
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
Tags
- 딥러닝 엔트로피
- Object detection article
- gres
- 이미지 필터링
- gsoc 2025
- 에지 검출
- 원격 학습 안끊기게
- gsoc
- res
- clip
- google summer of code
- 논문 리뷰
- 엔트로피란
- 논문 요약
- mobilenetv1
- vlm
- 객체 검출
- grefcoco dataset
- object detection
- transfuser++
- clip adapter
- gsoc 후기
- E2E 자율주행
- referring expression segmentation
- 딥러닝 목적함수
- 1차 미분 마스크
- grefcoco
- blip-2
- TransFuser
- res paper
Archives
- Today
- Total
My Vision, Computer Vision
[논문 요약/리뷰] CRIS: CLIP-Driven Referring Image Segmentation 본문
Overview
- 본 논문에서는 CLIP 모델을 REF(Referring Expression Segmentation) Task에 사용한다.
- 동시에 Vision-Language Decoder 및 Text-to-pixel 대조 학습을 제안한다.
Problem Statement

- (당시) Multi-modal 분야에서 CLIP 모델이 성공적인 결과를 보여준 바 있다. 따라서 본 논문에서는 CLIP을 RES에 도입한다.
- 하지만 위 사진에서처럼, CLIP을 Naive하게 사용하는 방법으로는 최적의 성능을 내지 못하는데, 이유는 Pixel-level 예측 태스크인 RES와 다르게, CLIP은 Image-level(Contrastive)로 훈련되었기 때문이다.
- 따라서 시각적 특징을 세부적으로 학습해야하는 목표와 맞지 않게, CLIP 모델은 전역적인 정보 위주로 이미지를 표현한다.
- 본 논문에서는 CLIP의 사전 지식(Prior knowledge)을 잘 활용할 수 있는 방법에 대해 탐구한다.
Contributions
- CLIP 모델의 전이 학습 프레임워크, CLIP-Driven Referring Image Segmentation(CRIS)를 제안한다.
- Multi-modal Knowledge를 완전히 활용할 수 있는 두 가지 디자인을 소개한다.
- Vision-language decoder
- Text-to-pixel contrastive learning
- 기존 방식들과 비교하여, 큰 차이로 State-of-the-art 성능을 달성한다.
Methodology

- Image, Text Feature를 추출하기 위해 Encoder로 각각 ResNet, Transformer를 사용한다.
- Encoder에서 추출된 피쳐는 Vision-Langauge Decoder에 입력되어 Pixel-level의 특징으로 만들어진다.
- 마지막으로 두 개의 프로젝터(Text Projector, Image projector)로부터 만들어진 특징으로 Contrastive learning을 수행한다.
Image & Text Feature Extraction
Image Encoder
- ResNet의 2~4번째 스테이지에서 출력된 피쳐($F_{v2}, F_{v3}, F_{v4}$)를 사용한다.
Text Encoder
- 시퀀스가 $L$인 입력 텍스트는 트랜스포머로부터 텍스트 피쳐 $F_t \in \mathbb R^{L\times C}$로 만들어진다.
- 이 때, $[EOS]$ 토큰은 $F_s\in \mathbb R^{C'}$로 매핑되어 전역 특징(Global Representation)으로 사용된다.
Cross-modal Neck
- Cross-model Neck은 텍스트 정보와 이미지 정보를 융합하는 역할을 한다.
- 먼저 $[EOS]$ 토큰으로부터 만들어진 $F_{s}$와 이미지 피쳐 $F_{v4}$를 융합하여 멀티모달 피쳐 $F_{m4}$를 만들어낸다.
$$
F_{m4} = Up(\sigma (F_{v4}, W_{v4}) \cdot \sigma (F_s W_s))
$$
- 이어서 $F_{v3}, F_{v2}$ 도 차례대로 동일한 연산을 적용하여 $F_{m3}, F_{m2}$를 만들어낸다. 이 때, 피쳐맵의 크기를 맞춰주기 위해 Upsample과 Average pooling을 사용한다.
- 이렇게 만들어진 $F_{m2}, F_{m3}, F_{m4}$를 concatenation한 후 컨볼루션 레이어를 하나 거쳐 멀티모달 피쳐 $F_m$가 되고, Coordiate feature $F_{coord}$까지 더해져 최종적인 Visual Feature $F_v$가 만들어진다.
Vision-Language Decoder
- 트랜스포머 디코더처럼, Self-Attention과 Cross-Attention 모듈로 구성된다.
- 먼저 Visual feature $F_v$가 Self-Attention 모듈에 입력되고, Self-Attention의 출력과 $F_t$가 Cross-Attention 모듈에 입력된다.
- FFN 까지 거쳐 더 융합된 Multi-model Feature $F_c$ 가 출력된다.
Text-To-Pixel Contrastive Learning
- 대조 학습(Contrastive Learning)에 사용할 피쳐를 만들기 위해, 위 과정에서 만들어진 $F_c$와 $F_s$를 사용한다.
$$
z_v = F'_cW_v + b_v,; F'_c = Up(F_c) \ z_t = F_s W_t + b_t
$$
- $z_v$는 이미지를 대표하는 피쳐 벡터, $z_t$는 텍스트를 대표하는 피쳐 벡터이다.
