
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- gsoc 후기
- 엔트로피란
- grefcoco dataset
- 이미지 필터링
- google summer of code
- mobilenetv1
- gres
- 기계학습
- object detection
- 원격 학습 안끊기게
- clip adapter
- 에지 검출
- gsoc 2025
- vlm
- 딥러닝 엔트로피
- gsoc가 뭔가요
- Object detection article
- res paper
- 딥러닝 목적함수
- gsoc
- 1차 미분 마스크
- clip
- 객체 검출
- 논문 리뷰
- res
- gsoc 지원
- blip-2
- grefcoco
- referring expression segmentation
- 논문 요약
Archives
- Today
- Total
My Vision, Computer Vision
[논문 리뷰/요약] LLaVA : Visual Instruction Tuning 본문
Visual Instruction Tuning
Instruction tuning large language models (LLMs) using machine-generated instruction-following data has improved zero-shot capabilities on new tasks, but the idea is less explored in the multimodal field. In this paper, we present the first attempt to use l
arxiv.org
Abstract
- Language-only GPT-4를 사용하여 Language-image instruction-following data를 생성하는 첫번째 시도.
- LLaVA(Large Language and Vision Assistant)를 소개한다.
Problem
- Computer vision은 Classification, Detection, Segmentation, Captioning 등으로 나뉘는데, 이 분야들은 하나의 모델로 수행되지 않고 큰 용량의 Vision model에 의해 따로따로 해결된다. 이는 모델로 하여금 태스크에 고정된 인터페이스를 갖게하여 상호작용성(Interactivity)과 적응성(Adaptability)을 제한한다.
- 기존 LLM(Large Language Model) 연구에서 Machine-generated high-quality instruction-following data(기계 생성 고품질 지시-이행 데이터)로 LLM의 성능이 향상되었지만, 이는 모두 텍스트 기반이다.
- LLM에 이미지를 입력으로 넣는 시도는 있었으나 Visual instruction-tuning이 명시적으로 수행되진 않았다.
Contributions
1. Multimodal instruction-following data
- 핵심 문제는 Vision-language instruction-following data가 부족하다는 것이다.
- 저자들은 ChatGPT/GPT-4를 사용하여 기존의 Image-text pair 데이터를 적절한 형태의 Instruction-following 포맷으로 바꾸는 파이프라인을 제안한다.
2. Large Multimodal models
- 저자들은 CLIP의 시각 인코더와 Vicuna의 언어 디코더를 연결하여, 만들어진 Instructional vision-language data를 End-to-end로 학습한다.
3. Multimodal instruction-following benchmark
- 두 개의 벤치마크 데이터셋을 소개한다.
- 각 데이터셋은 디테일하게 어노테이션된 Image-instruction pair로 구성된다.
4. Oepn-sourcce
- 생성된 Multimodal instruction data, 코드, 체크포인트, 데모를 오픈 소스로 공개한다.
Method
Data generation
- Language only GPT-4를 활용하여 Image-text pair 데이터로부터 Multimodal instruction-following 데이터를 만들어낸다.
- 입력 이미지 $X_\mathbf v$ 와 캡션 $X_c$ 로부터 만들어진 질문을 $X_q$ 라고 할 때, 아래와 같은 형태의 데이터가 생성된다.
- $X_\mathbf v$ $X_q$ Assistant : $X_c$
- 이미지와 질문을 입력으로 받고, 캡션과 관련된 답변을 하게끔 모델을 학습할 수 있는 것이다.
- GPT-4만 사용하면 데이터의 다양성이 낮을 것이기 때문에, ChatGPT도 사용하여 데이터를 생성한다.
- 텍스트 만을 사용하여 이미지에 관련된 Instruction-following 데이터를 생성해야하기 때문에, 이미지를 텍스트 형식으로 표현해야 하는데, 이 논문에서는 캡션과 바운딩 박스를 사용한다.

- 이런식으로 실제로는 오른쪽에 있는 이미지를 사용하지 않고, 캡션과 바운딩 박스를 이용하여 GPT가 이미지를 보고있는 것 처럼 In-context-learning을 하는 것이다.
- 이렇게해서 생성된 데이터는 아래와 같다.

