
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- 1차 미분 마스크
- blip-2
- clip
- google summer of code
- 객체 검출
- gsoc
- res paper
- 논문 리뷰
- Object detection article
- clip adapter
- grefcoco
- transfuser++
- gsoc 2025
- grefcoco dataset
- 엔트로피란
- gsoc 후기
- 딥러닝 목적함수
- res
- vlm
- 딥러닝 엔트로피
- E2E 자율주행
- mobilenetv1
- referring expression segmentation
- 이미지 필터링
- gres
- 논문 요약
- TransFuser
- object detection
- 에지 검출
- 원격 학습 안끊기게
Archives
- Today
- Total
My Vision, Computer Vision
부분 End-to-End 자율주행 아키텍쳐, TransFuser 본문
TransFuser: Imitation with Transformer-Based Sensor Fusion for Autonomous Driving
How should we integrate representations from complementary sensors for autonomous driving? Geometry-based fusion has shown promise for perception (e.g. object detection, motion forecasting). However, in the context of end-to-end driving, we find that imita
arxiv.org
이 논문이 나오게 된 배경
- 본 논문은 2022년 5월에 아카이브에 업로드되었다. 참고로 UniAD는 2022년 12월에 업로드되었다.
- 논문의 저자들은 E2E에서 센서 퓨전에 기반한 모방학습이 과소평가되어 있다고 주장하면서 셀프 어텐션 매커니즘을 적용한 카메라-라이다 센서 퓨전 모델 TransFuser을 제안한다.
- TransFuser 모델은 이후 TransFuser++(2023, 6), TransFuser++ V6(2025, 12) 등으로 연구되므로, 중요한 기반 논문이라 생각된다.
- CARLA 시뮬레이터에서 자주 언급되는 PDM-Lite와 TransFuser, TransFuser++ 등 모두 독일 튀빙겐 대학교의 Autonomous Vision Group 연구실에서 제안한 방법들이고, 저자들도 겹친다. PDM-Lite의 코드와 레포트는 깃허브 DriveLM 리포에, TransFuser/++은 carla_garage 리포에 업로드 되어있다.
TransFuser 모델 특징

- 본 논문에서는 카메라, 라이다에서 추출된 두가지 모달리티 정보를 융합하는 방식을 제안한다.
- 지금에서야 이 모델을 봤을 때 네트워크 구조에서의 특별한 점은 없어 보인다. 이미지와 라이다로부터 두 가지의 입력을 각각의 브랜치에서 처리하는데, 각 스테이지에서 출력된 두 피쳐를 융합하여 셀프 어텐션으로 융합하는 과정을 거친다.
- 총 4개 스테이지에서 융합된 피쳐가 만들어지고, Average pooling으로 차원을 동일하게 투영시킨 후 하나의 벡터로 합친다. 최종적으로 이 벡터는 궤도를 예측하는 데 사용된다.
모델의 예측(출력) 형태
- TransFuser는 Control signal까지 출력하는 완전 E2E 모델이 아닌, Waypoint 형식의 궤적(Trajectory)만 출력하는 부분 E2E 모델이다.
- 위 네트워크 구조에서 최종 출력 형태를 보면 현재 Ego의 위치(0, 0)을 기준으로 GRU를 사용하여 미래 4번째 스텝까지의 Waypoint 좌표 예측을 수행한다.
- 이 궤적 예측 학습은 모방 학습(Imitation Learning)의 방식을 사용한다. 즉 타겟 모델이 전문가(Expert) 역할을 하는 모델을 흉내내게끔 학습하는 방식이다.

- 간단하게 위 수식으로 표현하는데, $\pi(\mathcal X)$는 타겟 모델의 출력을, $\mathcal W$는 전문가 모델이 출력한 Waypoint를 의미한다. 이 두 값 사이 L1 로스를 계산하여 타겟 모델이 전문가의 출력을 모방하도록 학습하는 것이 모방 학습이다.
멀티태스크 학습 방식
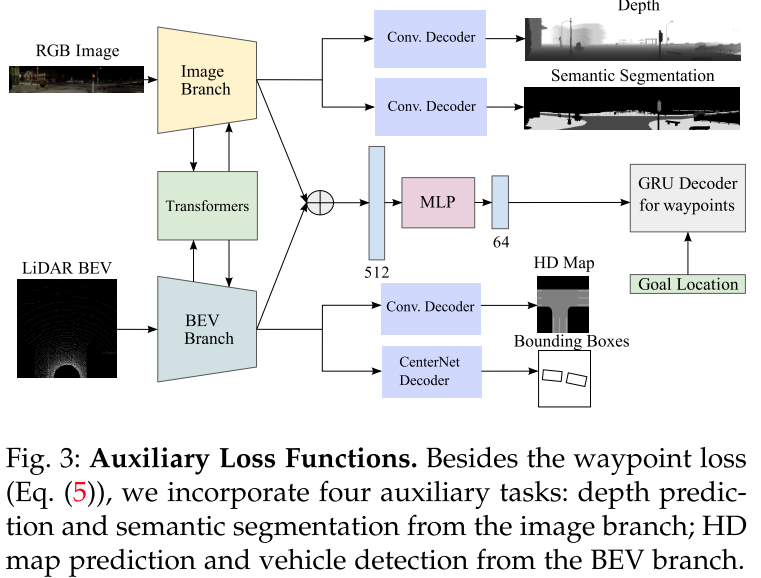
- TransFuser의 학습에는 Waypoint 좌표 예측 뿐만 아니라 Auxiliary Tasks(보조 과제) 학습도 이루어진다. Inference 과정에서는 수행되지 않고, 학습 때만 쓰이는 보조 모듈이다.
- 이미지 브랜치에서 출력된 피쳐로는 깊이 추정, 세그멘테이션 학습을 수행하고 라이다 브랜치에서 출력된 BEV 피쳐로는 HD Map을 GT로 사용한 세그멘테이션과 다른 차량의 센터 포인트를 예측하는 학습을 수행한다. 멀티태스크 학습이라고 볼 수 있겠다.
그 외 특징
- TransFuser 모델은 Waypoint 예측까지만 수행하고 뒤에 2개의 PID 모듈(횡방향, 종방향)을 붙여 조항, 감속 정보를 출력하는 파이프라인이다.
- 자율주행 모방학습에서 관찰되는 관성 문제(Inertia problem, 차량이 계속 정지 상황에 빠지게 되는 문제)를 해결하기 위해 크리핑 방식을 사용한다. 크리핑 방식이란, 차량이 일정 시간동안 계속 정지해있으면 느린 속도로 전진 시키는 방법으로, 관성 문제를 탈출할 수 있게 해준다. 하지만 바로 앞에 차량이 있는 경우 충돌이 발생할 수 있기 때문에, 이를 막기 위한 Safety Heuristic 방식도 도입하였다.
- 이미지만을 입력으로 사용한 버전인 Latent TransFuser 모델도 제안한다. 그럼 라이다 브랜치의 입력이 사라지게 되는데, 이 부분을 Positional Encoding 으로 채운다. 원래 256 * 256 * 2 크기의 라이다 입력을 동일한 크기의 학습 가능한 Positional Encoder 으로 대체하는 것.
728x90
'Paper' 카테고리의 다른 글
'Paper' Related Articles
more