- 이 때, $z_t$를 기준으로, 매칭되는 이미지 피쳐 벡터를 Positive($\mathcal C$), 매칭되지 않는 피쳐 벡터를 Negative($\mathcal N$)로 정의한다.
- Positive 쌍 끼리는 피쳐가 서로 가까워지게, Negative 쌍과는 피쳐들이 멀어지게 학습한다.
$$
L^i_{con}(z_t, z^i_v) = \begin{cases} - \log \sigma(z_t \cdot z^i_v), ;;; i \in \mathcal P \ -\log (1-\sigma(z_t \cdot z^i_v)), ; i \in \mathcal N\end{cases}
$$
- 최종적인 Loss는 모든 샘플간 Loss의 합으로 계산된다.
Experimental Results
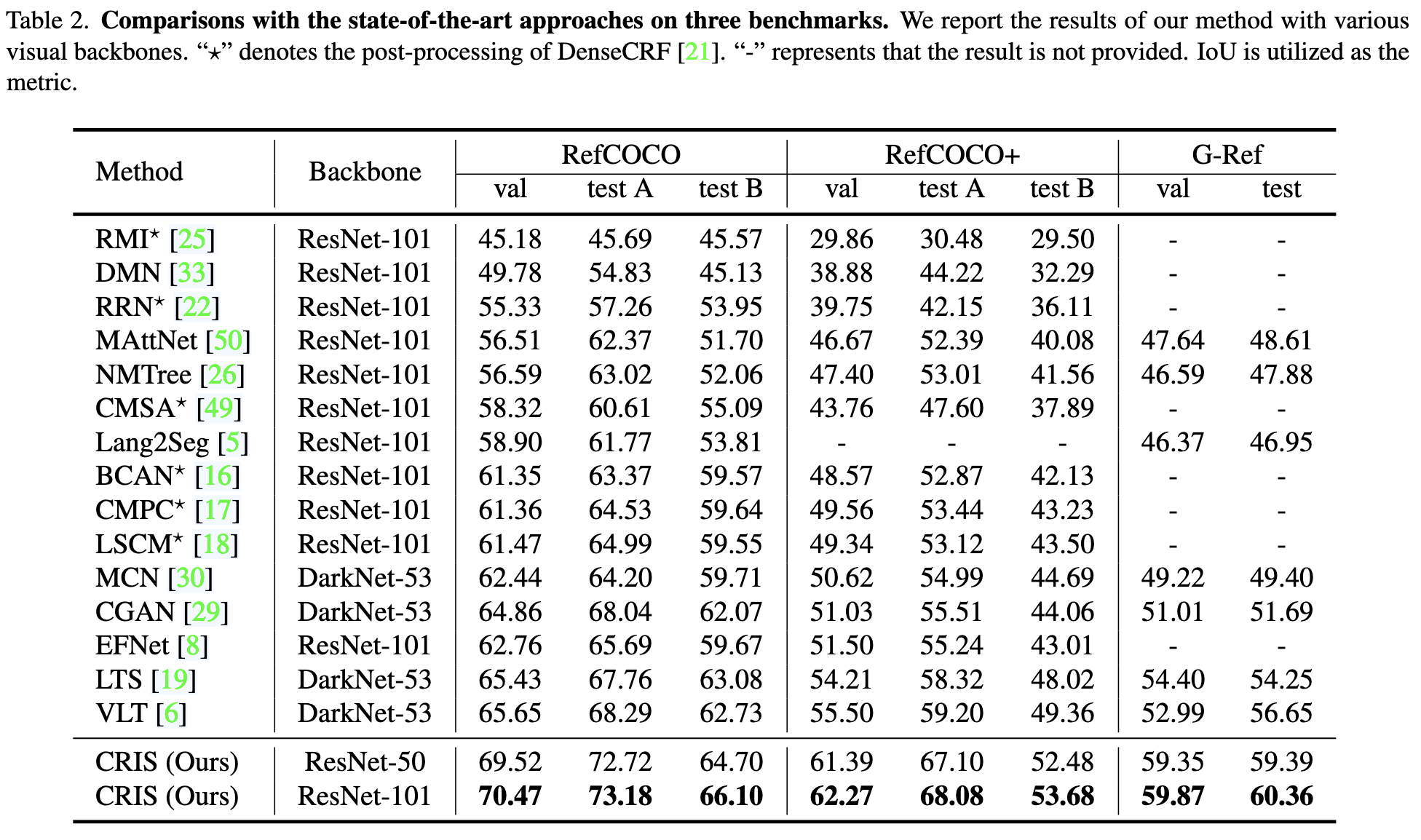
- RES 벤치마크인 RefCOCO, RefCOCO+, G-Ref 세 데이터셋에 대해 모두 최고 성능을 달성하였다.
728x90
'Paper' 카테고리의 다른 글
'Paper' Related Articles
more