- 총 세 가지 타입(Conversation, Detailed description, Complex reasoning)의 응답 데이터가 만들어진다.
- Data generation에 사용된 프롬프트는 아래와 같다.
messages = [ {"role":"system", "content": f"""You are an AI visual assistant, and you are
seeing a single image. What you see are provided with five sentences, describing the same image you
are looking at. Answer all questions as you are seeing the image.
Design a conversation between you and a person asking about this photo. The answers should be in a
tone that a visual AI assistant is seeing the image and answering the question. Ask diverse questions
and give corresponding answers.
Include questions asking about the visual content of the image, including the object types, counting
the objects, object actions, object locations, relative positions between objects, etc. Only include
questions that have definite answers:
(1) one can see the content in the image that the question asks about and can answer confidently;
(2) one can determine confidently from the image that it is not in the image. Do not ask any question
that cannot be answered confidently.
Also include complex questions that are relevant to the content in the image, for example, asking
about background knowledge of the objects in the image, asking to discuss about events happening in
the image, etc. Again, do not ask about uncertain details. Provide detailed answers when answering
complex questions. For example, give detailed examples or reasoning steps to make the content more
convincing and well-organized. You can include multiple paragraphs if necessary."""}
]
for sample in fewshot_samples:
messages.append({"role":"user", "content":sample[‘context’]})
messages.append({"role":"assistant", "content":sample[‘response’]} )
messages.append({"role":"user", "content":‘\n’.join(query)})- LLM에게 실제로 이미지를 보고 대화를 하는 것처럼, 질문-답변 쌍을 만들어 달라고 하는 프롬프트이다.
- 확실하게 대답할 수 있는 질문만 만들 수 있게끔 Object type, Counting the objects, Object actions, Relative positions between objects를 포함시키라는 부분을 확인할 수 있다.
- Fewshot_samples에는 사람이 만든 어노테이션된 예시 샘플이 들어있는데, LLM이 이를 Seed example(초기 참고 예제)로 사용한다.

- 위 이미지는 실제로 생성된 예시 데이터인데, 세 가지 타입으로 구분해서 출력하진 않고, 간단한 대화 형식과 복잡한 대화 1개 정도로 구성되는 듯 하다.
- 이렇게 총 158K개의 샘플을 만드는데, 58K(Conversations), 23K(Detailed description), 77K(Complex reasoning)으로 구성된다.
- 실험 과정에서 GPT-4에서 만들어진 데이터가 품질이 더 좋다는 것을 알게됐다고 한다.
Visual Instruction Tuning
Architecture
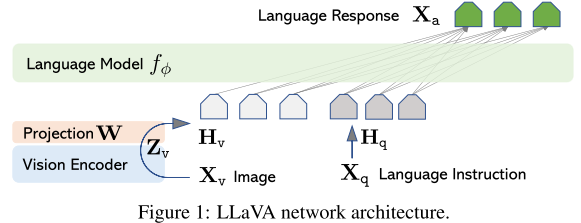
- 위 그림은 LLaVA의 아키텍쳐를 나타낸 것이다.
- Vision Encoder는 CLIP의 ViT-L/14를 사용하고 Language Model은 Vicuna를 사용한다.
- Vision Encoder는 입력 이미지 $X_\mathbf v$ 를 피쳐 $\mathbf Z_\mathbf v$ 로 변환하고, 간단한 선형 레이어 $\mathbf W$ 를 통해 텍스트 임베딩과 같은 차원을 가진 $\mathbf H_\mathbf v$ 로 만든다.
$$
\mathbf H_\mathbf v= \mathbf W \cdot \mathbf Z_\mathbf v, \mathrm {with} ;\mathbf Z_\mathbf v=g(\mathbf X_\mathbf v)
$$
- 식으로 나타내면 위와 같다.
Training
- 학습 과정에서, 입력 이미지 $X_\mathbf v$ 에 대해 Multi-turn conversation(다중턴 대화) 데이터 $(X^1_q, X^1_a, \cdots, X^T_q, X^T_a)$ 가 제공된다. 이 때 $T$ 는 턴의 개수(대화 반복 횟수)이다.
- $X_q$ 는 사용자(User)의 입력, $X_a$ 는 Assistant의 답변이 되는 셈이다.

- t=1 일 때, 질문 $X^1_q$ 와 이미지 $X_\mathbf v$ 가 같이 입력되는데, 랜덤하게 순서를 바꿔서 입력한다.
- 그 후부터는 질문만 입력으로 넣어 LLM을 학습한다.

- 따라서 위와 같은 형태로 데이터가 입력되는데, 초록색으로 표시된 텍스트만 로스 계산에 사용한다.
- 이런식으로 Assistant 모델이 대답을 예측하고, 어디에서 멈출지 학습하게 되는 것이다.
Stage 1: Pre-training for Feature Alignment
- 학습은 두 단계로 나누어서 진행하는데, 첫번째 스테이지는 Visual tokenizer를 훈련하는 과정으로 볼 수 있다.
- 위에서 입력 이미지를 Vision encoder를 통해 피쳐로 만든 후 간단한 선형 레이어를 통해 임베딩 토큰 $H_\mathbf v$ 로 만들어준다고 설명했는데, 이 때 사용되는 간단한 선형 레이어 $\mathbf W$ 를 Visual tokenizer로 볼 수 있는 것이다.
- 따라서 이 Visual tokenizer만 훈련시키기 위해 Language model과 Visual encoder의 가중치는 고정한다.
- 이 때 사용되는 데이터셋은 CC3M으로부터 필터링된 595K 개의 Image-Text pair 데이터를 Generation 과정을 통해 Instruction-following 데이터로 변환하여 1에포크 동안 학습한다.
Stage2 : Fine-tuning End-to-End
- Stage1에서 만들어진 Visual tokenizer를 가지고 End-to-end 파인튜닝을 시작한다.
- 이 과정에서는 Visual encoder의 가중치만 고정한 채로 Language model인 Vicuna를 훈련시키고 Visual tokenizer도 마찬가지로 학습된다.
- Data Generation에서 만들어진 158K 개의 Instruction-following 데이터를 사용한다.
- 학습 중에 데이터의 세 가지 타입 중 하나를 랜덤하게 샘플링하여 3에포크 동안 학습한다.
Experiment

