
반응형
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 이미지 필터링
- vlm hallucination
- 에지 검출
- 1차 미분 마스크
- dinov2: learning robust visual features without supervision 논문 리뷰
- mobilenetv1
- 딥러닝 엔트로피
- polling-based object probing evaluation
- evaluating object hallucination in large vision-language models 논문
- vlm
- clip adapter
- dinov2: learning robust visual features without supervision
- 논문 요약
- vlm 환각
- clip
- blip-2
- 엔트로피란
- evaluating object hallucination in large vision-language models
- vlm hallucination paper
- 기계학습
- evaluating object hallucination in large vision-language models paper
- object detection
- dinov2 논문 리뷰
- Object detection article
- 객체 검출
- vlm 환각이란
- 원격 학습 안끊기게
- dinov2: learning robust visual features without supervision 논문
- 딥러닝 목적함수
- 논문 리뷰
Archives
- Today
- Total
목록clippo 논문 리뷰 (1)
My Vision, Computer Vision
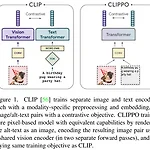 [논문 리뷰/요약] CLIPPO: Image-and-Language Understanding from Pixels Only
[논문 리뷰/요약] CLIPPO: Image-and-Language Understanding from Pixels Only
CLIPPO: Image-and-Language Understanding from Pixels OnlyMultimodal models are becoming increasingly effective, in part due to unified components, such as the Transformer architecture. However, multimodal models still often consist of many task- and modality-specific pieces and training procedures. For example,arxiv.orgProblem대부분의 멀티모달 모델은 모달리티 별로 구성 요소가 다르고, 다른 태스크에 적용하기 위해 그에 맞는 추가적인 학습 절차가 필요..
Paper
2025. 2. 5. 16:22