되고 있을 것으로 예상한다.
- OpenAI의 데이터셋을 가져와서 썼을 것이라는 논란도 있다.
- 통상적으로 강화 학습이 지도 학습보다 모델의 성능을 높이는데 어렵다고 알려져있기 때문에 데이터셋에 대한 의심과 논란이 생긴 것 같다.
- 허깅페이스에 모델의 코드와 가중치가 공개돼있고 Ollma를 통해 DeepSeek-R1을 포함한 Distillation 모델을 로컬에서 돌려볼 수 있으니 참고하길 바란다.
Ollama
Get up and running with large language models.
ollama.com
deepseek-ai/DeepSeek-R1 at main
huggingface.co