- LLaVA의 추론과 GPT-4, BLIP-2, OpenFlamingo의 추론을 비교한 것이다.
- 남자가 차 뒤에 매달려서 옷에 다림질하는 사진을 입력으로 넣고 무엇이 이상하냐고 질문을 했을 때 LLaVA와 GPT-4만 정답을 정확히 출력한다.
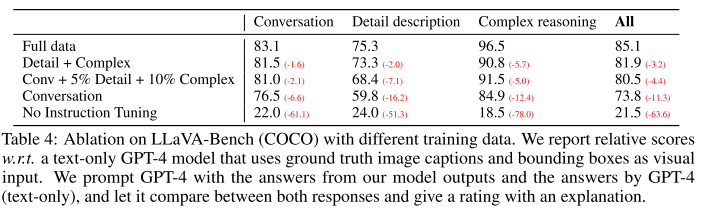
- 위 테이블은 COCO 데이터셋으로부터 30개의 이미지를 랜덤하게 샘플링한 후, 그 캡션으로부터 3 타입 총 90개의 Instruction-following 데이터를 만들어서 평가한 것이다.
- 여기에 사용된 Evaluation metric은, Language only GPT-4를 테스터로 사용하여 Assistant의 응답과 Ground-truth 가 얼마나 유사한지 1~10점으로 평가하게끔 한 것이다.
- Instruction Tuning이 없는 경우에 비해 성능이 크게 향상된 것을 확인할 수 있다.

- 위 테이블은 논문의 저자가 LLaVA의 취약점을 언급하며 제시한 사진이다.
- 라멘 이미지에서 레스토랑의 이름, 사진의 디테일한 설명을 요구하고 있는데, 레스토랑의 이름을 답하기 위해선 방대한 지식 범위를 갖추고 있어야 하며 이미지 안에 있는 반찬을 정확히 설명하려면 인터넷에서 정보를 검색하는 능력이 필요할 것이라고 주장한다.
- 또한 냉장고 사진에서는 요거트의 브랜드와 딸기맛 요거트가 있는지 물어보고있는데, 논문의 저자는 요거트의 브랜드를 모델이 아려면 고해상도 이미지를 처리할 수 있어야 한다고 말한다. 또한 냉장고에 딸기와 요거트가 있는데, 이를 딸기맛 요거트로 인식한다는 것이다.
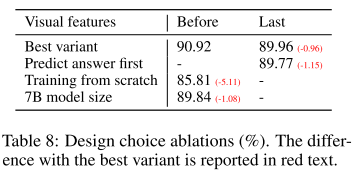
- 위 테이블은 여러가지 Ablation 실험을 진행한 것이다.
- 첫번째로, CLIP의 ViT에서 마지막 레이어의 이전(Before) 피쳐와 이후(Last) 피쳐 사용 실험인데, 이전 피쳐를 사용한 경우가 약 1% 높았다. 저자들은 이를 이전 피쳐가 Localized 특징을 더 가지고 있을 것이라는 가설을 세웠다.
- 두번째는 답변을 먼저 예측하고 추론하는 방식(Answer first)과 먼저 추론을 한 후 답변을 예측하는 방식(Reasoning first)을 비교한 것인데, Reasoning first 방식이 수렴은 빨랐으나, 고점은 Answer first가 더 높았다고 설명했다.
- 세번째는 Pre-traning(Stage 1) 단계를 건너뛰면 성능이 약 5% 정도 감소한다는 것을 보여준다.
- 네번째는 Best variant(13B)에 비해 작은 7B 모델의 성능을 평가한 것인데, 약 1% 정도 하락했고 저자는 이에 대해 모델 크기의 중요성을 언급했다.
Conclusion
- 이 논문은 Visual Instruction Tuning의 효과를 입증했다(고 한다.)
- Image-Text pair 데이터로부터 Visual instruction following data를 생성해내는 파이프라인을 제안했다.
728x90
'공부' 카테고리의 다른 글
| [딥러닝 공부] Vision-Language Evaluation Metrics(VLM 벤치마크 평가 지표) (0) | 2025.02.28 |
|---|---|
| [논문 요약/리뷰] ROUGE: A Package for Automatic Evaluation of Summaries (0) | 2025.02.27 |
| [딥러닝 공부] KL Divergence와 Cross Entropy (0) | 2025.01.26 |
| [딥러닝 공부] Bernoulli Distribution, Laplace Distribution(베르누이 분포, 라플라스 분포) (1) | 2025.01.15 |
| [딥러닝 공부] 딥러닝 최적화4 - 하이퍼 파라미터 최적화 (5) | 2025.01.03 |
'공부' Related Articles
more

